Библиотека Scikit-learn — самый распространенный выбор для решения задач классического машинного обучения. Она предоставляет широкий выбор алгоритмов обучения с учителем и без учителя. Обучение с учителем предполагает наличие размеченного датасета, в котором известно значение целевого признака. В то время как обучение без учителя не предполагает наличия разметки в датасете — требуется научиться извлекать полезную информацию из произвольных данных. Одно из основных преимуществ библиотеки состоит в том, что она работает на основе нескольких распространенных математических библиотек, и легко интегрирует их друг с другом. Еще одним преимуществом является широкое сообщество и подробная документация. Scikit-learn широко используется для промышленных систем, в которых применяются алгоритмы классического машинного обучения, для исследований, а так же для новичков, которые только делает первые шаги в области машинного обучения.
Для своей работы, scikit-learn использует следующие популярные библиотеки:
- NumPy: математические операциии и операции над тензорами
- SciPy: научно-технические вычисления
- Matplotlib: визуализация данных
- IPython: интерактивная консоль для Python
- SymPy: символьная математика
- Pandas: обработка, манипуляции и анализ данных
Что содержит Scikit-learn
В задачи библиотеки не входит загрузка, обработка, манипуляция данными и их визуализация. С этими задачами отлично справляются библиотеки Pandas и NumPy. Scikit-learn специализируется на алгоритмах машинного обучения для решения задач обучения с учителем: классификации (предсказание признака, множество допустимых значений которого ограничено) и регрессии (предсказание признака с вещественными значениями), а также для задач обучения без учителя: кластеризации (разбиение данных по классам, которые модель определит сама), понижения размерности (представление данных в пространстве меньшей размерности с минимальными потерями полезной информации) и детектирования аномалий.
Библиотека реализует следующие основные методы:
- Линейные: модели, задача которых построить разделяющую (для классификации) или аппроксимирующую (для регрессии) гиперплоскость.
- Метрические: модели, которые вычисляют расстояние по одной из метрик между объектами выборки, и принимают решения в зависимости от этого расстояния (K ближайших соседей).
- Деревья решений: обучение моделей, базирующихся на множестве условий, оптимально выбранных для решения задачи.
- Ансамблевые методы: методы, основанные на деревьях решений, которые комбинируют мощь множества деревьев, и таким образом повышают их качество работы, а также позволяют производить отбор признаков (бустинг, бэггинг, случайный лес, мажоритарное голосование).
- Нейронные сети: комплексный нелинейный метод для задач регрессии и классификации.
- SVM: нелинейный метод, который обучается определять границы принятия решений.
- Наивный Байес: прямое вероятностное моделирование для задач классификации.
- PCA: линейный метод понижения размерности и отбора признаков
- t-SNE: нелинейный метод понижения размерности.
- K-средних: самый распространенный метод для кластеризации, требущий на вход число кластеров, по которым должны быть распределены данные.
- Кросс-валидация: метод, при котором для обучения используется весь датасет (в отличие от разбиения на выборки train/test), однако обучение происходит многократно, и в качестве валидационной выборки на каждом шаге выступают разные части датасета. Итоговый результат является усреднением полученных результатов.
- Grid Search: метод для нахождения оптимальных гиперпараметров модели путем построения сетки из значений гиперпараметров и последовательного обучения моделей со всеми возможными комбинациями гиперпараметров из сетки.
Это — лишь базовый список. Помимо этого, Scikit-learn содержит функции для расчета значений метрик, выбора моделей, препроцессинга данных и другие.
Пример применения
Чтобы дать вам представление о том, как легко обучать и тестировать модель ML с помощью Scikit-Learn, вот пример того, как это сделать для классификатора дерева решений!
Деревья решений для классификации и регрессии очень просты в использовании в Scikit-Learn. Сначала мы загрузим наш датасет, который фактически встроен в библиотеку. Затем мы инициализируем наше дерево решений для классификации. Обучение модели — это просто одна строчка .fit(X, Y), где X — обучающая выборка в формате массива NumPy, а Y — массив целевых значений, также в формате массива NumPy.
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier, plot_tree # Load data iris = load_iris()
Scikit-Learn также позволяет нам визуализировать наше дерево. Для этого есть несколько настриваемых опций, которые помогут визуализировать узлы принятия решений и разбить изученную модель, что очень полезно для понимания того, как она работает. Ниже мы раскрасим узлы на основе имен признаков и отобразим информацию о классе и объектах каждого узла.
plt.figure(figsize=((20,13)))
clf = DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
plot_tree(clf,
filled=True,
feature_names=iris.feature_names,
class_names=iris.target_names,
rounded=True)
plt.show()
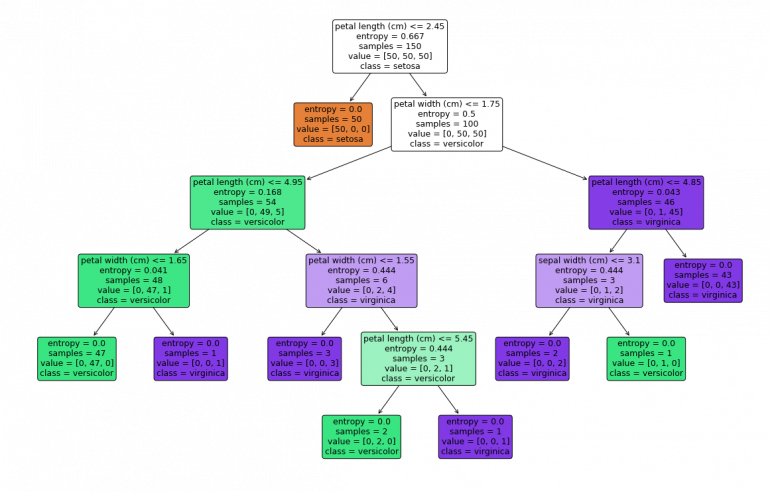
Каждый из параметров алгоритма интуитивно назван и доступно объяснен. Кроме того, разработчики также предлагают туториалы с примером кода о том, как обучать и применять модель, ее плюсы и минусы и практические советы по применению.



