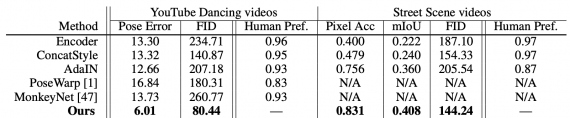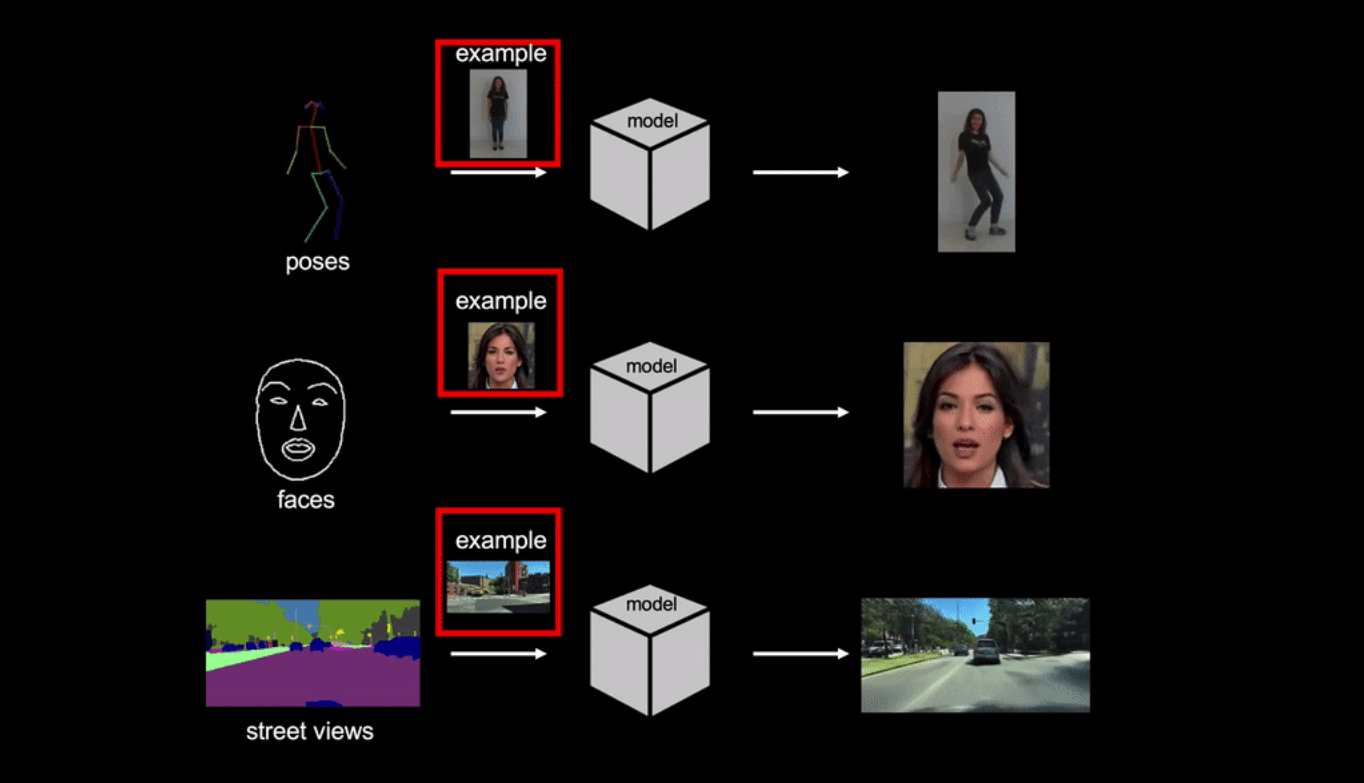
Few-shot vid2vid — это нейросеть, которая генерирует реалистичную видеозапись по семантической видеозаписи и фотографии с примером. В качестве семантических видео используются видео с позами человека, c лицевыми выражениями и с разметкой уличных видов. На задаче генерации видео танцующих людей модель как минимум в 2 раза точнее state-of-the-art подходов.
Задача генерации видеозаписи по видеозаписи заключается в том, чтобы конвертировать входное семантическое видео в выходное фотореалистичное видео. State-of-the-art подходы к решению этой задачи имеют два ограничения. Первое — необходимость в большом количестве данных для обучения. Второе — существующие модели обладают низкой генерализующей способностью. Pose-to-human vid2vid модель может исключительно генерировать видео с позами для людей из обучающей выборки. Модель не обобщается на других людей, которые не присутствуют в обучающей выборке. Чтобы избавиться от этих ограничений, исследователи предлагают few-shot vid2vid фреймворк. Модель учится генерировать видео ранее неизвестных объектов или сцен на основе нескольких изображений целевого объекта на тесте. Чтобы обучить модель генерировать видео few-shot, используется механизм внимания.
Отличия few-shot vid2vid от предыдущих моделей
Существующие vid2vid методы не генерализуются на объекты, которые не присутствовали в обучающей выборке. Обученная модель генерирует схожие видео с теми, что были в обучающем наборе данных. Few-shot vid2vid генерирует видео новых людей с помощью фотографий-примеров, которые подаются на вход на этапе тестирования вместе с семантическим видео. Few-shot vid2vid модель базируется на условной GAN.
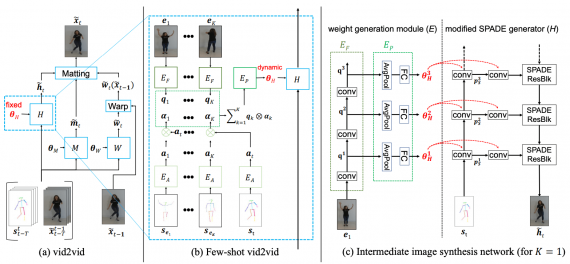
Few-shot vid2vid фреймворк состоит из следующих компонентов:
- Модуль для генерации весов нейросети E: соотносит изображения-примеры с часть весами нейросети для генерации видео;
- Модуль E состоит из 3 подсетей: EF, EP, EA;
- EF извлекает признаки из изображений-примеров;
- Если на вход нейросети поступило более одного изображения-примера, EA комбинирует признаки разных изображений с помощью карт внимания;
- Итоговое представление примеров поступает на вход EP, чтобы сгенерировать веса для сети, которая генерирует изображения
Проверка работы модели
Чтобы проверить работу нейросети, исследователи использовали 3 датасета: видеозаписи танцующих людей с YouTube, видеозаписи уличных видов в Германии, Нью-Йорке и Бостоне и видеозаписи говорящих людей из датасета FaceForensics. Ниже видно, что few-shot vid2vid значительно обходит базовые модели по метрикам FID и точности.