Google разработала алгоритм, отвечающий за поиск оптимальной архитектуры (neural architecture search, далее NAS), которому понадобилось 48 000 часов работы GPU для создания свёрточной нейронной сети, которая используется для классификации и поиска изображений. В MIT создали алгоритм ProxylessNAS, который до 200 раз превосходит его по скорости работы.
200 часов вместо 48000

В документе, представленном на International Conference on Learning Representations, исследователи MIT описывают алгоритм ProxylessNAS. Этот алгоритм может напрямую изучать специализированные свёрточные нейронные сети (CNN) для целевых аппаратных платформ. Алгоритму при запуске на большом наборе данных потребовалось всего 200 часов GPU, это может позволить гораздо более широкое использование этих типов алгоритмов.
Исследователи MIT разработали способы удаления ненужных компонентов проектирования нейронной сети, сокращения времени вычислений и использование
Тесты CNN проходили на мобильном телефоне, этот алгоритм оказался в 1.8 раз быстрее, чем традиционные методы.
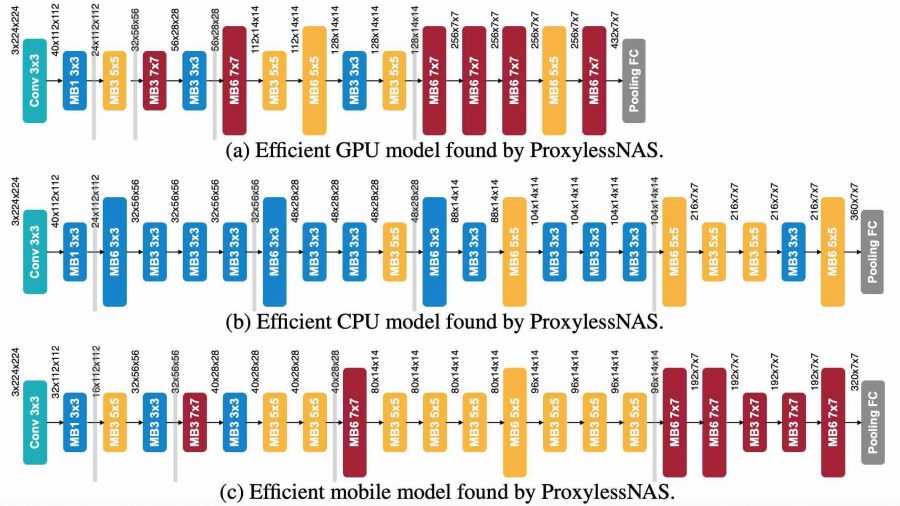
Архитектуры сети
Архитектура CNN состоит из уровней вычислений с настраиваемыми параметрами, называемые фильтрами.
Фильтры обрабатывают пиксели, изображения в сетках квадратов 3х3, 5х5 и 7х7. Каждый фильтр покрывает один квадрат. Фильтры скользят по изображению и объединяют несколько пикселей в один. Результатом является сжатое изображение, которое будет быстрее проанализировано компьютером.
Тестирование алгоритма
Исследователи обучили и протестировали алгоритм NAS для задачи классификации изображений. Тестирование проходило в наборе данных ImageNet, который содержит миллионы изображений. Они создали пространство поиска, которое содержит все возможные пути “кандидатов” и предоставили алгоритму свободу выбора оптимальной архитектуры.
При обучении все пути изначально имеют одинаковую вероятность выбора. Затем алгоритм отслеживает пути, сохраняя их только один раз, чтобы отметить точность их выходных данных. Затем он корректирует вероятности путей для оптимизации точности и эффективности. После этого алгоритм удаляет все пути с низкой вероятностью, сохраняя только путь с наибольшей вероятностью.









