Разработчики OpenAI представили исследование, которое показывает, что можно определить идеальный размер пакета данных для обучения алгоритмов, основываясь на данных шкалы градиентного шума. Метод позволит сократить время и стоимость обучения.
В последние несколько лет исследователи добились успеха в ускорении обучения нейронных сетей благодаря параллельному обучению — распределению больших пакетов данных по многим машинам.
Количество данных для обучения называется «batch size» (размер пакета). Ученые успешно используют батчи размером в десятки тысяч изображений или текстов в задачах классификации и языкового моделирования, и миллионы игр для агентов, которые играют в Dota 2.
Большие пакеты обучающих данных позволяют эффективно использовать растущую мощность вычислений для обучения одной модели. Тем не менее, слишком большой размер пакета уменьшает полезность параллельного обучения.
Паттерны на шкале градиентного шума
Open AI обнаружили, что шкала градиентного шума (статистика, которая количественно оценивает отношение сигнал/шум), может помочь предсказать идеальный batch size.
Они протестировали этот прогноз для разных задач машинного обучения, включая распознавание изображений, языковое моделирование, игры Atari и Dota. Были выполнены тренировочные заезды с широким диапазоном размеров пакетов данных для всех задач (скорость обучения была настроена отдельно для каждой). После этого разработчики сравнили ускорения обучения с тем, что должно произойти на шкале градиентного шума.
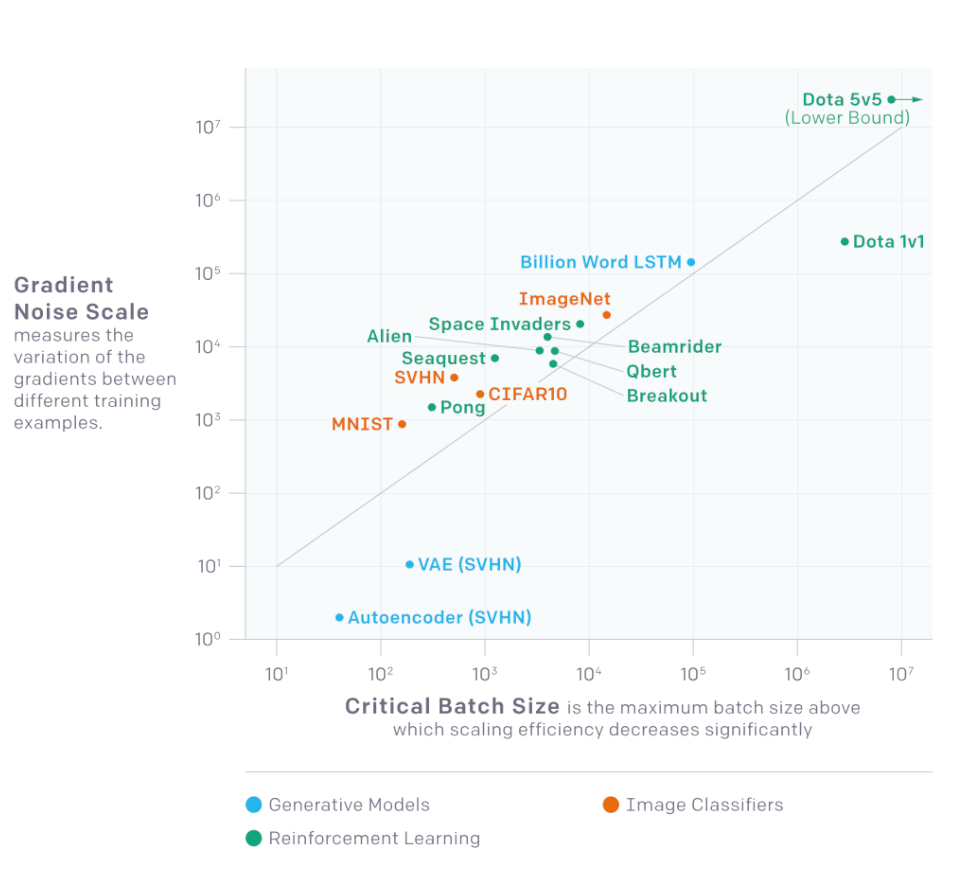
Эвристически шкала шума показывает изменение в данных, видимое моделью на данном этапе обучения. Когда шумов мало, изучение большого количества данных параллельно быстро становится избыточным. Когда шум большой, есть смысл обучаться на огромных пакетах данных.
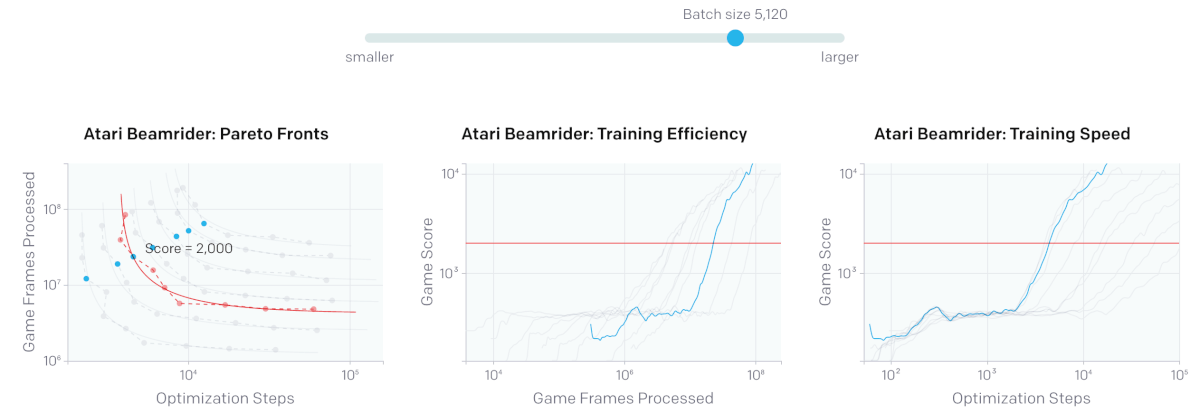
Шум увеличивается, в то время как функция потерь уменьшается на протяжении процесса обучения и зависит от размера модели и, по большей части, ее производительности.
При небольших batch size (например, 10 игр) удвоение батча позволяет обучаться в два раза быстрее без дополнительных вычислений. При слишком больших размерах обучающего пакета параллельные вычисления не приводят к ускорению обучения.
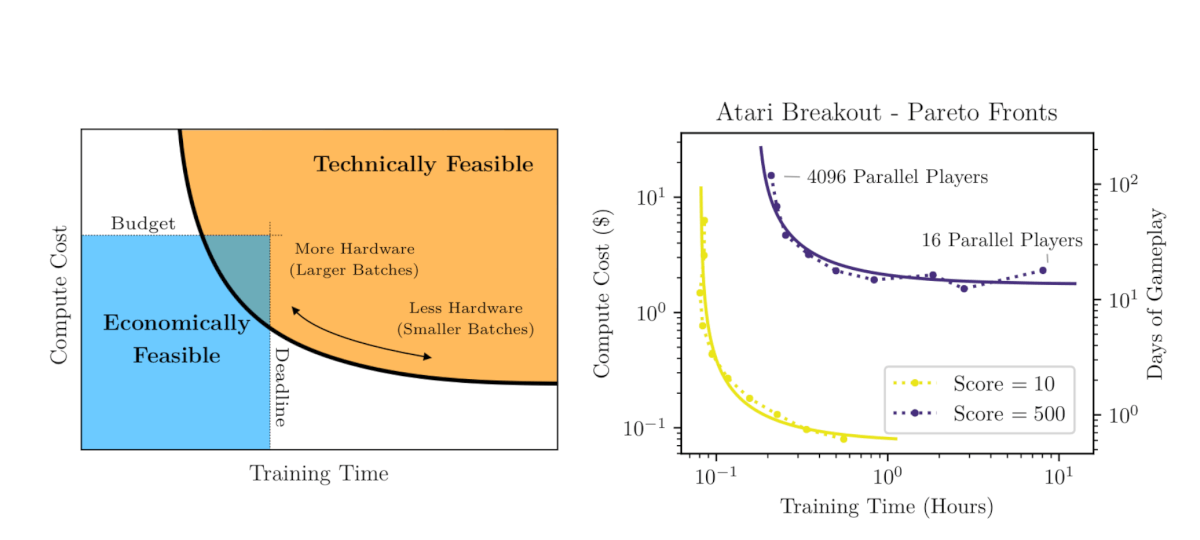
Поскольку большие batch size часто требуют тщательной и дорогой настройки или специальных графиков скорости обучения, чтобы быть эффективными, знание верхнего предела размера позволит обучать модели дешевле и быстрее. Отслеживание изменений на шкале шума позволит вычислить оптимальный batch size и рассчитать компромисс между эффективностью и скоростью обучения.