Исследователи из OpenAI обучили GPT-2 модель дополнять и генерировать изображения. Обученная iGPT обходит state-of-the-art подходы в задаче классификации изображений. Несмотря на более высокие скоры по сравнению со сверточными моделями, обучение iGPT более ресурсоемкое. При этом модель не требует изменений в архитектуре для использования в других задачах.
Transfer learning для задач компьютерного зрения
Обучение без учителя и self-supervised обучение — это одна из открытых задач в машинном обучении. Последние исследования показывали успех моделей, основанных на Transformer, для задач обработки естественного языка. Модели, как BERT, GPT-2, RoBERTa, T5, и их вариации являются state-of-the-art в большинстве задач NLP. Однако пока Transformer архитектуре не удавалось удачно применить для задач обработки изображений.
Transformer модели, как BERT и GPT-2, не зависят от области задачи. Это значит, что модели можно использовать для решения широкого спектра задач без значительных архитектурных изменений. Изначально модели обрабатывали одномерные последовательности.
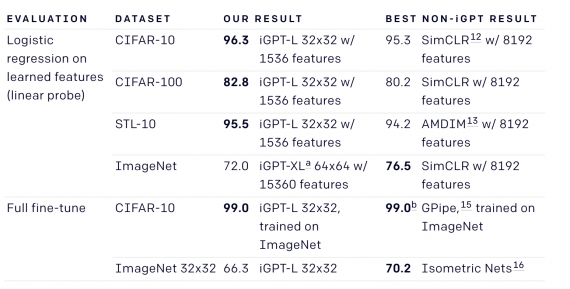
GPT-2, обученная на последовательностях пикселей, способна понимать такие характеристики двумерного изображения, как наличие объекта и его категория. Веса из модели позволяет достичь state-of-the-art результатов на задаче классификации изображений. Исследователи тестировали iGPT на CIFAR-10, STL-10 и ImageNet. Архитектура iGPT при этом полностью совпадает с GPT-2.