Google представила AudioPaLM — большую языковую модель для обработки и генерации речи, объединяющую две языковые модели от Google — PaLM-2 и AudioLM — в мультимодальную архитектуру. Модель умеет распознавать речь, копировать интонацию, акцент, выполнять перевод речи на другие языки на основе короткой голосовой подсказки и делать транскрипцию.
AudioPaLM унаследовала от AudioLM возможности идентификации говорящего и копирования интонации, от PALM-2 — лингвистические способности LLM. Эксперименты показали, что инициализация AudioPaLM c весами текстовой модели, полученными на предварительном обучении, заметно улучшает обработку речи. Результирующая модель превосходит state-of-the-art модели перевода речи и способна выполнять перевод речи в текст для языков, комбинации которых не были учтены при тренировке (zero-shot перевод).
Описание модели
Схема иллюстрирует работу модели AudioPaLM в задачах перевода речи-на-речь и автоматического распознавания речи:
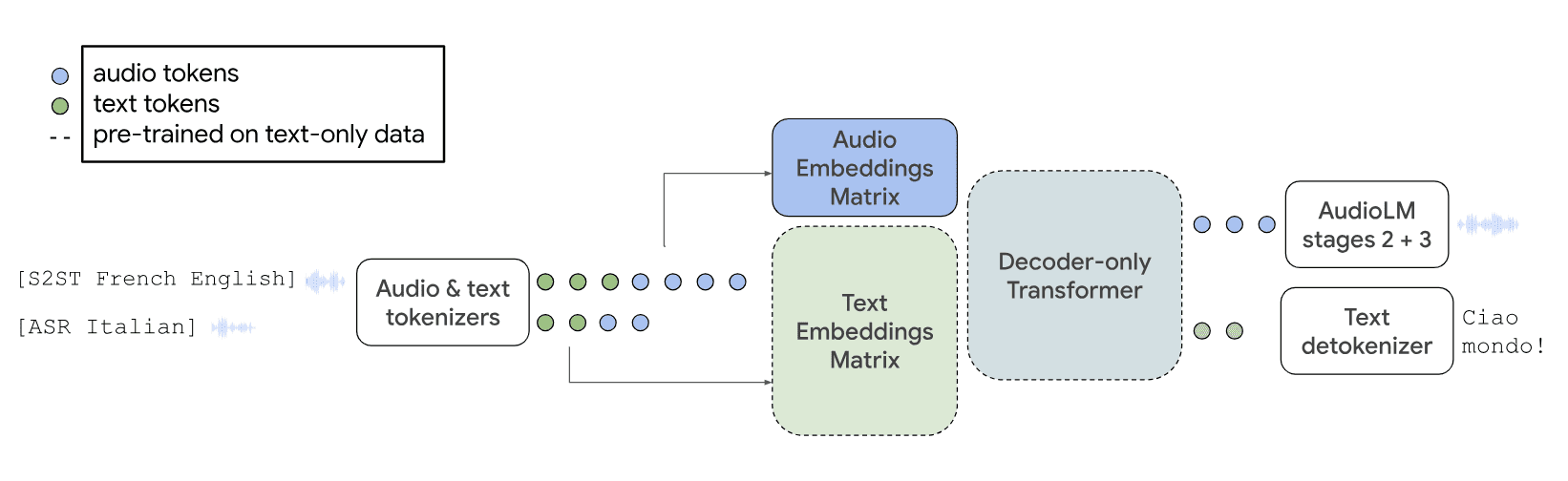 Матрица эмбеддингов предварительно обученной текстовой модели (пунктирные линии) используется для моделирования набора аудио-токенов. Архитектура модели в остальном остается неизменной: на вход подается смешанная последовательность текстовых и аудио-токенов, и модель декодирует эти токены в текст или аудио. Аудио-токены в дальнейшем преобразуются обратно в исходное аудио с использованием слоев модели AudioLM.
Матрица эмбеддингов предварительно обученной текстовой модели (пунктирные линии) используется для моделирования набора аудио-токенов. Архитектура модели в остальном остается неизменной: на вход подается смешанная последовательность текстовых и аудио-токенов, и модель декодирует эти токены в текст или аудио. Аудио-токены в дальнейшем преобразуются обратно в исходное аудио с использованием слоев модели AudioLM.
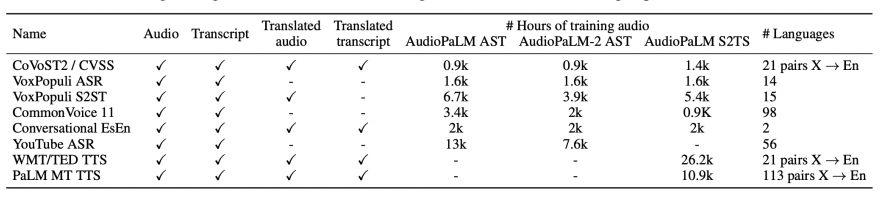
Датасеты, на которых обучалась модель:
Результаты
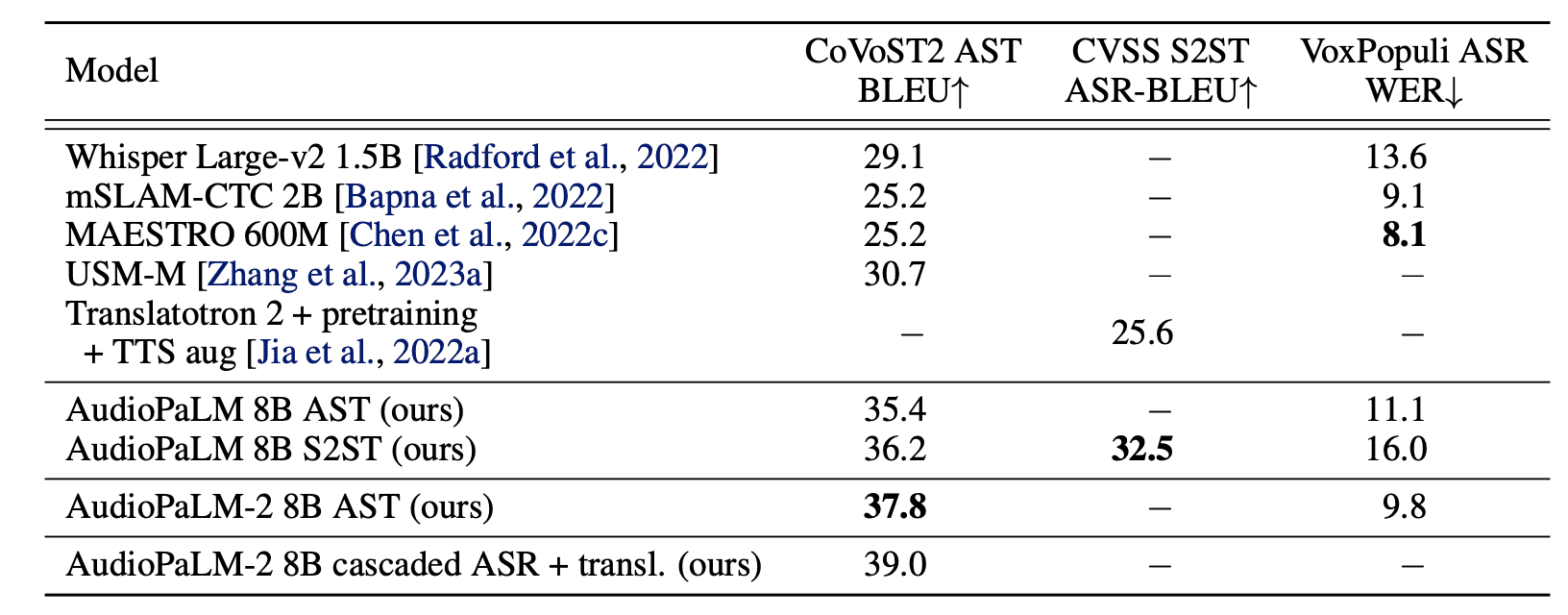
Исследователи оценили работу модели на бенчмарках CoVoST2 AST BLEU, CVSS S2ST ASR-BLEU, VoxPopuli ASR VER, сравнив результаты с другими современными моделями.
Другие примеры работы модели, эксперименты с разными языками, создания транскрипций доступны на странице-презентации модели.