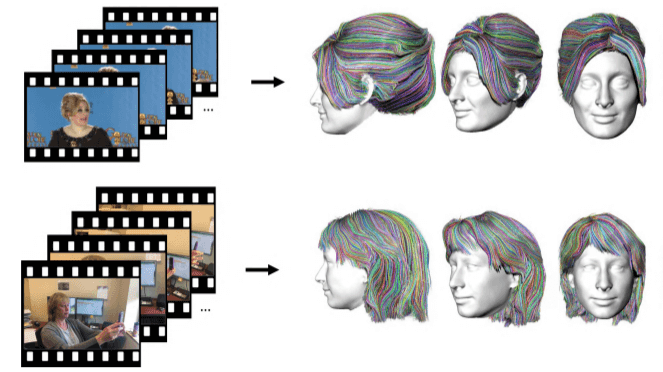
Трехмерные модели волос используются в виртуальной и дополненной реальности, видеоиграх, медицинском ПО. Однако создать реалистичную 3D-модель прически трудно даже в контролируемой среде. Исследователи предложили метод решения ещё более сложной задачи — реконструкции волос из обычных фотографий и видео.
Предыдущие работы
Недавно мы писали о подходе к реалистичной трехмерной реконструкции волос из одного изображения. Подобные методы хорошо работают, но не позволяют добиться высокой точности. Подходы, которые используют сегментацию дают улучшенные результаты, однако увеличивают сложность и требуют большего количества изображений и контролируемую среду с 360 градусами обзора.
State-of-the-art идея
Новый подход, предложенный исследователями из Вашингтонского университета, позволяет автоматически создавать 3D-модель волос и головы из входящего видео. Кадры видео используются несколькими компонентами для создания прядей волос, которые оцениваются и деформируются в 3D.
Метод
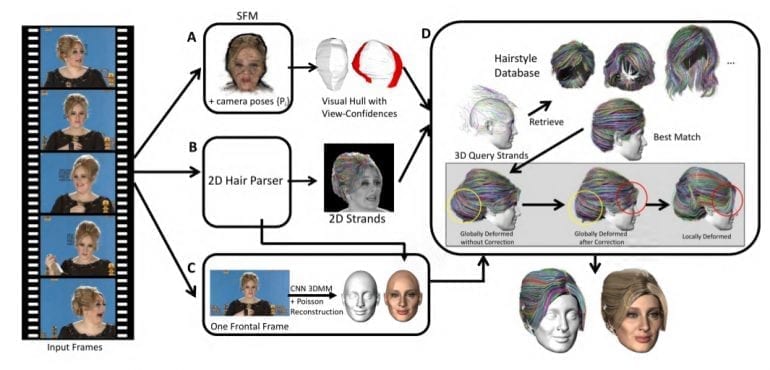
Модель состоит из 4 компонентов, которые показаны на рисунке ниже:
A: модуль, который анализирует движения камеры, позу головы, карты глубины с показателями достоверности.
B: модуль, в котором применяется сегментация и определяется направление роста волос для каждого кадра. В этом модуле получается 2D-модель волос.
C: сегментация из модуля B используется для восстановления текстуры лицевой области. Для определения формы лица и головы без волос используется модель морфинга 3D-лица.
D: последний модуль — самый важный. В нём карты глубин и 2D-пряди используются для создания трехмерных прядей. Пряди сравниваются с базой данных волос. Те, которые лучше всего соответствуют, обрабатываются так, чтобы соответствовать входным кадрам из видео.
Таким образом получается надежный и гибкий метод, который восстанавливает 3D-пряди волос из необработанных видеокадров.
Модуль А
Первый модуль используется для грубой оценки формы головы. Каждый кадр в видео подвергается препроцессингу с использованием семантической сегментации для отделения фона от человека. Цель — оценка позиции камеры в каждом кадре и создание грубой начальной структуры из всех кадров.
После предварительной обработки и удаления фона голова извлекается с использованием структуры «motion approach» — оценки позы камеры для каждого кадра и покадровой глубины для всех кадров в видео.
Модуль B
Второй модуль содержит подготовленную сегментацию волос и классификаторы направления роста волос для маркировки и прогнозирования направления укладки волос в пикселях. Модуль основан на методе оценки направления прядей Chai 2016.

Модуль C
В этом модуле сегментированные кадры используются для выбора кадра, который ближе всего к анфасу. Кадр подается в эстиматор моделей лица, основанный на морфированных моделях.
Модуль D
Последний — основной модуль — оценивает трехмерные пряди волос, используя выходные данные модулей A, B и C. Полученные 3D-пряди волос являются неполными, так как основаны на 2D-прядях. Для того чтобы сделать их более реалистичными, модель обращается к набору данных трехмерных моделей волос. В работе использован набор, созданный Chai et al. 2016, который содержит 35 000 различных причесок. Каждая модель прически состоит из 10 000 прядей волос. В конце применяются глобальная и локальная деформация для обработки полученных прядей, для того чтобы они приняли форму прядей из оригинального видео.
Результаты
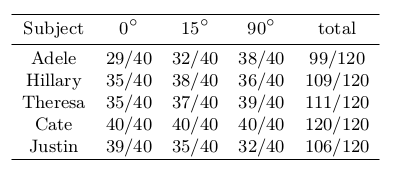
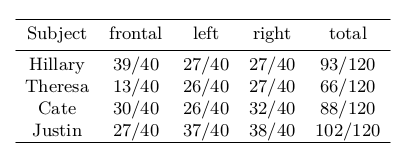
Для оценки результатов предлагаемого подхода, исследователи использовали количественные и качественные метрики. Количественное сравнение производится путем проецирования реконструированного волоса на изображения. Вычисляется количество линий и пересечений по отношению к основной маске истины на каждый кадр. Результаты показаны в таблице ниже. Увеличение IOU означает, что восстановленные волосы лучше аппроксимируют ввод.

Качественные характеристики сравнили с другими современными методами, используя тест Mechanical Turk.

Вывод
В работе исследователи предложили полностью автоматизированный способ восстановления трехмерной модели волос из видео. Хотя метод довольно сложен и требует многих шагов, результаты более чем удовлетворительные. Подход показывает, что более высокая точность результатов может быть получена путем включения информации из нескольких кадров видео с разными точками обзора. Метод использует информацию из нескольких кадров для восстановления волос, не ограничиваясь определенными позами головы.