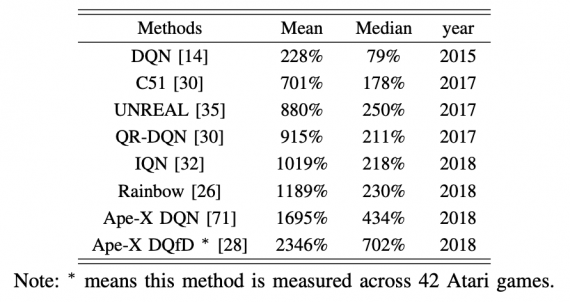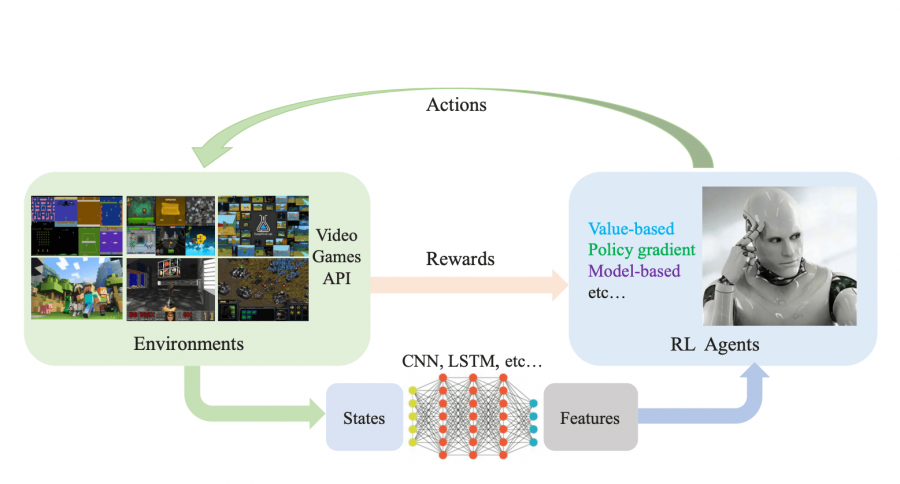
В глубоком обучении с подкреплением (DRL) агенты принимают на вход многомерные данные и используют нейросетевые политики, чтобы совершать действия. При таком устройстве обучения политика, в соответствии с которой выбираются действия, оптимизируется так, чтобы максимизировать награду. В статье обозревается текущий прогресс в применении DRL-алгоритмов к видео-играм. Исследователи сравнили структуру и характеристики value-based, policy gradient и model-based алгоритмов.
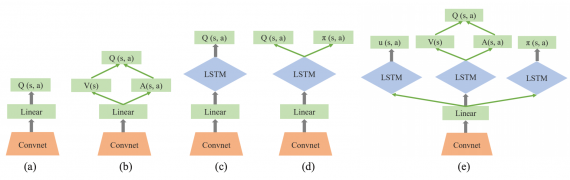
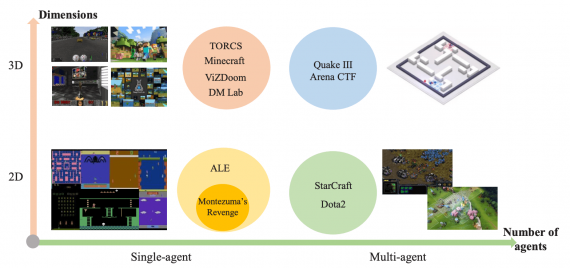
Ограничения в применении DRL для видео-игр
Несмотря на то, что DRL-алгоритмы в каких-то играх превосходят человека, у разных методов обучения алгоритмов есть ограничения.
Exploration-exploitation
Exploration позволяет получить информацию о среде, в то время как exploitation — это способ выучить политику, которая приносит больше всего награды. Компромисс между exploration и exploitation — это одна из основных дилемм в обучении с подкреплением.
Эффективность выборки
DRL алгоритмы обычно требует миллионы итераций, чтобы научиться решать задачу на уровне человека. При этом люди быстро выучивают стратегии, которые приносят им большую награду. Большинство DRL алгоритмов неэффективно используют данные. Эта проблема особенно актуально для комплексных сред с высокой размерностью.
Обобщение и перенос знаний
Возможность переносить знания между множеством сред считается необходимым условием умных агентов. Для того, чтобы агенты могли обобщать знания на несколько сред, используются multi-task learning и policy distillation.
Мультиагентное обучение
Мультиагентное обучение используется для коллаборативных видео-игр, где пользователи группируются в команды и выступает против друг друга. В такой постановке задачи сложностями являются высокая размерность пространства возможных действий, взаимодействие между агентами и определение функции награды.