На конференции SysML представлен PyTorch BigGraph (PBG) — распределенную систему для обучения векторного представления графов. Особенность этой системы в том, что она рассчитана на большие графы, содержащие до миллиардов вершин и триллионов ребер.
Документация по фреймворку находится в открытом доступе.
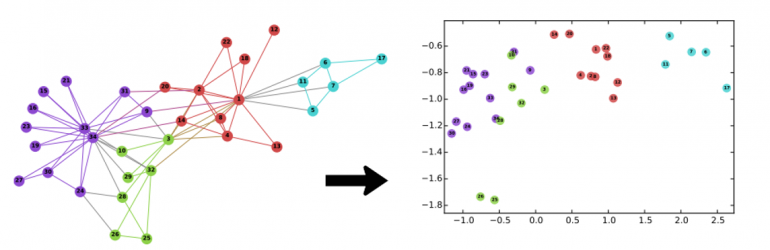
Векторное представление графов — одна из форм обучения без учителя, которая используется для задач прогнозирования в социальных сетях, обнаружения паттернов в IoT, моделирования последовательностей приема лекарств и др. В таких случаях данные естественным образом представляются с использованием графовых структур.
PBG позволяет быстрее создавать векторные представления графовых структур для больших графов в моделях PyTorch. Метод обучения векторных представлений для графов похож на аналогичный для текста — word2vec. Обучение происходит таким образом, чтобы пары вершин, между которыми есть ребра, находились друг к другу ближе, чем не соединенные ребром вершины.
Проблема
Большинство методов построения векторных представлений не подходят для применения к очень большим графовым структурам. К примеру, для модели с двумя миллиардами узлов и сотней параметров векторного представления на узел (выраженных числами с плавающей точкой), потребовалось 800 Гб памяти только для хранения параметров, поэтому требования стандартных методов превышают объем памяти типичных облачных серверов. Для решения этой проблемы и был разработан BigGraph.

Принцип работы
PBG использует четыре подхода:
- Разбиение графа. Теперь модель не потребуется выгружать в память полностью.
- Многопоточные вычисления на каждой машине.
- Распределенное выполнение на нескольких машинах (необязательно), все из них работают над разными частями графа.
- Порционное создание выборки отрицательных ребер для каждого положительного ребра. Позволяет обрабатывать > 1 миллиона ребер/сек на каждой машине.
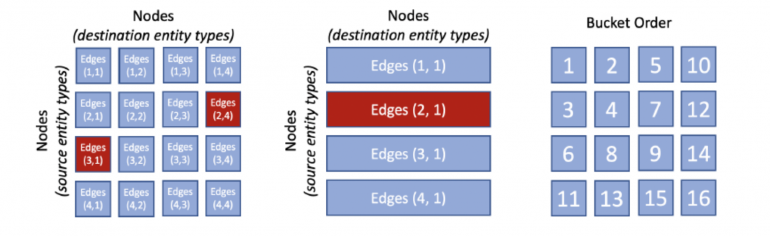
PBG произвольно делит структуру графа на P разделов с таким объемом, чтобы два раздела могли поместиться в памяти.embedding
Если ребро (edge) имеет начальную вершину (node) в разделе p1 и конечную вершину в разделе p2, то он помещается в ячейку (bucket) (p1, p2). Затем ребра графа разбиваются на P2 ячеек в зависимости от их начальной и конечной вершин. После разделения вершин и ребер обучение может выполняться для одной ячейки за раз. Обучение ячейки (p1, p2) требует только того, чтобы векторные представления для разделов p1 и p2 были сохранены в памяти. Структура PBG гарантирует, что у ячеек есть обученное ранее векторное представление хотя бы для одного из разделов.
PBG является одним из первых методов, которые могут масштабироваться и обрабатывать данные графовых структур с миллиардами узлов и триллионами ребер, что позволяет ожидать интересных результатов в ближайшем будущем.