Исследователи из CUHK, NUS, University of Oxford и Video Rebirth представили Video Reality Test — первый бенчмарк, который проверяет, могут ли современные AI-модели создавать видео, неотличимые от настоящих. В отличие от тестов, проверяющих физическую достоверность, этот бенчмарк напрямую отвечает на вопрос: настоящее это видео или сгенерированное? Результаты показывают, что даже самые продвинутые мультимодальные языковые модели (VLM) достигают лишь 76.27% точности в среднем, что далеко от человеческих 89.11%. Проект частично открыт и доступен на официальном Github проекта.

Бенчмарк основан на ASMR-видео (Autonomous Sensory Meridian Response), потому что они требуют идеальной синхронизации звука и видео. Малейшие артефакты мгновенно разрушают погружение, что делает ASMR идеальной площадкой для проверки реализма.
Как устроен Video Reality Test
Исследователи собрали 1,400 популярных ASMR-видео с YouTube (более 900 тысяч просмотров) и отобрали 149 репрезентативных образцов. Высокая популярность служит индикатором качества — если видео набрало много просмотров, значит оно успешно вызывает сенсорный отклик. Каждое видео проходило обработку: разделение на сегменты, удаление фона и водяных знаков, извлечение первого кадра, генерация описания через Gemini-2.5-Pro, кластеризация через Qwen3-embedding-4B.

Видео разделены на два уровня: легкие (49 видео) — короткие клипы 3-5 секунд с одношаговым действием на однородном фоне; сложные (100 видео) — до 20+ секунд с многошаговыми действиями, разнообразными фонами и материалами (твердые и жидкие).
В отличие от других бенчмарков с фиксированным набором, Video Reality Test использует динамический подход. Модели генерации видео (VGM) сами создают фейковые образцы, превращая бенчмарк в непрерывную арену размером 149 × (1 + K), где K — количество генеративных моделей.
Peer-Review: модели соревнуются друг с другом
Исследователи ввели методологию Peer-Review (взаимное рецензирование). VGM выступают как «создатели», пытаясь обмануть «рецензентов», а VLM — как «рецензенты», выявляющие подделки. Для рецензентов вычисляется точность AccU, для создателей — показатель FakenessG (процент распознанных фейков). Чем ниже FakenessG, тем реалистичнее генератор. Чем выше AccU, тем лучше детектор.
Результаты VLM
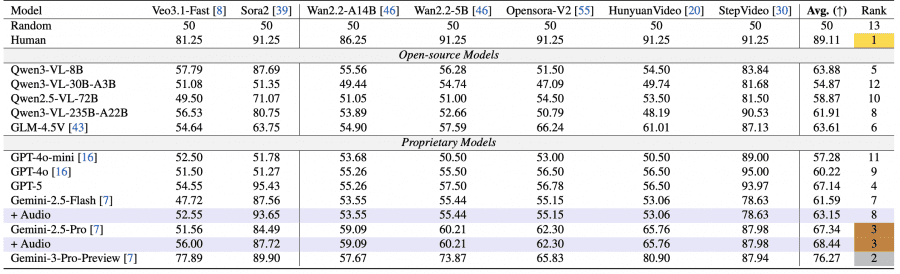
Протестировали 11 моделей: проприетарные Gemini-2.5-Pro/Flash, GPT-4o/4o-mini, GPT-5 и опенсорсные Qwen и GLM. Gemini-3-Pro достиг 76.27%, Gemini-2.5-Pro — 67.34%. Люди успешно распознали AI-видео в 89.11% случаев. Большинство опенсорсных моделей оказались значительно слабее — Qwen3-VL-30B-A3B всего 54.87%, едва выше случайного (50%).
Самый интересный результат: лучший генератор Veo3.1-Fast обманул даже Gemini-2.5-Pro, который распознал только 56% его видео (при случайных 50%). Это на 25% ниже человеческой точности в 81.25%.
Выявлена систематическая ошибка VLM в сторону классификации как настоящих. Gemini-2.5-Pro на 100 реальных и 100 фейковых видео от Wan2.2 классифицировал 71% всех видео как настоящие и только 29% как фейковые. Qwen2.5-VL-7B все сгенерированные Wan видео ошибочно определил как реальные.
Результаты VGM
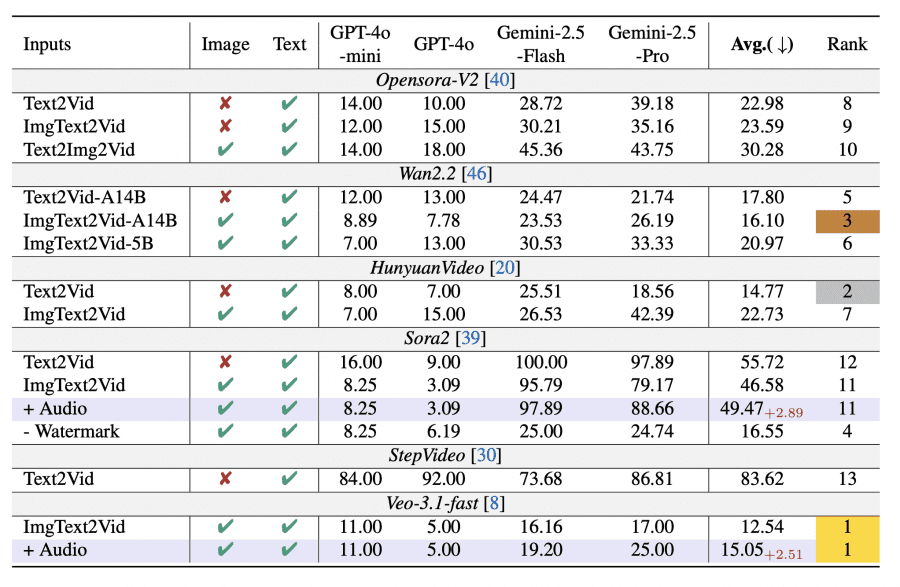
Тестировали восемь генераторов: Wan2.2, OpenSora-V2, HunyuanVideo, StepVideo, Sora2, Veo3.1-fast. Лучшим оказался Veo3.1-Fast — только 12.54% его видео распознали как фейковые. На втором месте HunyuanVideo-I2V (14.77%) и Wan2.2-A14B (16.10%), что показывает сокращение разрыва между проприетарными и открытыми моделями.
Sora2 без водяного знака (16.55%) показал результат на 30 п.п. лучше, чем с ним (46.58%). С водяным знаком Sora2 занял 11-12 места, после удаления поднялся на 4-е. Размер модели важен: Wan2.2-A14B (14B параметров) превзошел Wan2.2-5B — 16.10% против 20.97%.
Роль аудио
Добавление аудио улучшило детекцию у топовых моделей. Для Gemini-2.5-Flash точность выросла с 61.59% до 63.15% (+1.56 п.п.), для Gemini-2.5-Pro — с 67.34% до 68.44% (+1.1 п.п.). Это связано с плохой синхронизацией звука в сгенерированных видео. Sora2 генерирует человеческие голоса вместо непрерывных ASMR-звуков, что создает несоответствие. Veo3.1-Fast лучше справляется с генерацией специфичных звуков без речи, но добавление аудио все равно увеличило вероятность его обнаружения с 12.54% до 15.05% (+2.51 п.п.).
Проблема водяных знаков
Обнаружена критическая уязвимость VLM — зависимость от водяных знаков. На видео Sora2 с водяным знаком топовые VLM показали аномально высокую точность: Gemini-2.5-Flash — 93.65%, GPT-5 — 95.43%, даже относительно слабая Qwen3-VL-8B достигла 87.69%. На других генераторах без знаков те же модели показывали около 55%.
После удаления водяного знака производительность рухнула. GPT-4o почти не изменился (51.8% → 52.8%), но GPT-5 обвалился с 95.4% до 53.4% (-42 п.п.), Gemini-2.5-Pro с 84.5% до 56.0% (-28.5 п.п.), Gemini-2.5-Flash с 87.6% до 52.6% (-35 п.п.). Анализ reasoning-процесса показал, что Gemini и GPT-5 явно упоминают водяной знак в рассуждениях и классифицируют видео как фейк на его основе, игнорируя визуальное качество. GPT-4o не демонстрирует такого поведения. Это означает, что высокая точность достигается за счет поверхностных признаков (shortcuts), а не понимания перцептивной достоверности.
Типичные ошибки генераторов
Анализ провалов выявил четыре основных паттерна ошибок VGM: битые или пустые файлы (17.6%), незавершенная работа — например, видео длиной 8 секунд вместо 8 минут (35.7%), низкое качество — примитивная графика из базовых геометрических форм, роботизированная озвучка (45.6%), несогласованность частей видео — например, 3D-рендеры одного здания с разных ракурсов показывали несовместимые архитектурные детали (14.8%).
Большинство провалов связано с отсутствием у моделей способности проверять собственную работу (self-verification). Особенно это заметно в задачах, требующих сложной визуальной валидации: архитектурное проектирование, разработка игр, веб-дизайн. Генератор может создать 3D-модель дома или интерактивную игру, но не понимает, когда результат работает некорректно или выглядит неестественно.
При этом небольшое количество задач AI выполнил хорошо. Это преимущественно творческие задачи: редактирование аудио (создание звуковых эффектов, разделение вокала и музыки), генерация рекламных изображений и логотипов, написание отчетов, создание простых интерактивных дашбордов с визуализацией данных.
Сравнение с другими бенчмарками
В отличие от существующих бенчмарков для генерации видео (VBench, VideoPhy) и понимания видео (SEED-Bench, MV-Bench), Video Reality Test — это первый унифицированный бенчмарк, содержащий реальные и фейковые пары видео с аудио, предназначенный для одновременной оценки как VLM, так и VGM. Бенчмарк использует мультимодальные входные данные (текст, изображение, аудио) и вводит новую парадигму оценки Peer-Review, где генераторы и детекторы соревнуются друг с другом.
Существующие бенчмарки детекции AIGC (GenVideo, LOKI, IPV-Bench) оценивают только модели понимания, но не генерации. Video Reality Test заполняет этот пробел, предоставляя динамическую арену, где качество генераторов измеряется их способностью обмануть детекторы, а качество детекторов — способностью выявлять подделки.
Выводы
Главный вывод исследования: несмотря на впечатляющую производительность AI на академических тестах знаний и логики, до реального понимания перцептивной достоверности и создания неотличимого от реальности контента моделям еще очень далеко. Лучший генератор Veo3.1-Fast снижает точность сильнейшего рецензента Gemini-2.5-Pro до 56% (при случайных 50%), что на 25% ниже человеческого уровня.
Video Reality Test выявил три критические проблемы современных VLM: зависимость от поверхностных признаков (водяные знаки) вместо анализа качества, систематическую ошибку в сторону классификации видео как настоящих, и ограниченную способность использовать аудио-визуальную согласованность для детекции. Датасет планируют расширять новыми проектами, а код и примеры доступны на официальном сайте проекта для всех желающих протестировать свои модели.