
Исследователи предлагают легковесную генеративно-состязательную сеть для редактирования изображений по текстовому описанию. Модель принимает на вход изображение и текстовое описание, в соответствии с которым необходимо модифицировать изображение. На выходе модель отдает отредактированное изображение. Нейросеть выдает сравнимые с state-of-the-art моделями результаты при меньшем количестве параметров.
Подробнее про нейросеть
Модель использует дискриминатор на уровне слов в описании. Это позволяет генератору получать более точный фидбек по генерируемым изображениям. Чтобы облегчить обучение, генератор имеет небольшое количество параметров. Несмотря на это, модель корректно фокусируется на визуальных атрибутах изображения и редактировать их, не затрагивая остальную часть изображения, которая не описана в тексте. Дискриминатор также имеет облегченную структуру.
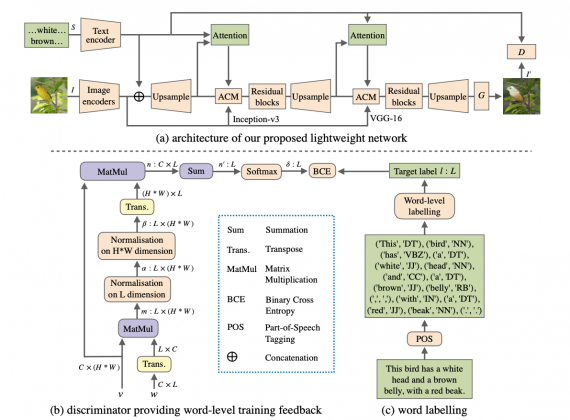
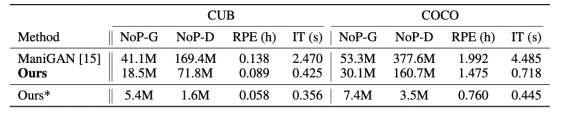
Подробнее архитектура модели и эксперименты по оценке описаны в оригинальной статье.
