
Исследователи из OpenAI обучили RL-агентов играть в прятки в командах. По окончании обучения модели агенты самостоятельно выучили такие стратегии, как искать спрятавшихся, строить укрытия и блокировать предметы, которые помогают ищущим искать спрятавшихся.
Описание среды
В среде агенты играют в прятки по командам. Те, кто прячется, (синие) должны избегать поля зрения тех, кто ищет, (красные). Красные, соответственно, получают вознаграждению за то, что находят синих. В среде есть объекты, с которыми могут взаимодействовать игроки, и неподвижные стены, среди которых агенты должны уметь передвигаться. До того как игра начинается, синие агенты получают время на то, чтобы спрятаться.
Возможности агентов в среде
Агенты способны выбирать действия из следующего списка:
- Передвигаться от одной точки в среде к другой и поворачиваться;
- Видеть объекты, которые попадают в их поле зрения;
- Агенты осознают дистанцию до объектов, стен и других агентов;
- Объекты в среде можно хватать и передвигать, если они находятся в поле зрения агента;
- У агентов есть возможность заключать объекты на месте так, что только члены одной команды могут их передвигать
Исследователи не учитывали в модели прямое взаимодействие агентов с объектами в среде. Единственный контроль над агентами осуществлялся в вознаграждении синих за то, что их не нашли, и вознаграждение красных за то, что они нашли синих. Агенты получают вознаграждение за командную игру. Если все синие агенты удачно спрятались, каждый из них получает вознаграждения +1. Если синий агент найден красным, у него отнимается 1 балл. Агенты наказываются, если они отходят далеко от места старта игры.
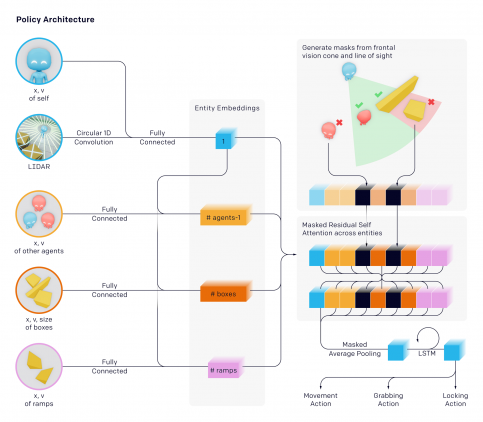
Архитектура модели
Исследователи использовали ту же инфраструктуру и алгоритмы для обучения, что и для OpenAI Five и Dactyl. Однако в этой среде агент принимает решение индивидуально и использует собственные наблюдения и память. Агенты используют entity-centric state-based представление среды. Такое представления мира устойчиво к перестановкам объектов и других агентов.
Каждый объект кодируется и посылается на вход блоку с остаточным механизмом внимания (residual self attention block). Это схоже с тем, как устроены трансформеры, где механизм внимания используется в отношении объектов, а не времени. Объекты, которые не входят в поле зрения агенты, скрываются так, что агент не получает о них никакую информацию.
Стратегии игры, которые выучила модель
Модель выучила стратегии игры для агентов из разных команд. В случае, когда случайным образом выбиралось количество игроков (1-3 на каждую команду), блоков в среде (3-9), количество комнат и дверей, агенты обучились следующим стратегиям:
- 0 игр: агенты двигаются случайно;
- 0–22 миллионов игр: красные обучились искать синих;
- 22–88 миллионов игр: синие обучились строить укрытие, чтобы спрятаться в нем;
- 88–115 миллионов игр: красные научились использовать трамплины, чтобы перепрыгивать препятствия;
- 115–388 миллионов игр: синие научились блокировать трамплины, чтобы помешать красным их использовать;
- 388–458 миллионов игр: красные научились забрасывать коробку в укрытие синих;
- 458–481 миллионов игр: синие научились блокировать и трамплины, и коробки, чтобы остановить красных
Это исследование показывает, что агенты в последствии могут обучаться более комплексным стратегиям самостоятельно без прямого указания со стороны системы вознаграждения
Видеодемонстрация работы нейросети доступна ниже.






как поиграть в это