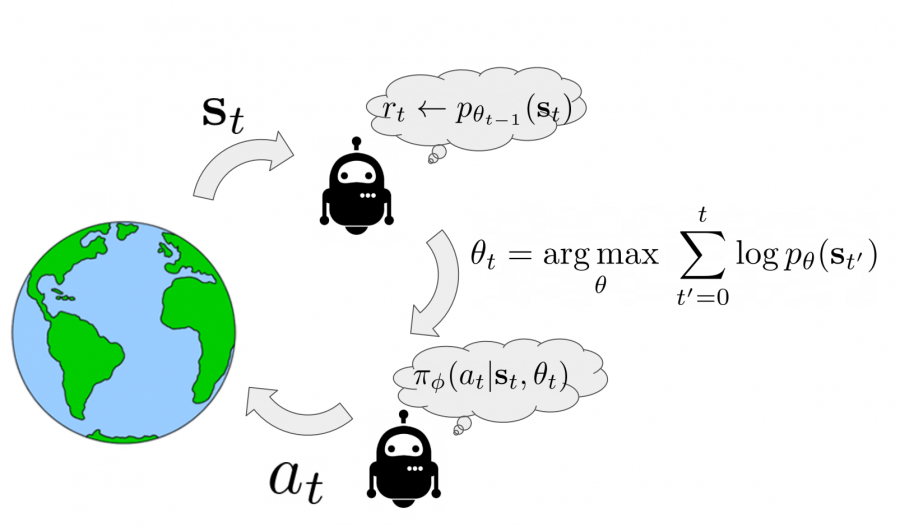
Живые организмы стараются найти такое состояние, в котором поддерживается постоянство внутренней среды (гомеостаз). Исследователи предположили, что такой поиск постоянства среди хаоса применим к искусственным агентам. SMiRL — это алгоритм минимизации неожиданности для обучения RL-агентов. Обученные агенты успешно играют в Tetris, Doom, избегают падения и других вредоносных агентов. При этом агенты выучиваются выполнять эти задачи без дополнительного уточнения награды за задачу.
SMiRL обучает агента так, что целевая функция максимизирует вероятность ранее известных состояний. Алгоритм обучается на предыдущих состояний. Итоговые агенты выучиваются сохранять стабильное состояние: балансировать и избегать повреждений. Эти действия зависят от основных источников энтропии в среде: ветер, землетрясения и другие агенты. SMiRL можно использовать совместно с стандартными наградами, чтобы ускорить обучение агента.
Как это работает
В естественных средах пассивный агент испытывает множество состояний. SMiRL агент совершает действия, которые повышают неожиданность в краткосрочном периоде, но сокращают в долгосрочном. Например, при строительстве дома агент изначально вовлекается в новые состояния. Как только дом построен, агенту становится доступна среда с низким риском неожиданности. В SMiRL агент для каждого состояния считает неожиданность как награду.
Процесс поддержания стабильного состояния организмом называется аллостаз. Исследователи формализуют аллостаз как целевую функцию, которая основана на минимизации неожиданности. В динамических средах минимизация неожиданности приводит к естественному равновесному состоянию агента.

Тестирование алгоритма
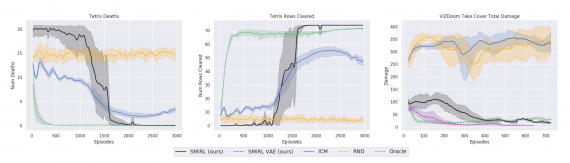
Исследователи сравнили SMiRL с другими алгоритмами для обучения с подкреплением: ICM, RND и алгоритмов оракула. SMiRL агент выучился играть в Tetris и избегать огненные шары в TakeCover. При этом успешность игры агента была сравнима с агентами, которые обучались с прямым указанием награды для задачи.