Исследователи из DeepMind проверили, как предобученный на данных одного языка трансформер переносится на другой язык. Исследователи публикуют новый датасет с кросс-языковыми парами вопросов и ответов (XQuAD). Датасет состоит из 240 параграфов и 1190 пар вопросов и ответов из SQuAD v1.1. Данные перевели на 10 языков с помощью профессиональных переводчиков.
Мультиязычный BERT (mBERT) является state-of-the-art мультиязыковой моделью. В академической среде считается, что успех mBERT обуславливается тремя факторами:
- Совместные слова на разных языках в словаре выступают как якоря;
- Объединенное обучение модели на данных разных языков;
- Глубокие кросс-языковые представления, которые обобщаются на другие языки и задачи
Исследователи эмпирически тестируют эту гипотезу с помощью альтернативного подхода, который не учитывает эти три допущения. Сначала обучается моноязычный трансформер с помощью masked языковой модели (MLM). Чтобы перенести языковую модель на новый язык, обучается матрица эмбеддингов из MLM на новом языке. Параметры остальных слоев остаются теми же. Этот подход дополнительно выучивает только новые лексические параметры. Преимущество метода в том, что он не требует совместного словаря или объединенного обучения. По результатам экспериментов на задачах XNLI, MLDoc и PAWS-X, метод показывает результаты, сравнимые с предобученными мультиязычными моделями.
XQuAD может выступать как стандартная задача для оценки кросс-языковых моделей. Доступ к датасету можно получить по ссылке. Тестирование моделей на XQuAD показало, что подход с моноязычным переносом может быть конкурировать с моделями, в которых данных на разных языках обучались совместно. Конкурентоспособность обеспеспечивают модули-адаптеры, с помощью которым модель выучивает характерные для нового языка трансформации.
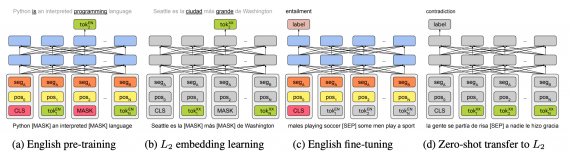
Как перенести модель на одном языке на другой язык
Процесс переноса моноязычной языковой модели на новый язык состоит из четырех шагов:
- Сначала предобучается трансформер (в данном случае BERT) на данных английского языка;
- Параметры трансформера остаются неизменными и отдельно обучаются новые эмбеддинги токенов для второго языка с использованием той же целевой функции;
- Параметры модели оптимизируются для английского языка, при этом эмбеддинги нового языка не изменяются;
- Zero-shot замена эмбеддингов токенов в модели с английских на эмбеддинги нового языка