Исследователи давно изучают взаимосвязь видео и звука и проблемы, связанные с их обработкой. В прошлом учёные рассматривали проблемы локализации звука в видео, создание аудио для видео без звука, обучение без учителя в связанных с видео задачах с помощью аудиосигналов и другие.
Новая идея
В недавно опубликованной работе, представленной исследователями из Массачусетского технологического института, MIT-IBM Watson AI Lab и Колумбийского университета, рассматривается новый взгляд на взаимосвязь видео и звука. Исследователи разработали метод обучения без учителя, который позволяет находить области изображения, которые генерируют звук, и разделять звуки на набор компонент, которые создаются в разных пикселях изображения.
Метод
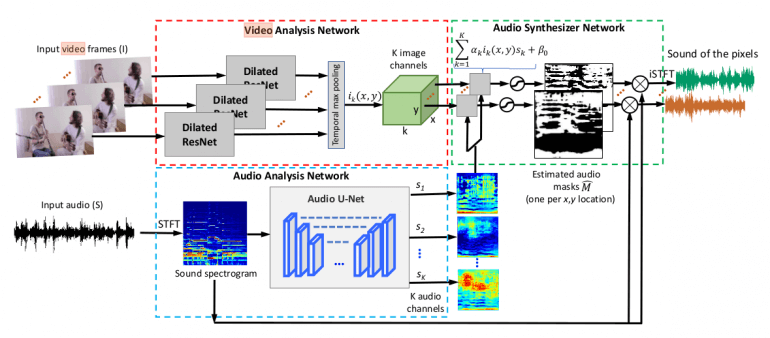
Новый подход сосредоточен на использовании естественной синхронизации визуальной и звуковой информации, чтобы обучаться разделять и локализовывать звуковые компоненты в видео без учителя. Предложенная технология называется PixelPlayer и позволяет распознавать и локализовать объекты на изображениях и отделять звуковые компоненты, создаваемые в каждом из них. Также, исследователи представили новый датасет видео с музыкальными инструментами MUSIC, собранный специально для данной задачи.

Как упоминалось выше, предлагаемый метод локализует источники звука в видео и разделяет звук на компоненты без учителя. Модель состоит из трех модулей: сети анализа видео, сети анализа звука и сети синтеза звука. Такая архитектура позволяет извлекать визуальные и звуковые свойства для цели разделения и локализации аудио-визуальных источников.
Сеть анализа видео
Сеть анализа видео пытается извлечь визуальные свойства из каждого кадра в ролике. К каждому выделенному из кадра свойству применяется временное объединение для получения вектора визуальных свойств каждого пикселя. Для этого исследователи используют вариацию популярной сети ResNet-18 с расширенными свертками.
Сеть анализа аудио
Параллельно с извлечением визуальных свойств сеть анализа звука пытается разбить звук на видео на K штук компонент. Для решения этой задачи исследователи предлагают использовать звуковые спектрограммы вместо необработанных звуковых сигналов и сверточную архитектуру Audio U-Net, которая, как было показано ранее, эффективна для работы с аудиоданными. Используя эту архитектуру энкодер-декодер, из спектрограммы извлекается карта K свойств, содержащая свойства различных компонент звука. Перед этим, чтобы получить звуковую спектрограмму для входных данных, использовалось оконное преобразование Фурье (STFT).
Сеть синтеза звука
Основной модуль предлагаемого метода — сеть синтеза звука, которая принимает на вход выходные данные двух предыдущих сетей. Она использует вектор визуальных свойств каждого пикселя и вектор звуковых свойств для вывода маски, которая выделяет из спектрограммы звук, исходящий от конкретного пикселя. В результате умножения маски на спектрограмму получается спектр звука каждого пикселя. Для получения аудиосигнала применяется обратное оконное преобразование Фурье.
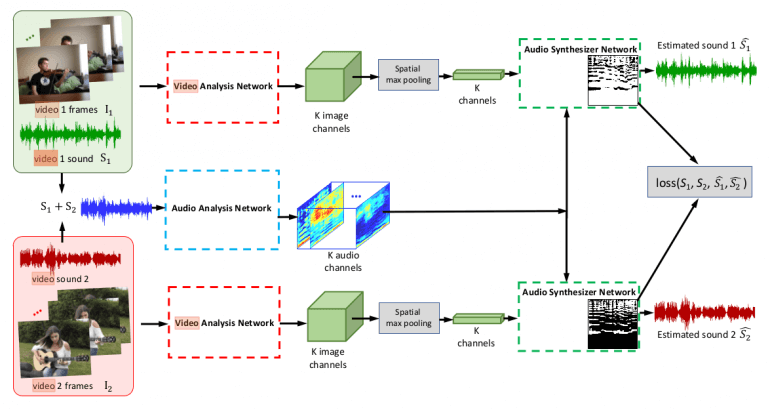
Для обучения сети без учителя, исследователи предложили фреймворк Mix-and-Separate (смешай и раздели). Идея основывается на предположении, что для звука выполняется принцип суперпозиции. Поэтому учёные смешивают звуки из разных видеороликов, чтобы сгенерировать сложный аудиосигнал, а затем разделяют интересующий звуковой источник на связанный с ним объект — в этом и заключается цель обучения.
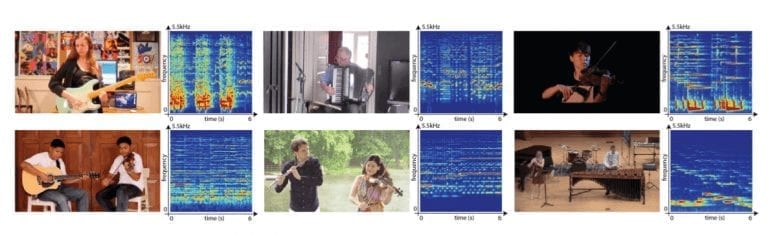
Результаты
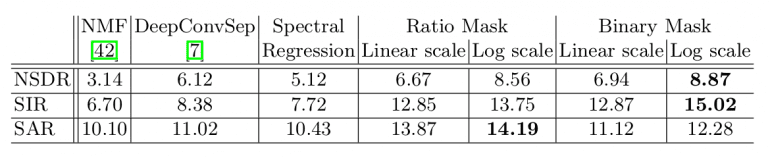
Для оценки метода авторы снова используют обучающий фреймворк Mix-and-Separate. Они создали набор синтезированных звуков для обучения, а оценка показывает успешность метода для их разделения. Поскольку цель состоит в том, чтобы составить спектрограмму, оценка состоит в сравнении оригинальной и сгенерированной спектрограмм. Для количественной оценки использовались нормированные отношения сигнал-шум (NSDR), сигнал-помеха (SIR) и сигнал-артефакт (SAR).

Заключение
Предложенный метод интересен с нескольких точек зрения. Во-первых, было показано, что обучение без учителя может быть применено для решения задач такого типа. Во-вторых, метод может выполнять несколько задач, таких как поиск областей изображения, в которых генерируется звук, и разделение входных звуков на набор компонент, генерирующихся в каждом пикселе. Наконец, это одно из первых исследований, в котором исследуется взаимосвязь между одиночными пикселями и звуком в видео.