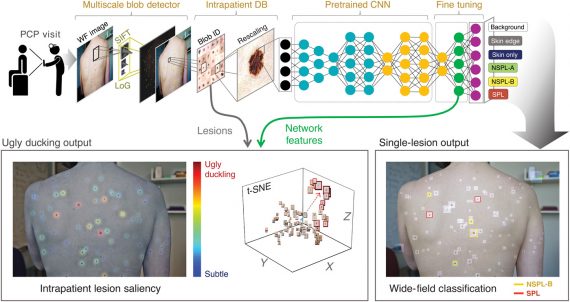
Двое исследователей из Техасского университета A&M разработали подход, который позволяет рассмотреть одну фотографию с разных точек зрения. Инструмент включает в себя одну предобученную нейросеть, две параллельные сверточные нейросети и датасет с разными картинками. Возможность наблюдения одной сцены требует сложного оборудования для камер, поэтому разработчики упростили этот процесс.
Актуальность
Стандартные изображения, сделанные на обычные смартфоны, захватывают сцену только с одного ракурса. В реальности мы можем наблюдать эту же сцену с разных точек. За последние несколько лет было разработано множество подходов к генерации новых видов изображения, но все они требуют снимать несколько фотографий одной и той же сцены с разных ракурсов одновременно определённым оборудованием. Эти подходы являются трудоемкими и неудобными.
Подробнее о технологии
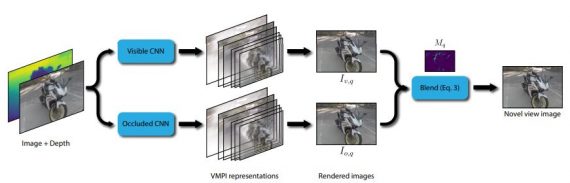
Инструмент принимает на вход два изображения – непосредственно сама фотография и ее глубина. Глубину изображения получают с помощью предобученной нейросети оценки глубины, и полученная глубина является относительной. Основной алгоритм состоит из двух параллельных сверточных нейросетей. Первая нейросеть отвечает за видимую область, вторая нейросеть за закрытую область. Каждая нейросеть оценивает многоуровневое представление фотографии – разделение изображения на плоскости с разной глубиной в зависимости от расположения объектов — по обычной версии и ее относительной «глубине». После деления на уровни нейросеть восстанавливает два изображения и соединяет с помощью «мягкой маски видимости» для создания окончательно изображения.
Нейросеть эффективно обучилась благодаря датасету из более чем 2000 уникальных сцен, содержащих различные объекты. Также использовали набор данных Stanford Multiview Light Field для обучения и тестирования. В общей сложности разработчики использовали 5750 сцен для обучения и 150 сцен для тестирования. Применялись серии дополнений данных, включая случайную настройку гаммы, насыщенности, оттенка и контрастности, а также замена цветовых каналов, чтобы уменьшить вероятность переобучения.
Представленный метод возможно использовать для создания перефокусированных изображений. Более того, инструмент потенциально может использоваться для приложений виртуальной и дополненной реальности, которые позволяют исследовать конкретную визуальную среду.

Посмотреть визуализацию описанного метода Вы можете по этой ссылке.
Заключение
Созданный подход позволяет «оживить» изображения, исходя только из одной картинки. Возможно использовать любые изображения, которое есть у пользователя, например, скачанное из Интернета. Исследователи также работают над расширением своего подхода для применения на видео. Исходный код доступен на GitHub.