В последних исследованиях нейросети для геймдева используются для следующих задач:
- генерация уровней
- обучение агентов играть в видеоигры
- дизайн видеоигр
- тестирование игр
Модели для генерации уровней
Последние исследования чаще используют для генерации уровней архитектуру генеративно-состязательных сетей. Ниже — обзор последних работ со ссылками на открытые реализации, если есть.
Исходный код: https://github.com/schrum2/GameGAN
Обзор
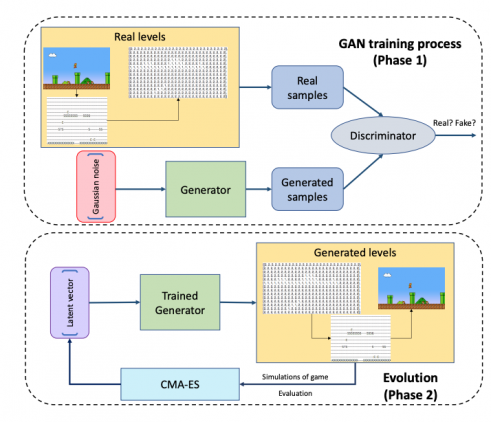
GameGAN — это GAN модель, которую обучили визуально симулировать игровой движок для игры Pac-Man. Модель обучали на данных взаимодействия игрока с игровой средой. Нейросеть рендерит следующий экран на основе того, какую клавишу нажал игрок. Подход отличается от предыдущих тем, что в gameGAN есть модуль памяти, который основывается на внутренней карте среды. Это позволяет агенту вернуться к локациям, которые он ранее посетил. При этом модель устойчива к генерации артефактов. Кроме того, gameGAN может отделять статичные и динамические компоненты на изображении. Поэтому модель можно использовать для задач, когда нужно перенести динамические объекты на новый статичный фон.
Детали архитектуры
GameGAN состоит трех модулей:
- Динамический движок, который хранит переменную внутреннего состояния, которая рекуррентно обновляется;
- Модуль памяти используется для того, что бы запомнить то, что модель сгенерировала ранее. Это актуально для сред, которые требуют долгосрочную консистентность;
- Движок для рендеринга используется для декодирования итогового изображения на каждом таймстемпе
Все модули — это нейросетевые модели, которые обучаются end-to-end.
Результаты
GameGAN выучивается разделять динамические компоненты от статических. Распознанные динамические объекты можно помещать на другой статичный фон. Тестировали модель в 100 средах. Для Pacman предложенная модель с модулем памяти (GameGAN-M) выдает результаты лучше, чем стандартная GameGAN и WorldModel.
Исходный код: N/A
Обзор
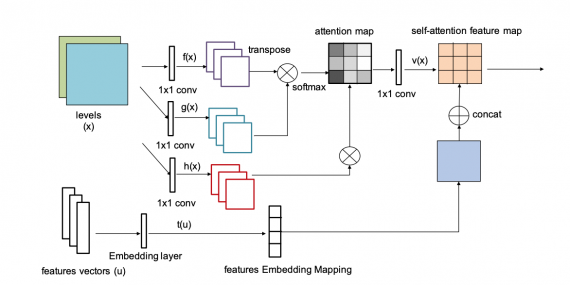
Conditional Embedding Self-Attention Generative Adversarial Network (CESAGAN) — это модифицированная GAN модель с self-attention механизмом, которая адаптирована для задачи генерации уровней.
Детали архитектуры
В CESAGAN есть вектор признаков, который добавляется к входным данным. Вектор позволяет модели выучивать глобальные связи между объектами в игре и подсчитывать объекты. Кроме архитектуры модели, исследователи предлагают механизм обучения с бутстрэппингом. Такой механизм позволяет добавлять корректные сгенерированные уровни в обучающую выборку. Это позволяет сократить требуемое количество данных для обучения модели.
Результаты
Для оценки работы модели исследователи использовали игру Zelda из среды GVGAI. Модель сравнивали со стандартной GAN (Volz et al. (2018)). Предложенная нейросеть генерирует большее число корректных уровней (уровней, в которые можно играть) и меньше дубликатов в сравнении со стандартной моделью.
Исходный код: реализация модели доступна в открытом репозитории MarioGAN
Обзор
GAN обучили генерировать отдельные комнаты в игре The Legend of Zelda. Комнаты могут быть объединены в крепость с помощью генеративной графовой грамматики. 2D планировка комнат частично основывается на данных из графа.
Детали архитектуры
Архитектуру GAN использовали ту же, что и в MarioGAN. Единственное отличие — изменение размера выходного слоя и уменьшенный размер скрытого вектора.
Результаты
Предложенный подход (использовать графовую грамматику и GAN) сравнили с использованием только графовой грамматики и оригинальными комнатами в The Legend of Zelda. По результатам тестов, комнаты, сгенерированные с помощью предложенного подхода, не отличались от оригинальных по метрикам удовлетворительности (enjoyability), сложности найти выход, сложности врагов, сложности карты, сложности комнаты и новизны комнаты.
Исходный код: https://github.com/Mawiszus/TOAD-GAN
Обзор
TOAD-GAN (Token-based Oneshot Arbitrary Dimension Generative Adversarial Network) — это алгоритм процедурной генерации контента (PCG), который генерирует уровни в игре по токенам. Токен — это содержательная единица в игре (например, небо, враг или пол). TOAD-GAN обучается one-shot благодаря архитектуре SinGAN. Это значит, что модель может обучиться на одном примере. Исследователи опубликовали расширенную версию модели, которая позволяет пользователю контролировать процесс генерации, чтобы модель генерировала уровни, которые соответствуют глобальной структуре игры.
Детали архитектуры
TOAD-GAN по структуре повторяет SinGAN.
Результаты
Модель протестировали на генерации уровней в игре Super Mario Bros. Предложенный подход обходит базовые модели по схожести сгенерированных уровней с оригинальными.
Исходный код: https://github.com/seanwalton/mixed-initiative-procedural-dungeon-designer
Обзор
Evolutionary Dungeon Designer — это система для полуавтоматизированного дизайна уровней. Система использует RL алгоритм MAP-Elites для поиска оптимальных характеристик уровня. Пользователь может регулировать алгоритм во время обучения, подстраивая его под свои предпочтения.
Детали архитектуры
В MAP-Elites популяция делится на набор клеток, которые зависят от значений в измерениях, описывающих характеристики. Пользователь может динамично выбирать релевантные измерения и внедрять рекомендации, предложенные алгоритмом, в дизайн карты игры. При этом любые модификации от пользователя учитываются при последующей генерации рекомендаций.
Результаты
Исследователи не провели опроса, чтобы оценить качество рекомендаций алгоритма.
Исходный код: N/A
Обзор
Разработчики из Maverick Games протестировали архитектуры для автоматической генерации уровней: DRAGAN, CGAN (semi-supervised), LSTM, PixelRNN.
Результаты
Сложности, с которыми столкнулись: state-of-the-art генеративные архитектуры и LSTM недообучались на доступном ограниченном наборе данных даже с учётом аугментации и не выучивали контекстную информацию из уровней.
Наиболее правдоподобные уровни генерировала PixelRNN. Разработчики добавили функционал редактирования результатов модели. Это позволило гейм-дизайнерам и модели коллаборировать при разработке уровней.
Обучение агентов играть в видеоигры
Исходный код: https://github.com/SestoAle/DeepCrawl
Обзор
DeepCrawl — это пошаговая стратегическая мобильная игра, в которой все враги являются обученными RL-агентами. Пользователь должен исследовать крепости и защищаться от стражей.
Детали архитектуры
В качестве алгоритма для обучения агентов выбрали Proximal Policy Optimization. Каждый агент обучался в случайной комнате.
Результаты
Игра доступна для iOS и Android.
Обзор
Unity Machine Learning Agents Toolkit (ML-Agents) — это опенсорсный инструмент, который позволяет разработчикам обучать агентов для 2D, 3D и VR/AR игр. Агенты могут быть обучены с помощью обучения с подкреплением, имитационного обучения, нейроэволюции или других ML-методов. Кейсы применения включают в себя тестирование игры, контроль поведения NPC и оценка игрового дизайна до релиза.
Дизайн видеоигр
Исходный код: N/A, но есть имплементация метода
Обзор
Исследователи используют методы байесовской оптимизации для разработки игр, которые максимизируют вовлеченность пользователя. Участникам платили за несколько минут тестирования игры. Затем они могли либо продолжить играть, либо прекратить.
Детали архитектуры
В качестве метода использовали оптимизацию с помощью гауссовского процесса, который моделирует пространство дизайна игры. Модель учится оптимизировать набор дизайн-параметров так, что бы максимизировать вовлеченность пользователя. Вовлеченность измерялась с помощью решения остаться или продолжить, представлений о том, как долго будут играть в игру другие пользователи, и результатов опроса после игры.
Результаты
Эксперименты с пользователями проводили на платформе Mechanical Turk. Результаты алгоритма сопоставимы с результатами опроса, который проводили с пользователями после игры.
Тестирование игр
Исходный код: https://github.com/NicholasNapolitano/Jelly_Juice_Reinforcement_Learning
Обзор
Исследователи используют глубокое обучение с подкреплением для тестирования match-3 игр. Модель выучивается предсказывать следующий шаг по текущему состоянию в игре.
Детали архитектуры
В качестве алгоритма используют Dueling Deep QNetwork.
Результаты
Алгоритм тестировали на игре Jelly Juice. Результаты модели сравнили со случайным поведением игрока. У RL-агента выше уровень побед в игре. Результаты агента в большинстве случаев сравнимы с результатами реальных пользователей.