Trinity-Large-Thinking 400B: масшабная открытая reasoning-модель для агентных задач стоит в 28 раз дешевле Claude Opus-4.6
3 апреля 2026

Trinity-Large-Thinking 400B: масшабная открытая reasoning-модель для агентных задач стоит в 28 раз дешевле Claude Opus-4.6
Компания Arcee AI выложила в открытый доступ Trinity-Large-Thinking — модель с рассуждениями для сложных многоходовых агентных задач. На PinchBench — главном бенчмарке для агентных задач — она занимает второе место…
PixelSmile: открытая модель для редактирования эмоций на изображениях с плавным контролем интенсивности эмоций
31 марта 2026
PixelSmile: открытая модель для редактирования эмоций на изображениях с плавным контролем интенсивности эмоций
Исследователи из Fudan University и StepFun опубликовали PixelSmile — диффузионную модель для точного редактирования мимики на портретах и аниме-изображениях. Вместо обучения на дискретных метках, например, «страх/не страх», модель использует непрерывные…
RealRestorer: открытая модель улучшения качества фото обогнала Nano Banana Pro на бенчмарке с реальными снимками
30 марта 2026

RealRestorer: открытая модель улучшения качества фото обогнала Nano Banana Pro на бенчмарке с реальными снимками
Команда исследователей из StepFun, Southern University of Science and Technology и Китайской академии наук опубликовала RealRestorer — открытую модель улучшения качества фотографий, которая умеет убирать размытость, шум, дождь, засветку от…
MinerU-Diffusion: новый подход к OCR через диффузионное декодирование ускоряет парсинг PDF в 3 раза без потери точности
27 марта 2026

MinerU-Diffusion: новый подход к OCR через диффузионное декодирование ускоряет парсинг PDF в 3 раза без потери точности
Команда из Shanghai Artificial Intelligence Laboratory и Пекинского университета опубликовала MinerU-Diffusion — фреймворк для распознавания текста в документах (OCR), который отказывается от классической авторегрессивной генерации в пользу диффузионного декодирования. Проект…
daVinci-MagiHuman: открытая 15B-модель генерирует 5-секундное видео с липсинком за 2 секунды на одном H100
24 марта 2026

daVinci-MagiHuman: открытая 15B-модель генерирует 5-секундное видео с липсинком за 2 секунды на одном H100
Команды SII-GAIR и Sand.ai опубликовали daVinci-MagiHuman — открытую мультимодальную 15B-модель на основе однопоточного трансформера, которая одновременно генерирует видео с липсинком и синхронное аудио и создает 5-секундный клип в 256p за…
OpenClaw: лобстер, который захватил мир. ИИ-агент работает локально и управляется через мессенджеры
18 марта 2026

OpenClaw: лобстер, который захватил мир. ИИ-агент работает локально и управляется через мессенджеры
OpenClaw — открытый ИИ-агент, созданный австрийским разработчиком Питером Штайнбергером в ноябре 2025 года. ИИ-агент — это программная оболочка вокруг языковой модели, которая не просто генерирует текст в ответ на запрос,…
OpenClaw-RL: ИИ-агент учится на собственных ошибках через реакции пользователя и среды, обновляя веса на ходу
17 марта 2026

OpenClaw-RL: ИИ-агент учится на собственных ошибках через реакции пользователя и среды, обновляя веса на ходу
Исследователи из Princeton University предложили фреймворк OpenClaw-RL, позволяющий ИИ-агенту улучшаться в режиме реального времени — без отдельного этапа сбора данных и без ручной разметки. Большинство RL-фреймворков для языковых моделей работают…
Helios: 14B-модель генерирует видео длиной больше 60 секунд со скоростью 19,5 FPS на одной H100
11 марта 2026

Helios: 14B-модель генерирует видео длиной больше 60 секунд со скоростью 19,5 FPS на одной H100
Команда исследователей из Пекинского университета и ByteDance опубликовала Helios — авторегрессионную диффузионную трансформер-модель на 14 миллиардов параметров, которая генерирует видео со скоростью 19,5 кадров в секунду на одной видеокарте NVIDIA…
VBVR: открытый датасет на 2 миллиона видео для обучения видеомоделей рассуждению
26 февраля 2026

VBVR: открытый датасет на 2 миллиона видео для обучения видеомоделей рассуждению
Команда из более чем 50 исследователей со всего мира — из Berkeley, Stanford, CMU, Oxford и других университетов — опубликовала Very Big Video Reasoning (VBVR) — огромный набор данных для…
GLM-5: топ-1 открытая модель для генерации кода и текста, конкурирующая с Claude и GPT на агентных задачах
19 февраля 2026

GLM-5: топ-1 открытая модель для генерации кода и текста, конкурирующая с Claude и GPT на агентных задачах
Zhipu AI и Tsinghua University опубликовали техрепорт GLM-5 — на сегодня лучшей открытой языковой модели по бенчмаркам: первое место среди open-weight моделей на Artificial Analysis и топ-1 в кодинге и…
Baichuan-M3: открытая медицинская модель, которая ведёт приём как настоящий врач и обходит GPT-5.2 на тестах
10 февраля 2026

Baichuan-M3: открытая медицинская модель, которая ведёт приём как настоящий врач и обходит GPT-5.2 на тестах
Команда исследователей из китайской компании Baichuan представила Baichuan-M3 — открытую медицинскую языковую модель, которая вместо традиционного режима «вопрос-ответ» ведет полноценный клинический диалог, активно собирая анамнез и принимая взвешенные медицинские решения.…
Claude Sonnet 4.5 побеждает на полноценном backend-бенчмарке, лучше всех справившись и с кодом, и с настройкой окружения
22 января 2026

Claude Sonnet 4.5 побеждает на полноценном backend-бенчмарке, лучше всех справившись и с кодом, и с настройкой окружения
Команда исследователей из Fudan University и Shanghai Qiji Zhifeng Co. представила ABC-Bench — первый бенчмарк, который проверяет способность ИИ-агентов решать полноценные задачи backend-разработки: от изучения кода в репозитории до настройки…
Multiplex Thinking: семплинг 3 токенов вместо 1 повышает точность решения олимпиадных задач с 40% до 55%
22 января 2026

Multiplex Thinking: семплинг 3 токенов вместо 1 повышает точность решения олимпиадных задач с 40% до 55%
Исследователи из Университета Пенсильвании и Microsoft Research представили Multiplex Thinking — новый метод рассуждения для больших языковых моделей. Идея в том, чтобы на каждом шаге генерировать не один токен, а…
Yume1.5: открытая модель для создания интерактивных миров, управляемая с клавиатуры
5 января 2026

Yume1.5: открытая модель для создания интерактивных миров, управляемая с клавиатуры
Исследователи из Shanghai AI Laboratory и Fudan University опубликовали Yume1.5 — модель для генерации интерактивных виртуальных миров, которыми можно управлять прямо с клавиатуры. В отличие от обычной генерации видео, здесь…
AI-модели на 13% хуже людей распознают сгенерированные ASMR-видео
18 декабря 2025

AI-модели на 13% хуже людей распознают сгенерированные ASMR-видео
Исследователи из CUHK, NUS, University of Oxford и Video Rebirth представили Video Reality Test — первый бенчмарк, который проверяет, могут ли современные AI-модели создавать видео, неотличимые от настоящих. В отличие…
Wan-Move: открытая альтернатива Kling 1.5 Pro для контролируемой генерации движений на видео
13 декабря 2025

Wan-Move: открытая альтернатива Kling 1.5 Pro для контролируемой генерации движений на видео
Команда исследователей из Tongyi Lab (Alibaba Group), Университета Цинхуа и Гонконгского университета представила Wan-Move — новый подход к точному контролю движения в генеративных видео-моделях. В отличие от существующих методов, которые…
Открытая модель впервые получила золотую медаль на Международной физической олимпиаде IPhO 2025
30 ноября 2025

Открытая модель впервые получила золотую медаль на Международной физической олимпиаде IPhO 2025
Модель P1-235B-A22B от Shanghai AI Laboratory стала первой открытой моделью, которая получила золотую медаль на последней Международной физической олимпиаде IPhO 2025, набрав 21.2 балла из 30 и заняв третье место после…
MiroThinker v1.0: открытый ИИ-агент для исследований научился делать до 600 вызовов инструментов на задачу
20 ноября 2025
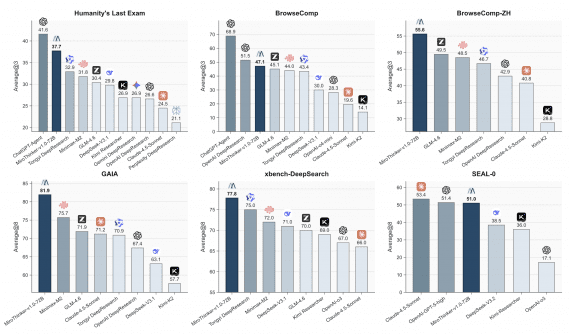
MiroThinker v1.0: открытый ИИ-агент для исследований научился делать до 600 вызовов инструментов на задачу
Команда MiroMind представила MiroThinker v1.0 — ИИ-агент для исследований, выполняющий до 600 вызовов инструментов на одну задачу при контекстном окне размером 256К токенов. На четырёх ключевых бенчмарках — GAIA, HLE,…
Какой ИИ способен сыграть злодея: сравнение алгоритмов выравнивания 17 моделей
13 ноября 2025
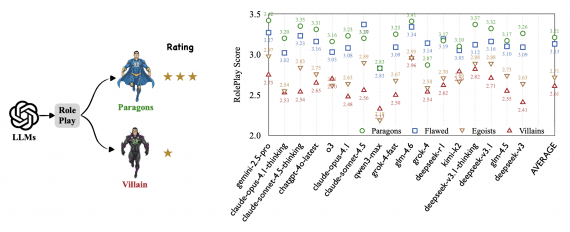
Какой ИИ способен сыграть злодея: сравнение алгоритмов выравнивания 17 моделей
Исследователи из Tencent Multimodal Department и Sun Yat-Sen University опубликовали работу о том, как большие языковые модели справляются с ролевыми играми. Оказалось, что ИИ-модели справляются с ролевыми играми посредственно: даже…
DeepEyesV2: мультимодальная модель научилась использовать инструменты для решения сложных задач
12 ноября 2025

DeepEyesV2: мультимодальная модель научилась использовать инструменты для решения сложных задач
Исследователи из компании Xiaohongshu представили DeepEyesV2 — агентную мультимодальную модель на базе Qwen2.5-VL-7B, которая умеет не просто понимать текст и изображения, но и активно использовать внешние инструменты: выполнять код на…
Remote Labor Index: ведущие ИИ-агенты справились с 2.5% реальных задач с биржи фрилансеров
4 ноября 2025

Remote Labor Index: ведущие ИИ-агенты справились с 2.5% реальных задач с биржи фрилансеров
Команда исследователей из Center for AI Safety и Scale AI опубликовала Remote Labor Index (RLI) — первый бенчмарк, который проверяет, могут ли ИИ-агенты делать настоящую работу фрилансеров. Они собрали 240…