PYTHIA — это нейросетевая модель от DeepMind для восстановления текстовых данных. Разработчики протестировали модель на задаче восстановления текстов на древнегреческом. По результатам, модель совершила на 27.2% меньше ошибок, чем профессиональные эпиграфисты. PYTHIA может быть масштабирована на любой другой язык.
Древняя история опирается на такие дисциплины, как эпиграфика. Эпиграфика — это исследование древних надписей и их классификация в соответствии с временным и культурным контекстом. Однако надписи часто повреждены, из-за чего теряется часть текста. Задача эпиграфистов — восстановить тексты от повреждений. PYTHIA нужна для автоматизации процесса восстановления утерянных символов в тексте.
Архитектура модели адаптирована так, чтобы запоминать длительные последовательности и учитывать контекст. Чтобы обучить модель, разработчики использовали данные из корпуса надписей на древнегреческом PHI. Изображения надписей были преобразованы в текст.
Основная проблема в дополнении текстов на древнегреческом — множество возможных решений. PYTHIA принимает на вход последовательность из символов, — неполный текст. На выходе модель отдает проранжированный по вероятности список возможных дополнений текста.
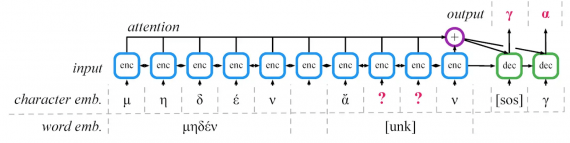
Архитектура работает как на уровне символов, так и на уровне слов. Такое решение позволяет модели запоминать длительную информацию о контексте и работать с неполными представлениями слов.
Оценка модели
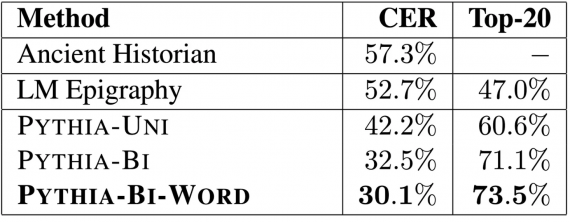
Чтобы обучить модель, использовался датасет с текстами на древнегреческом PHI-ML. Предсказания модели сравнивались с предсказаниями PhD студентов Оксфорда, которые занимаются изучением древней истории. На датасете модель совершала ошибку в 30.1% случаев, в то время как эксперты по эпиграфике — в 57.3% случаев. В 73.5% случаев реальная последовательность была в топ-20 наиболее вероятных предсказаний модели. Ошибка считалась на уровне символов.