Компания OpenAI разработала языковую модель, которая способна решать несколько задач NLP. Изначально исследователи лишь пытались обучить GPT-2 генерировать реалистичное продолжение текста. Результаты настолько впечатляющие, что разработчики решили не выкладывать модель в открытый доступ, дабы избежать появления большого количества фейковых новостей.
Особенности модели
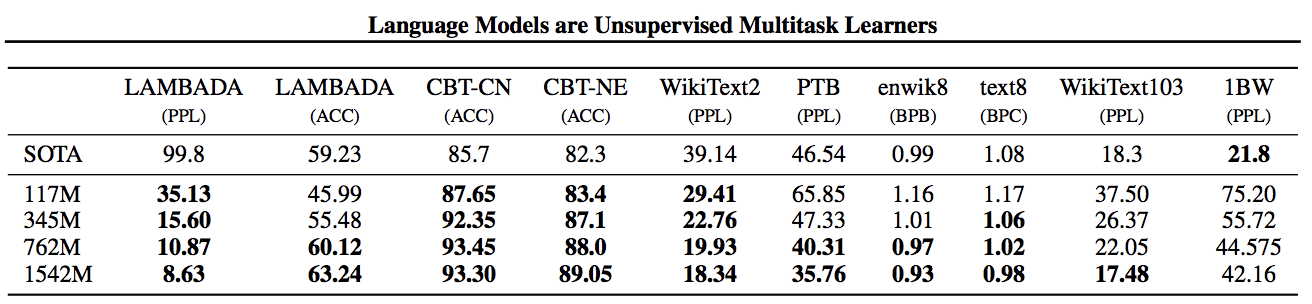
GPT-2 — это большая языковая модель предсказания, созданная на основе простой сети transformer с механизмом внимания. Сеть содержит 1,5 миллиарда параметров. Она обучалась на наборе данных из 8 миллионов веб-страниц весом 40 гигабайт. GPT-2 обучили предсказывать следующее слово в предложении на основе предыдущих.
Ответы на вопросы, понимание смысла текста, обобщение и перевод — этим задачам модель обучилась просто обрабатывая огромные корпуса неразмеченного текста. Когда языковая модель обучается на большом и разнообразном наборе данных, она учится выполнять задачи автоматически. Результаты не такие хорошие, как у алгоритмов, специально обученных под конкретное действие, но нужно учитывать, что все эти действия выполняет одна модель.
GPT-2 создает образцы синтетического текста на основе произвольного предложения. Она адаптируется к стилю и содержанию текста и генерирует реалистичное и последовательное продолжение на заданную тему.
Примеры
Некоторые примеры сгенерированных текстов. Больше примеров можно найти в блоге разработчиков.



Потенциальный вред алгоритма
Исследователи планировали создать языковой алгоритм общего назначения, обученный на огромном количестве текстов из интернета, который мог бы переводить текст, отвечать на вопросы и выполнять другие полезные задачи обработки языка. Но вскоре после начала тестирования в OpenAI стали беспокоиться о возможности использования алгоритма во вред. «Мы начали его тестировать и быстро обнаружили, что он может довольно легко создавать вредоносный контент» — отмечают исследователи.
OpenAI назвали несколько вариантов потенциально опасного использования:
- генерация вводящего в заблуждение новостного контента;
- выдавание себя за других онлайн;
- автоматизация производства оскорбительного и ложного контента в социальных сетях;
- автоматизация создания спама/фишинга.
В результате OpenAI решили не публиковать модель и датасет для обучения в открытом доступе. Однако они выпустили упрощенную версию алгоритма для экспериментов и технический документ.