
YouTokenToMe — это библиотека для предобработки текстовых данных. Инструмент работает в 7-10 раз быстрее аналогов для текстов на алфавитных языках и в 40-50 на иероглифических языках. Библиотека была разработана исследователями из ВКонтакте.
Сейчас большая часть задач, которые решаются нейросетями, связаны с обработкой текстов. Нейросети принимают на вход числовые данные, поэтому тексты перед этим предобрабатывают.
Токен в обработке естественного языка — это единица анализа. Токенами могут быть отдельные слова, словосочетания (n-граммы) или части слов. Процесс разделения текста на единицы анализа называется токенизацией.
Популярными методами для предобработки текстов являются:
- Разделение по пробелу;
- Токенизация, основанная на правилах (например, в SpaCy и NLTK);
- Лемматизация, стемминг
Каждый из перечисленных способов имеет свои недостатки:
- Размер словаря, от которого зависит размер векторного представления слов в модели, не контролируется;
- Информация о словообразовании не используется (например, не используется связь слов с одним корнем с приставкой и без);
- Способы токенизации зависят от языка
Что такое BPE
Алгоритм Byte Pair Encoding был разработан, чтобы учитывать перечисленные выше недостатки. BPE делит слова на части. Таким образом получается избежать проблемы с тем, что модель не знает слов, которые не находятся в словаре обучающей выборки.
Изначально BPE использовался для сжатия текста. Недавно его начали использовать для токенизации текстовых данных. В таких моделях, как BERT и GPT-2, тексты токенизировались с помощью BPE.
Наиболее эффективные реализации алгоритма были SentencePiece, который разработали в Google, и fastBPE от Facebook AI Research. Исследователи из ВКонтакте показали, что алгоритм может работать в 7-10 раз быстрее. Оптимизированная реализация BPE лежит в репозитории на GitHub.
Разработчики сравнили разные реализации алгоритма по времени. В экспериментах они использовали 100 мегабайт базы Википедии на русском, английском, японском и китайском. График ниже показывает, что скорость алгоритма зависит от языка. Это можно объяснить различием в количестве символов в азиатских языках. Помимо этого, в языках с иероглифами слова не могут делиться по пробелу.
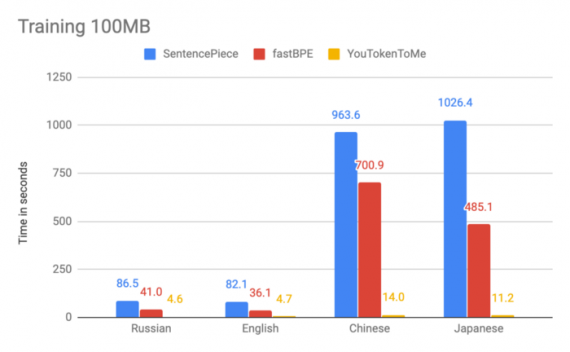
Оптимизированный BPE работает как минимум в два раза быстрее существующих альтернатив. В каких-то тестах скорость работы выросла в 10 раз.
Две основные характеристики оптимизированного алгоритма:
- Линейное время работы, которое зависит от размера обучающего корпуса текстов;
- Использование нескольких потоков для обучения и токенизации. Это сокращает время работы алгоритма в несколько раз.
Аналоговые алгоритмы имеют более высокую асимптотическую сложность.




