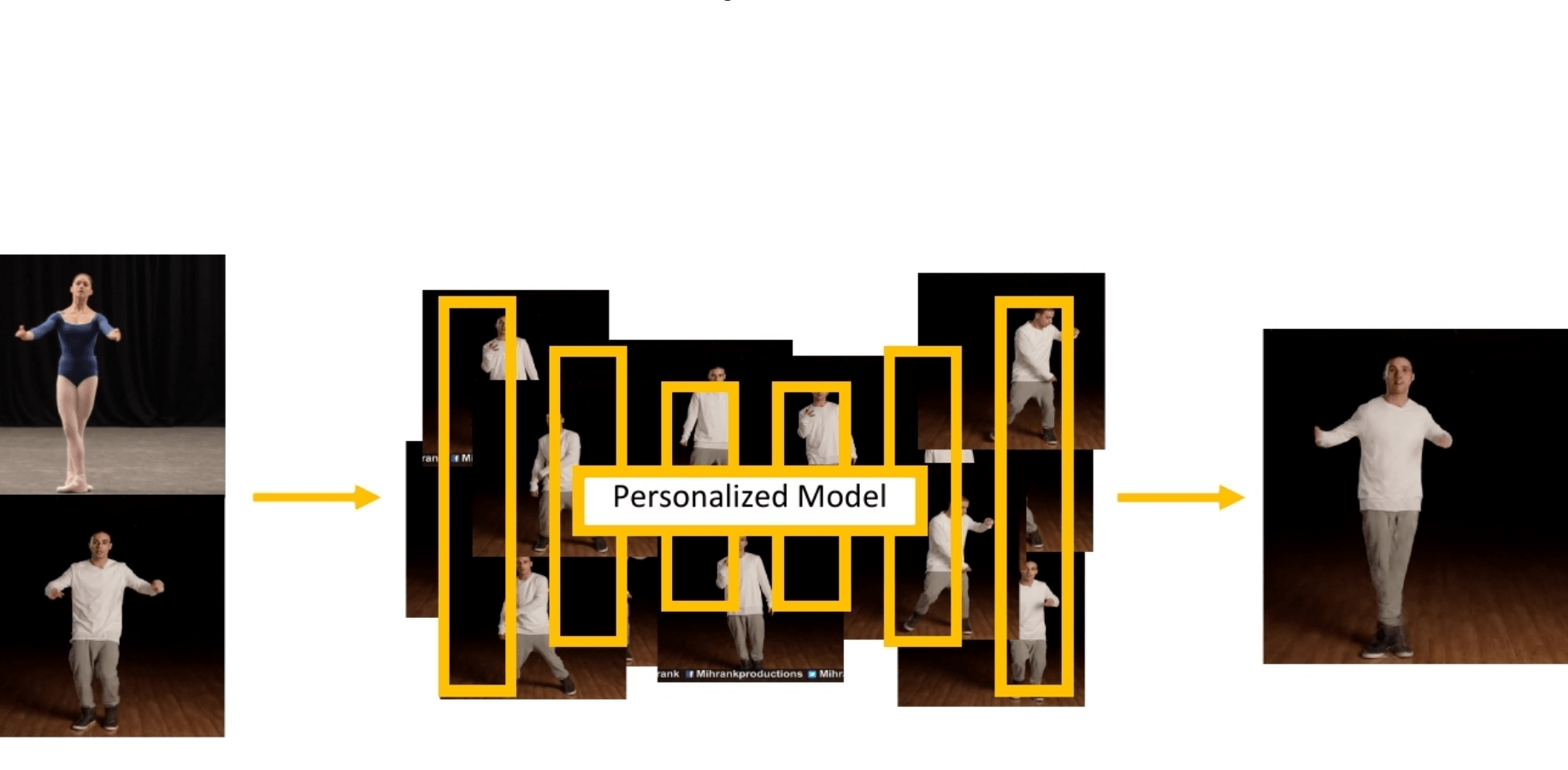
Исследователи из Adobe Research обучили нейросеть, которая переносит движения тела одного человека на другого с помощью видеозаписей танцев. Модель состоит из двух генеративных нейросетей: сеть, которая синтезирует реалистичные кадры с целевой персоной в новой позе; сеть, которая генерирует задний фон, тени и отражения. Исследователи тестируют подход с помощью качественных и количественных метрик.
Предложенный подход призван воссоздавать человеческие движения. Модель обучалась на одной видеозаписи, которая длится несколько минут, с целевой персоной. Затем модель способна переносить любое движение с референс-видеозаписи на целевую персону. При этом внешность целевой персоны сохраняется. Предыдущие работы исследуют перенос позы человека либо в обобщенной формулировке (модели обучаются на разных людях и сценах), либо обучают модель по видеозаписям одной персоны. Подход, который предлагают исследователи, исследует персонализированный перенос движений по видеозаписям из YouTube. С такими данными, которые содержат в себе разные варианты сцен и не были записаны исследователями, модели необходимо уметь масштабироваться на ранее неизвестные позы.
Архитектура нейросети
Модель переноса позы состоит из двух этапов:
- Нейросеть для синтеза позы принимает на вход трансформированные части тела целевой персоны и генерирует изображение целевой персоны на зеленом фоне;
- Нейросеть для генерации заднего фона принимает на вход фон референс-видеозаписи и сгенерированное изображение целевой персоны. На выходе модель отдает итоговое изображение целевой персоны
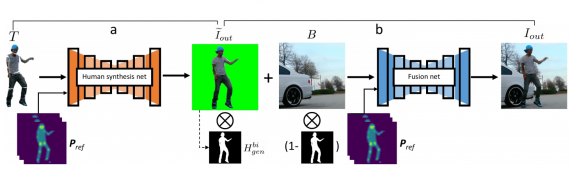
Чтобы генерировать кадры в высоком разрешении, исследователи используют фреймворк, который базируется на pix2pixHD. Нейросеть для генерации позы человека и нейросеть для генерации финального изображения имеют одну и ту же архитектуру и целевые функции.
Данные
Исследователи тестируют модели на данных YouTube: 8 видео длительностью от 4 до 12 минут. Видеозаписи содержат в себе обучающие уроки по танцам. Для каждого видео обучается отдельная модель. Восемь людей на этих видеозаписях — целевые персоны. Дополнительно исследователи собирают референс-видеозаписи: 16 коротких клипов с танцами, которые отличаются от тех, что были в обучающей выборке.
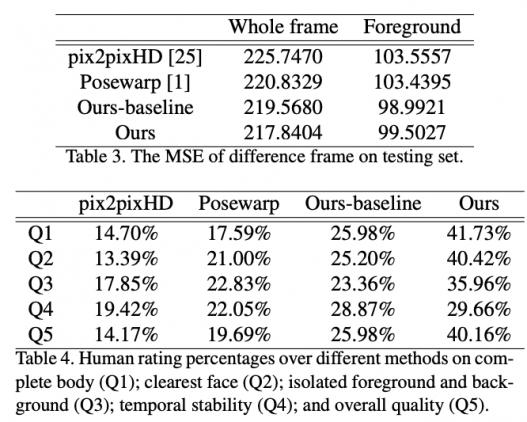
Тестирование работы модели
Предложенный подход сравнивают с тремя базовыми моделями: pix2pixHD, Posewarp, Ours-baseline. Ours-baseline — это та же двухступенчатая модель, но обученная без учителя. По результатам опроса, видно, что предложенная модель выдает более реалистичные результаты.