
Stability AI представила Stable Audio — нейросеть для генерации музыки и звуков по текстовой подсказке заданной пользователем длины. Stable Audio способна генерировать 95 секунд стереоаудио с частотой дискретизации 44,1 кГц менее чем за одну секунду на графическом процессоре NVIDIA A100. Работа с сильно уменьшенным скрытым представлением аудиозаписей по сравнению с оригинальными записями значительно сократило время вывода модели. Это первая нейросеть от Stability AI для генерации музыки.
Примеры генерации музыки и звуков
Музыка
Epic trailer music intense tribal percussion and brass (эпическая музыка с интенсивными ударными инструментами и медными духовыми):
Lofi hip hop beat melodic chillhop 85 BPM (Lo-Fi с хип-хоп битами и мелодичным чиллхопом, 85 ударов в минуту):
piano solo chord progression major key uplifting 90 BPM (соло на фортепиано, аккордовая последовательность в мажорной тональности, вдохновляющая, 90 ударов в минуту):
Звуки
Пилот самолета, говорящий по внутренней связи:
Люди разговаривают в переполненном ресторане:
Архитектура Stable Audio
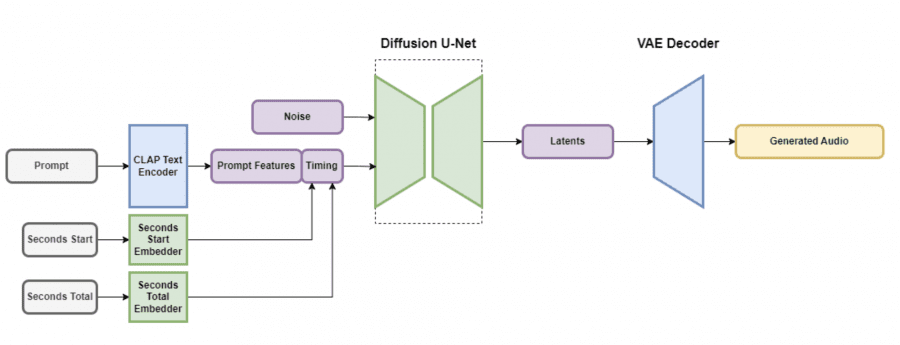
Архитектура Stable Audio включает вариационный автоэнкодер (VAE), текстовый энкодер и диффузионную модель архитектуры U-Net. VAE позволяет модели обучаться и работать быстрее — он принимает входные аудиоданные и выдаёт их в сжатом виде, содержащем достаточно информации для трансформации. Сверточная архитектура на основе кодека Descript Audio Codec кодирует и декодирует аудио произвольной длины с высоким качеством вывода.
Текстовые подсказки интегрируются с помощью замороженного текстового энкодера CLAP, обученного с нуля на собранном исследователями датасете. Это гарантирует, что текстовые признаки содержат достаточную информацию для связи между словами и звуками. Текстовые признаки из предпоследнего слоя энкодера CLAP передаются диффузионной U-Net через слои перекрестного внимания.
При создании аудиофрагмента для временных эмбеддингов вычислялись два параметра: секунды, с которых начинается фрагмент (называемые «seconds_start») и общее количество секунд в исходном аудиофайле (называемые «seconds_total»). Эти значения переводятся в дискретно изученные эмбеддинги и конкатенируются (склеиваются) с токенами запросов перед передачей в слои перекрестного внимания U-Net. Во время вывода эти же значения предоставляются модели в качестве условий, что позволяет пользователю указать общую длину выходного аудио.
Модель диффузии в Stable Audio — это архитектура U-Net с 907 миллионами параметров, основанная на модели Moûsai. Она использует комбинацию остаточных (residual) слоев, слоев самовнимания и слоев перекрестного внимания для очистки входных данных на основе эмбеддингов текста и времени. Внедрены эффективные реализации механизмов внимания, что увеличивает масштабируемость для более длинных последовательностей.
Датасет
Stable Audio обучалась на датасете, содержащем более 800 000 аудиофайлов: музыку, звуковые эффекты, инструментальные сэмплы и соответствующие им текстовые метаданные общей длиной более 19 500 часов. Датасет был получен благодаря сотрудничеству с музыкальной библиотекой AudioSparx.
Дальнейшие шаги
В дальнейшем планируется усовершенствование архитектур моделей, наборов данных и методов обучения для повышения качества выходных данных, управляемости, скорости вывода и длины вывода. Компания намерена в ближайшем будущем выпустить модели с открытым исходным кодом на основе Stable Audio, а также код для обучения собственных моделей генерации аудиоконтента.









Полный отстой!!!
Са ты отстой тварь MC Person тупой лось блять