NVIDIA опубликовали нейросетевой подход для генерации видеозаписей. Сцены на сгенерированных видеозаписях консистентны во времени и с разных точек обзора.
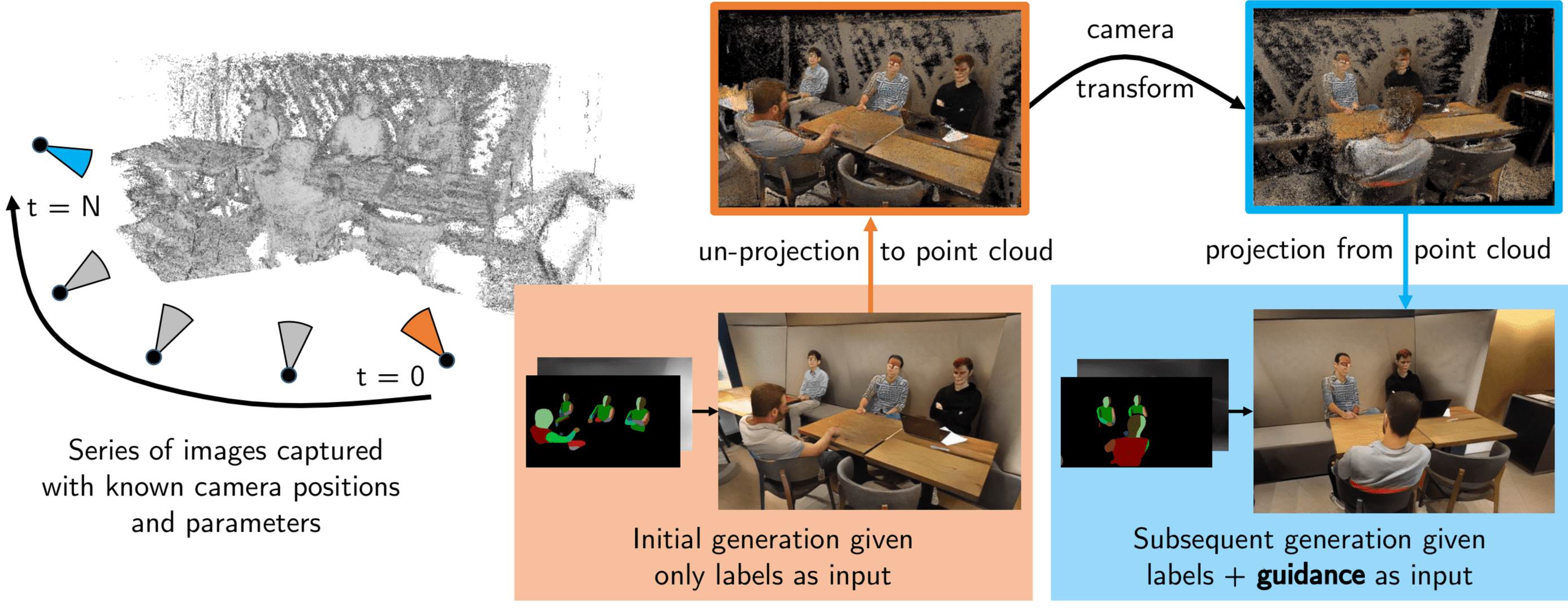
Предыдущие модели для генерации видео не обеспечивали консистентность сцены. С каждым движением камеры предложенный подход раскрашивает новые участки 3D облака точек сцены. При этом модель учитывает ранее раскрашенные участки сцены. Нейросеть учится рендерить изображения на основе 2D проекций облака слов. Сгенерированные видеозаписи семантически последовательны. Кроме того, модель устойчива к некорректным и неполным облакам слов. Предложенный подход сокращает разрыв между классическим рендерингом и нейронным рендерингом.
Ограничения прошлых подходов
Существующие подходы к генерации видеозаписей (vid2vid) обладают следующими недостатками:
- Видео, которые генерирует модель, непоследовательны для длинных временных промежутков. Например, вид сцены с одного и того же ракурса на разных временных отметках может отличаться;
- Отсутствие кратковременной консистентности на сгенерированных видео. Например, отдельные объекты сцены на видеозаписи могут мерцать
Что внутри модели
Чтобы генерировать консистентную видеозапись, модель должна иметь представление о 3D структуре сцены. Для этого исследователи предлагают подавать модели на вход 3D изображения сцены, помимо семантической сегментации и карт глубины сцены. Ниже пример того, что модель принимает на вход и отдает на выходе.
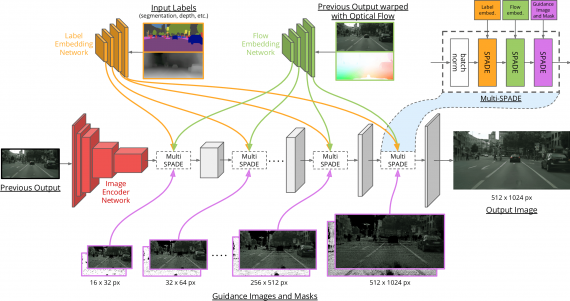
В качестве архитектуры нейросети исследователи выбрали генеративно-состязательную нейросеть. Основным компонентом генератора является блок Multi-SPADE, который состоит из SPADE нескольких слоев. Каждый SPADE слой принимает на вход карту пространства: семантическую сегментацию, выход предыдущего слоя в виде оптического потока или 3D изображение сцены. Затем внутри слоя входная карта влияет на трансформацию карт признаков. Такая архитектура позволяет модели генерировать реалистичные и последовательные видеозаписи.
Ниже пример сгенерированного нейросетью видео.



