Stability AI has introduced Stable Audio – a generative model designed to generate music and sounds based on user-provided text prompts. Stable Audio is capable of producing 95 seconds of stereo audio with a 44.1 kHz sampling rate in less than a second on an NVIDIA A100 GPU. Working with significantly reduced latent representations of audio compared to the original recordings has significantly reduced the model’s processing time.
Examples of Music and Sounds Generated
Music
Epic trailer music featuring intense tribal percussion and brass:
Lofi hip-hop beat with melodic chillhop at 85 BPM:
Piano solo with a major key uplifting chord progression at 90 BPM:
Sounds
Airplane pilot communicating over the intercom:
People conversing in a crowded restaurant:
Stable Audio Architecture
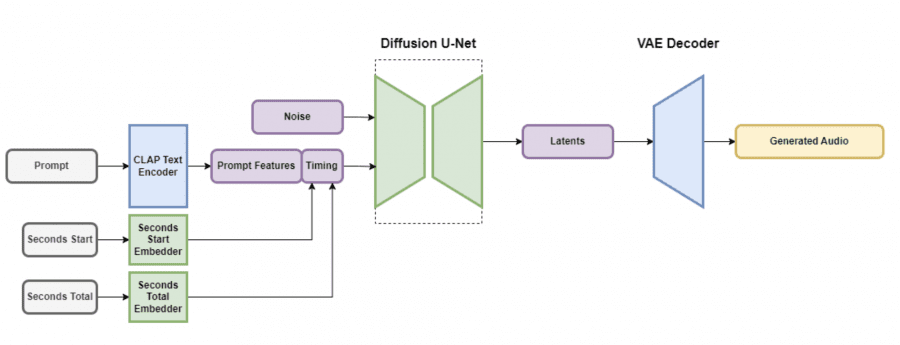
The architecture of Stable Audio includes a Variational Autoencoder (VAE), a text encoder, and the diffusion model architecture of U-Net. The VAE allows the model to learn and operate more efficiently by taking input audio data and outputting it in a compressed form containing sufficient information for transformation. The convolutional architecture, based on the Descript Audio Codec, encodes and decodes audio of arbitrary length with high output quality.
Text prompts are integrated using a frozen text encoder called CLAP, trained from scratch on a dataset curated by researchers. This ensures that the text features contain enough information to establish connections between words and sounds. Text features from the penultimate layer of the CLAP encoder are passed through the U-Net’s attention layers.
To create audio segments for temporal embeddings, two parameters were computed: the starting seconds of the segment (referred to as “seconds_start”) and the total number of seconds in the original audio file (referred to as “seconds_total”). These values are converted into discretely learned embeddings and concatenated with query tokens before being passed to the U-Net’s attention layers. During inference, the same values are provided as conditions, allowing users to specify the overall length of the output audio.
The diffusion model in Stable Audio is a U-Net architecture with 907 million parameters, based on the Moûsai model. It employs a combination of residual layers, self-attention layers, and cross-attention layers to denoise input data based on text and time embeddings. Efficient attention mechanisms have been incorporated to enhance scalability for longer sequences.
Dataset
Stable Audio was trained on a dataset comprising over 800,000 audio files, including music, sound effects, instrumental samples, and their corresponding textual metadata, totaling more than 19,500 hours. This dataset was obtained through collaboration with the music library AudioSparx.
Future Steps
In the future, there are plans to refine the architecture of the models, datasets, and training methods to improve output quality, controllability, processing speed, and output length. The company intends to release open-source models based on Stable Audio and provide code for training custom audio content generation models.