MLQA — это датасет для оценки моделей на задаче генерации экстрактивных ответов на вопросы (QA). Датасет был собран для того, чтобы способствовать улучшению и расширению задачи генерации ответов на большее количество языков. Разработчики MLQA отдельно выделяют необходимость в zero-shot подходах к мультиязычному QA.
MLQA состоит из 12 тысяч пар вопросов и текстов с ответами на английском языке. Дополнительно в датасете есть от 5 тысяч пар для каждого из 6 языков: арабский, немецкий, хинди, испанскией, вьетнамский и упрощенный китайский. Исследователи использовали инструмент LASER от FAIR для фильтрации документов для датасета. LASER — это библиотека для переноса NLP-моделей на другие языки.
Из-за того, что в MLQA содержатся параллельные данные, исследователи могут использовать данные для сравнения качества модели, которую перенесли с одного языка на другой. Параллельность данных предполагает, что аналог каждого вопроса на одном языке присутствует на других языках. Кроме этого, с помощью MLQA возможно оценивать мультиязычные пары вопроса и ответа. К примеру, когда вопрос на вьетнамском, а ответ на хинди.
Исследователи проверили работу state-of-the-art межъязыковых представлений на MLQA. Оказалось, что представления на тестовых языках отличаются от представлений на языке, на котором обучалась модель. Это ограничение, которое имеют текущие state-of-the-art подходы. Кроме датасета, исследователи опубликовали стандартные модели и результаты своих сравнений.
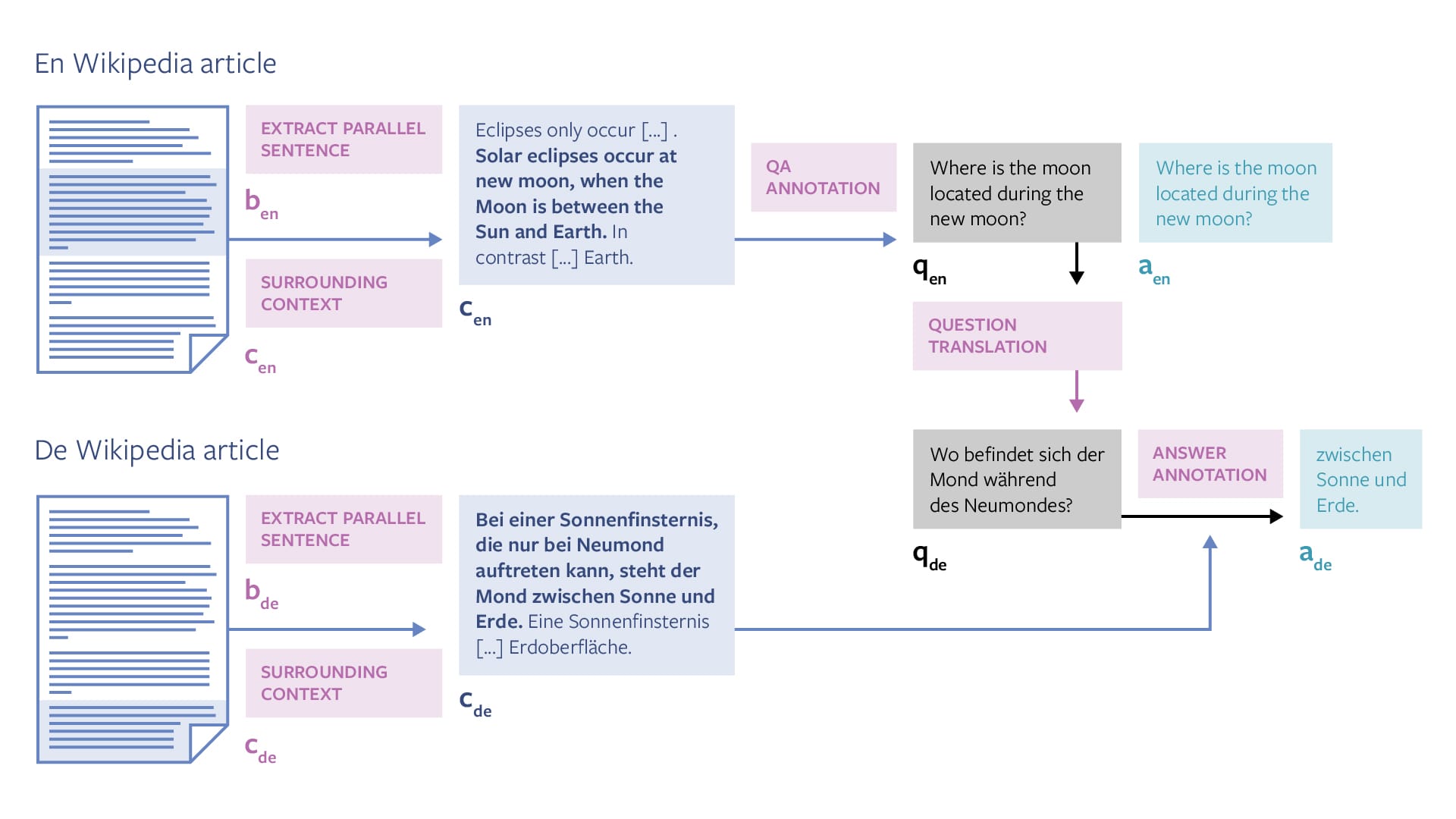
Пайплайн разметки данных состоял из следующих шагов:
- Сначала были извлечены параллельные предложения из статей одной темы на Википедии;
- Аннотаторы формулировали вопросы к предложениям;
- Вопросы на английском переводились на оставшиеся языки с помощью профессиональных переводчиков;
- Затем в тексте предложений на английском аннотаторы размечали ответы на вопросы



