Facebook AI опубликовали модель для классификации видео и изображений с минимальным количеством необходимой разметки. В FAIR эта задача называется semi-weak supervision, потому что объединяет в себе преимущества semi-supervised и weakly supervised обучения. Semi-weakly supervised обучение сокращает разницу в точности между state-of-the-art моделями и моделями в бизнесе. Подход позволяет создавать модели, которое готовы для запуска в продукте и при этом незначительно теряют в точности по сравнению с state-of-the-art.
Высококачественная классификация видео и изображений находит применение для таких задач, как распознавание вредоносного контента и рекомендация рекламы.
Если для целевого класса нет weakly supervised датасетов, метод может использовать не размеченные данные для обучения. Под weakly supervised наборами данных понимаются, к примеру, публичные фотографии с хэштегами.
Предложенный semi-weakly supervised фреймфорк достигает state-of-the-art результатов на базовых задачах по классификации изображений и видеозаписей. На ImageNet модель с ResNet-50 в основании получила точность в 82.1%. На задаче Kinetics точность модели составила 74.2%. Это на 2.7% выше, чем результаты предыдущих схожих weakly supervised моделей.
Что внутри модели
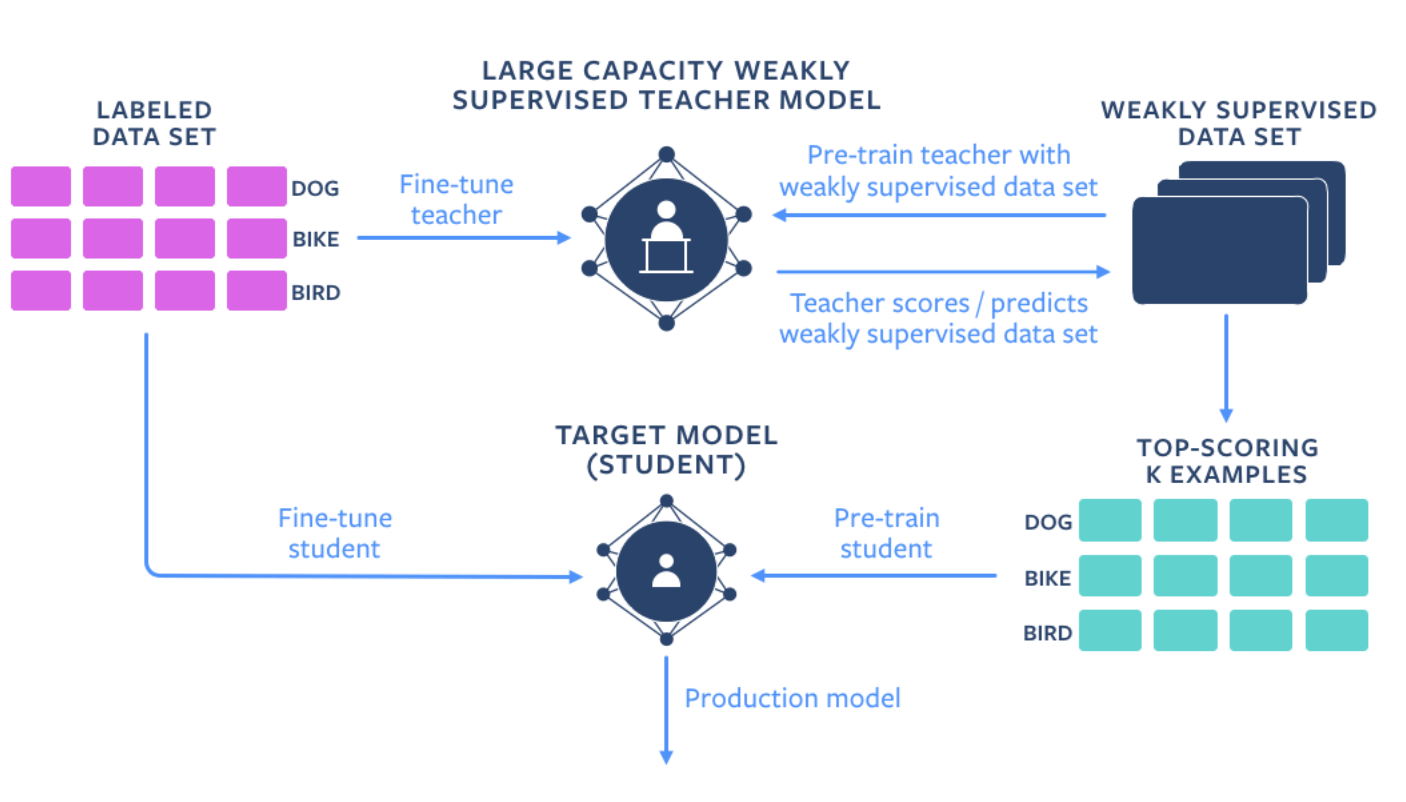
Semi-supervised позволяет разные способы уменьшить количество размеченных данных для обучения модели. Целевую модель обучают с использованием большого количество не размеченных данных вместе с сетом размеченных примеров.
Сначала обучается модель “учителя” на всех доступных размеченных данных. Модель учителя предсказывает метки классов и вероятности для всех не размеченных примеров. Эти примеры ранжируются для каждого класса. Наиболее вероятные примеры каждого класса используются для предобучения классификтора “студента”. В итоге качество модели студента улучшают с помощью размеченных данных. Целевая модель учится на размеченных данных от учителя и на не размеченных данных во время предобучения.
Предложенный фреймворк для обучения выдает модели с более высокой точностью в сравнении с форматом обучения с учителем.