Исследователи из FAIR разработали модель, которая обучается взаимодействовать с объектами по видеозаписям. Модель обучалась на видео обыденных действий людей. По результатам экспериментов, модель либо повторяла, либо обходила state-of-the-art алгоритмы. Преимущество модели над конкурирующими подходами заключается в значительно меньшем объеме необходимых размеченных данных для обучения.
Предыдущие подходы опираются на вручную размеченные примеры различных действий. Предложенная модель учится на видеозаписях того, как люди взаимодействовали с объектами. Эти видеозаписи содержат в себе информацию, которая необходима системе для успешного взаимодействия с предметами. Подход позволяет улучшает способность модели распознавать ранее неизвестные объекты и выучивать, как их использовать.
Как это работает
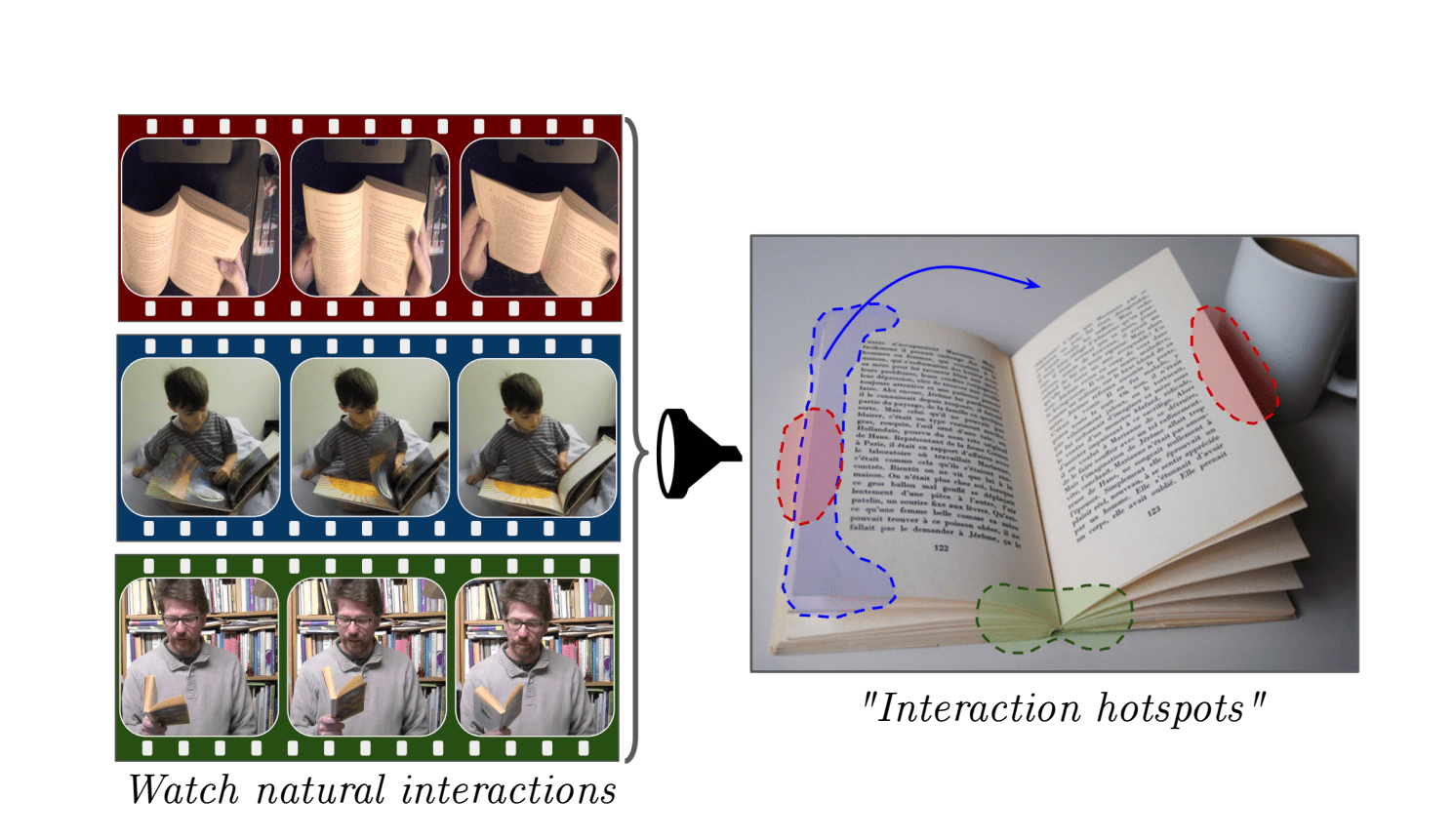
Цель исследования заключалась в том, чтобы обучить модель понимать точки взаимодействия с предметом. Под точками взаимодействия понимаются части предмета, которые лучше всего объясняют способ взаимодействия человека с предметом.
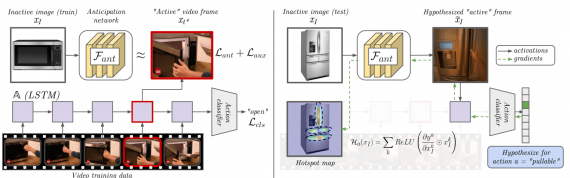
Процесс обучения модели начинается с классификатора действий на видеозаписи. Классификатор учится распознавать различные виды действий на видео. Итоговая модель затем учится восстанавливать финальное состояние объекта после взаимодействия. После этого модель генерирует карту объекта с размеченными точками взаимодействия. Подход работает для тех объектов, которые не присутствовали в обучающей выборке. Точки взаимодействия объекта раскрывают функциональные характеристики объекта.
Проверка работы модели
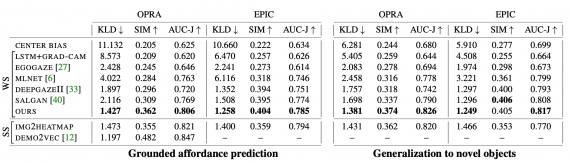
Для тестирования подходов использовались датасеты OPRA и EPIC-Kitchens. Предложенная модель сравнивалась с следующими подходами: CENTER BIAS, LSTM+GRAD-CAM, SALIENCY, DEMO2VEC и IMG2HEATMAP.