Исследователи из MIT, Гарварда и университета Цинхуа разработали децентрализованный подход к обучению моделей предсказания смерности и времени пребывания в больнице на основе электронных медицинских карт.
Для проведения работы, исследователи рассмотрели медицинские карты 200 859 пациентов, поступивших в 208 больниц со всей территории США. При этом выбраны три признака:
- лекарства, вводимые пациентам в течение первых 48 часов,
- время пребывания в больнице,
- результат лечения.
После анализа дополнительной информации и внесения данных о пациентах из случайных больниц получился окончательный датасет из 280 000 образцов.
Децентрализация
Модель и информация о пациентах располагаются на локальных серверах, а результат работы интегрируется для обучения в глобальную сеть прогнозов. При таком подходе безопасность и конфиденциальность подвержены меньшим угрозам по сравнению с централизованным методом.
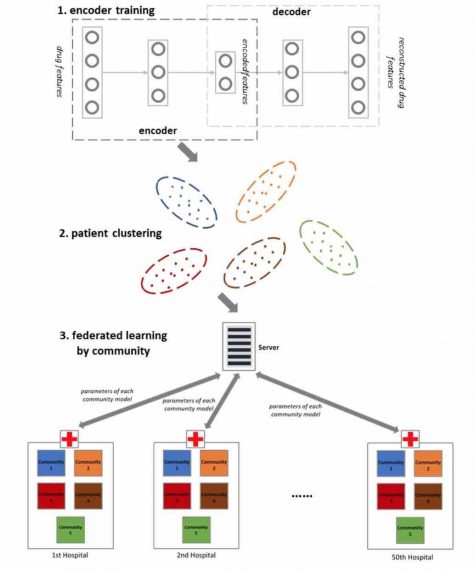
Децентрализованный подход сократит расходы на передачу данных между больницами и сервером и позволит хранить данные о географической принадлежности пациентов. Это поможет детально проработать истории болезней и содержание медицинских книжек, что в итоге благотворно скажется на качестве полученных прогнозов.
Результаты
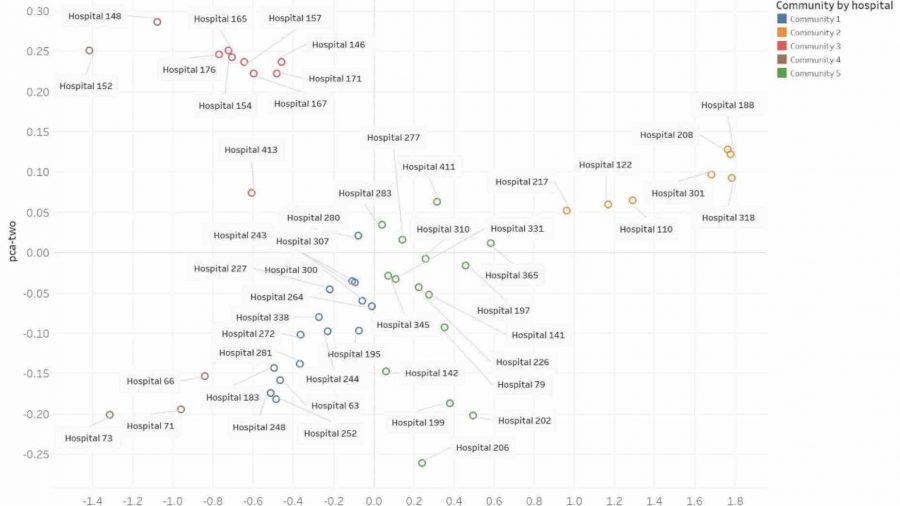
После этого ученые провели кластеризацию на 5 групп по характеру заболеваний, учитывая принадлежность больниц к географическому региону, и приступили к прогнозированию двух вещей: смертности и времени пребывания в больнице. В экспериментах с участием как одной, так и нескольких клиник в обучающих и тестовых выборках, алгоритм достиг точности, близкой к централизованному методу прогнозирования.
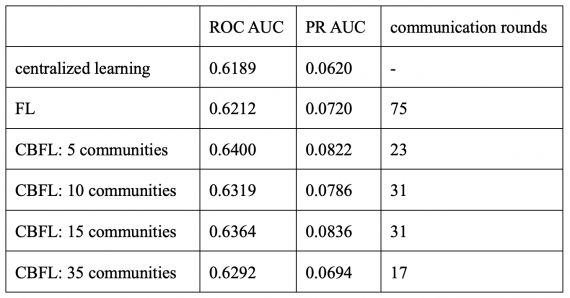
Среди отмеченных минусов, исследователи выделяют неспособность алгоритма учитывать большее количество признаков, а также недостаток в методах кластеризации — не учтен возраст, вес и рост пациентов. Тем не менее, авторы считают это верным вектором развития дальнейшей работы по построению алгоритмов машинного обучения в медицинской тематике.