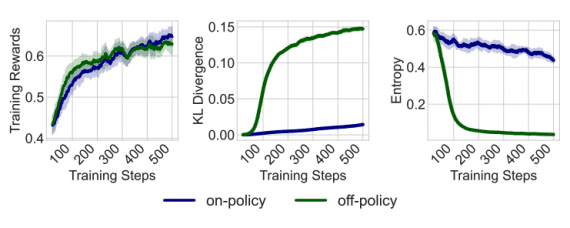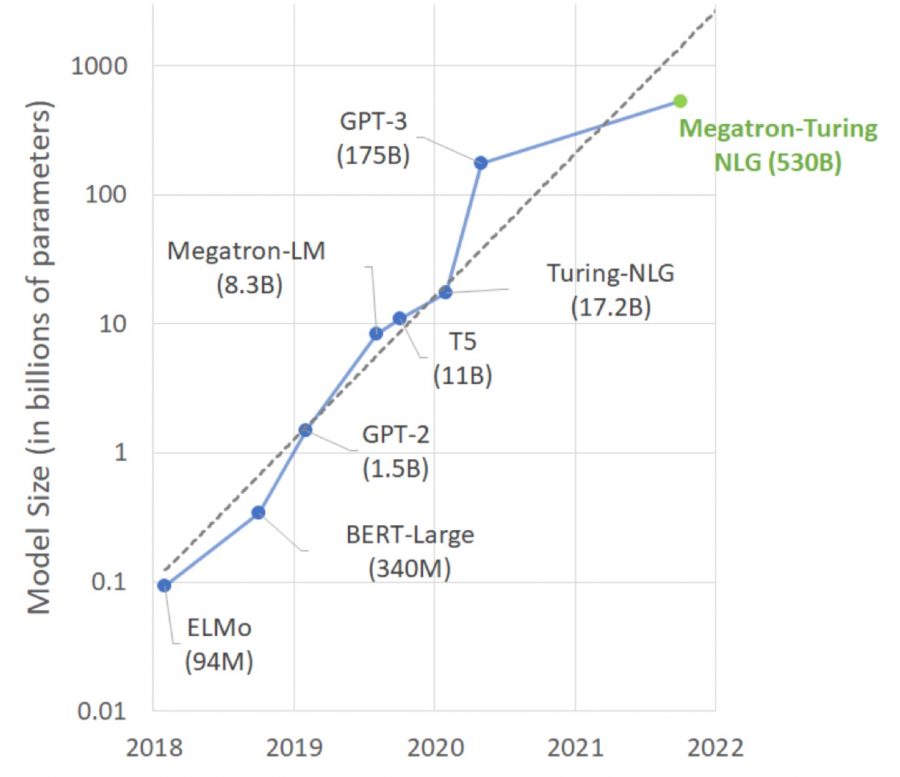
Языковая модель MT-NLG, разработанная Microsoft и NVIDIA, обладает 530 миллиардами параметров, что в 3 раза больше, чем у GPT-3. MT-NLG состоит из 105 слоев и превосходит все существующие модели обработки естественного языка.
Обучение модели выполнялось на суперкомпьютере NVIDIA Selene, состоящем из 560 серверов DGX, в каждом из которых размещено по 8 графических процессоров A100 с 432 тензорными ядрами и 80 Гб оперативной памяти.
Обучающий датасет The Pile имел размер 1.5 Тб и состоял из нескольких сотен млрд единиц текстовых данных, взятых из 11 баз данных, включая Википедию и PubMed.
MT-NLG продемонстрировала рекордно высокую точность в следующих тестах: предсказание завершения текста по смыслу, понимание прочитанного, генерация логических выводов, создание заключений на естественном языке, различение смысла слов с несколькими значениями.
Любопытно, что MT-NLG, согласно заявлениям разработчиков, продемонстрировала понимание простейшей математики. Также разработчики модели предупредили, что она обладает предвзятостью, свойственной всем языковым моделям.