
Пусть у вас есть фото Хью Джекмана для рекламы. Хью выглядит прекрасно, но клиент хочет чтобы он был повеселее. Нет, вам не нужно звать Хью для еще одной фотографии и даже не нужно тратить несколько часов в Photoshop. Вы можете автоматически сгенерировать дюжину изображений, где Хью по-разному улыбается из одной фотографии. Вы даже можете создать анимацию из этой фотографии, где выражение лица знаменитости меняется от очень серьезного дo абсолютного счастья.
Авторы новой настройки GAN (Generative adversarial network), основанной на аннотации Action Units (AU), утверждают, что такой сценарий не является футуристическим, а абсолютно реален на сегодняшний день. И в этой статье мы рассмотрим их подход, посмотрим на результаты, полученные с помощью предлагаемого метода, и сравним его производительность с самыми современными подходами. Исследователи из Барселоны, во главе с Альбертом Пумарола, решили превзойти результаты генеративной нейросети StarGAN.
Предложенный метод
Выражение лица — результат комбинации скоординированных действий лицевых мышц. Их можно описать в терминах так называемых Action Units, которые анатомически связаны с сокращениями конкретных лицевых мышц. Например, выражение лица для страха обычно сопровождается следующими движениями: поднятие внутренней части брови (AU1), поднятие внешней части брови (AU2), опускание бровей (AU4), поднятие верхнего века (AU5), сужение век (АU7), сжимание губ (AU20) и отвисание челюсти (AU26). Величина каждого AU зависит от силы эмоции.
Основываясь на этом подходе к определению выражений лица, Пумарола и его коллеги предлагают архитектуру GAN, которая обусловлена одномерным вектором, указывающим наличие или и величину каждого Action Unit. Обучают сеть без учителя, что требует только изображения с активированными AU. Затем задачу делится на два основных этапа:
- Рендеринг нового изображения с желаемым выражением, используя двунаправленную состязательную архитектуру с поддержкой AU, снабженную одной обучающей фотографией;
- Отображение синтезированного изображения в исходную позу.
Более того, исследователи хотели убедиться, что сеть сможет обрабатывать изображения с различным фоном и условиями освещения. Для этого они добавили новый параметр — “внимание”. Он фокусирует действие сети только на тех областях изображения, которые имеют отношение к передаче нового выражения лица.
Давайте перейдем к следующему разделу, чтобы узнать подробности этой сетевой архитектуры — как успешно создаются анатомически верные анимаций лица из реальных данных?
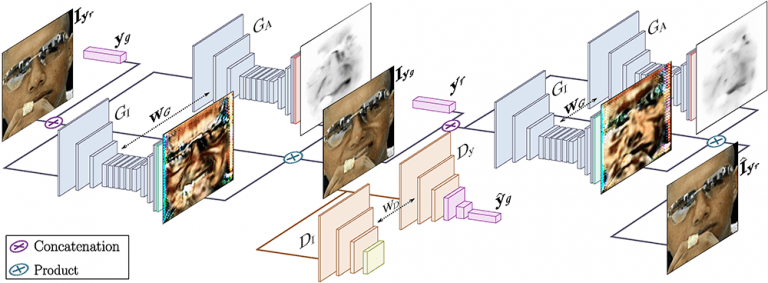
Архитектура сети
Предлагаемая архитектура состоит из двух основных блоков:
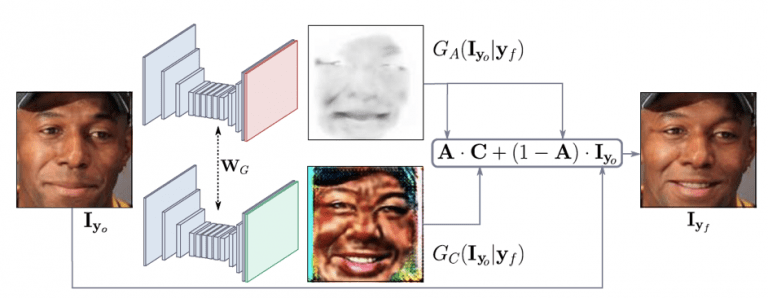
- Генератор G регрессирует “внимание” и цветные маски (обратите внимание, что он применяется дважды, сначала для отображения входного изображения, а затем для его возврата). Цель заключалась в том, чтобы генератор фокусировался только на те области, которые отвечают за синтез нового выражения лица, сохраняя при этом оставшиеся элементы изображения, такие как волосы, очки, шляпы или драгоценности нетронутыми. Таким образом, вместо регрессии полного изображения этот генератор выводит цветовую маску C и маску внимания A. Маска A указывает, в какой степени каждый пиксель C вносит вклад в выходное изображение. Это приводит к более резким и реалистичным изображениям в конце.

Генератор с параметром «внимание» - Условный критик. Критик D оценивает сгенерированное изображение в его выполнении фотореализма и выражении.
Функция потерь для этой сети представляет собой линейную комбинацию нескольких частичных потерь: потери “внимания”, потери условного выражения, потеря идентичности, состязательные потери.
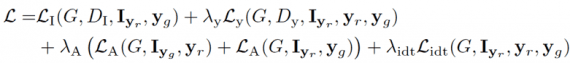
Модель обучается на подмножестве 200 000 изображений из набора данных EmotioNet с использованием оптимизатора Adam с частотой обучения 0,0001, бета1 0,5, бета2 0,999 и размером выборки 25.
Качественная оценка
На изображении ниже демонстрируется способность модели активировать AU с разной интенсивностью, сохраняя при этом личность человека. Например, вы можете видеть, что модель правильно обрабатывает случай с нулевой интенсивностью и генерирует идентичную копию входного изображения. Для ненулевых случаев модель реалистично создает сложные лицевые движения и выводит изображения, которые обычно неотличимы от реальных.

Следующий рисунок отображает маску внимания A и цветную маску C. Вы можете видеть, как модель фокусирует свое внимание (более темную область) на соответствующих action units неконтролируемым образом. Следовательно, тщательно оцениваются только пиксели, относящиеся к изменению выражения, тогда как фоновые пиксели непосредственно копируются из входного изображения. Эта особенность модели очень удобна при работе с реальными данными.

Теперь посмотрим, как модель обрабатывает задачу редактирования нескольких AU. Результаты показаны ниже. Здесь вы можете наблюдать гладкое и последовательное преобразование между кадрами даже при сложных условиях освещения и данных из нереального мира, как в случае с Аватаром.
Такие результаты побуждают авторов расширять свою модель до генерации видео. Они должны обязательно попробовать, не так ли?

Сравнение с другими подходами
Насколько же лучше данный подход в сравнение с другими? Результаты показаны ниже. Похоже, что нижняя строка, представляющая предлагаемый подход, содержит гораздо более визуально привлекательные изображения с заметно более высоким пространственным разрешением. Как уже говорилось ранее, использование маски внимания позволяет применять преобразование только на обрезанной грани и помещать его обратно на исходное изображение без создания артефакта.

Ограничения модели
Давайте теперь обсудим ограничения модели — какие типы сложных изображений она все еще может обрабатывать, а когда терпит крах. Как показано на изображении ниже, модель преуспевает при работе с человекоподобными скульптурами, нереалистичными рисунками, неоднородными текстурами на лице, антропоморфными гранями с нереальными текстурами, нестандартными иллюминациями и цветами и даже эскизами лица.
Однако есть несколько случаев, когда она терпит неудачу. Первая неудача, изображенная ниже, является результатом ошибок в механизме внимания при использовании крайних входных выражений. Модель также может потерпеть неудачу, когда входное изображение содержит ранее невидимые окклюзии, такие как глазная повязка, вызывающее артефакты в отсутствующих атрибутах лица. Он также не готов рассматривать нечеловеческие антропоморфные распределения, как в случае циклопов. Наконец, модель может также генерировать артефакты, такие как человеческие особенности лица, когда речь идет о животных.

Выводы
Представленная здесь модель способна генерировать анатомически-верные анимации лица из реальных изображений. Полученные изображения удивляют их реализмом и высоким пространственным разрешением. Подход продвигает текущие работы, которые касались только проблемы редактирования категорий дискретных эмоций и портретных изображений. Ключевыми его вкладами являются:
а) кодирование деформаций лица с помощью AU для визуализации широкого спектра выражений и
б) внедрение модели внимания для фокусировки только на соответствующие области изображения.
Случаи сбоев, предположительно, связаны с недостаточными данными для обучения. Таким образом, мы можем заключить, что результаты этого подхода очень перспективны, и мы с нетерпением ждем его результатов для видео.



