CSTR — это сверточная нейросеть, которая распознает текст на изображениях сцены. Превалирующая часть предыдущих работ рассматривает задачу распознавания текста на изображении сцены как задачу сегментации и seq2seq. Предложенная модель решает задачу распознавания текста как задачу классификации изображений. По результатам экспериментов на 6 датасетах, модель выдает сравнимые с state-of-the-art подходами результаты. Код проекта доступен в открытом репозитории на GitHub.
Подробнее про структуру модели
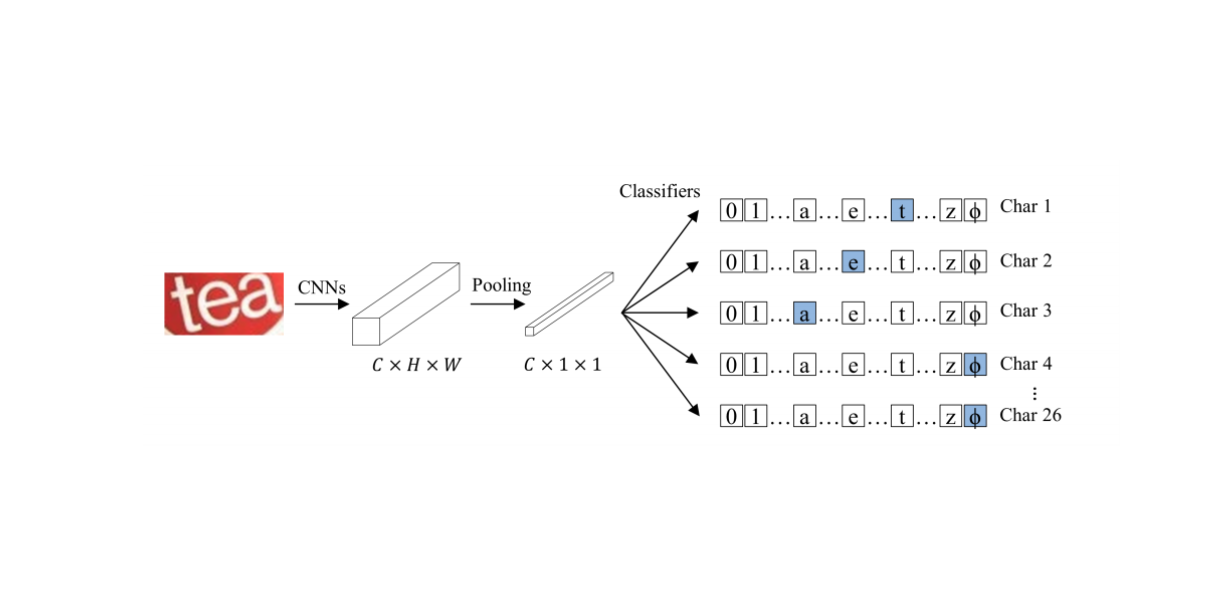
CSTR состоит из набора сверточных слоев и слоя глобального усредненного пулинга (global average pooling layer) в конце. За слоем пулинга следуют модули для мультиклассовой классификации, каждый из которых предсказывает соответствующую букву из текстовой последовательности на входном изображении.
В качестве функционала ошибки CSTR используют параллельную кросс-энтропию. Архитектура CSTR сравнима по легкости имплементации с моделями классификации изображений, как ResNet.
Тестирование модели
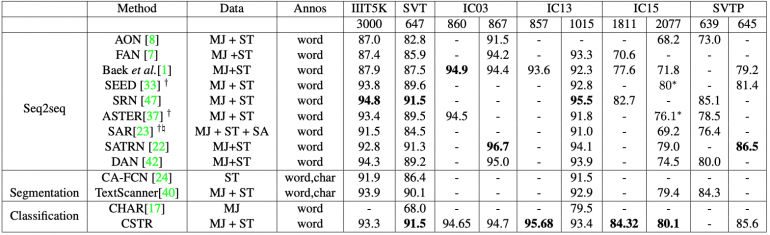
Работу модели тестировали на датасетах ICDAR 2003 (IC03), ICDAR 2013 (IC13), ICDAR 2015 (IC15), IIIT 5K-Words (IIIT5k), Street View Text (SVT) и Street View Text-Perspective (SVTP). Все датасеты состояли из изображений сцен, на которых были вывески с текстом латиницей. Ниже видны результаты тестирования.