Исследователи из HKUST, Ant Group, Zhejiang University и Northeastern University представили Ditto — комплексный открытый фреймворк для решения проблемы дефицита обучающих данных в редактировании видео по текстовым инструкциям. Разработчики создали пайплайн синтеза данных, с помощью которого построили датасет Ditto-1M, содержащий более миллиона видео. На этом датасете обучена модель Editto, которая выполняет как глобальное редактирование стиля, так и точечные локальные модификации — замену объектов, изменение их атрибутов, добавление и удаление элементов. Пайплайн генерирует видео длиной 101 кадр при разрешении 1280×720. Код, данные и модель доступны на Github, веса — на HuggingFace.
Возможности модели Editto
Editto выполняет редактирование видео по инструкциям, обрабатывая три входа: текстовую инструкцию, описывающую желаемое редактирование, исходное видео и информацию о глубине для структурного руководства. Модель обрабатывает разнообразные сценарии редактирования, включая style-transfer (аниме, пиксель-арт, киберпанк), замену объектов, модификацию атрибутов и сложные трансформации сцен.
Построенная на базе in-context видео генератора VACE с Wan2.2 в качестве базовой модели, Editto генерирует видео с разрешением 1280×720 и 101 кадром при 20 FPS. Архитектура включает Context Branch, извлекающую пространственно-временные признаки, и DiT-based Main Branch, которые выдает финальный результат. Через механизмы внимания модель последовательно распространяет редактирование на все кадры, сохраняя оригинальную динамику движения и структуру сцены.
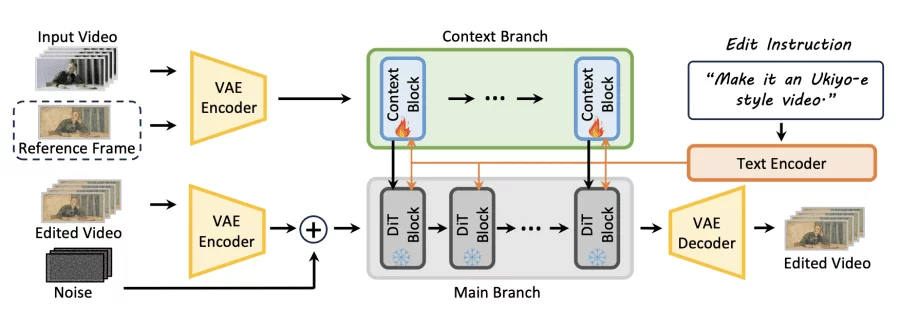
Обучение применяло стратегию modality curriculum learning на протяжении 16,000 шагов на 64 NVIDIA H-series GPU. На начальном этапе модель обучается с текстовыми инструкциями и визуальными референсными кадрами. Постепенно визуальное руководство уменьшается и в конечном итоге удаляется, что позволяет модели выполнять редактирование исключительно на основе текстовых описаний. Дообучаются только linear projection слои context blocks, что сохраняет сильные генеративные способности предобученной базовой модели.
Датасет Ditto-1M
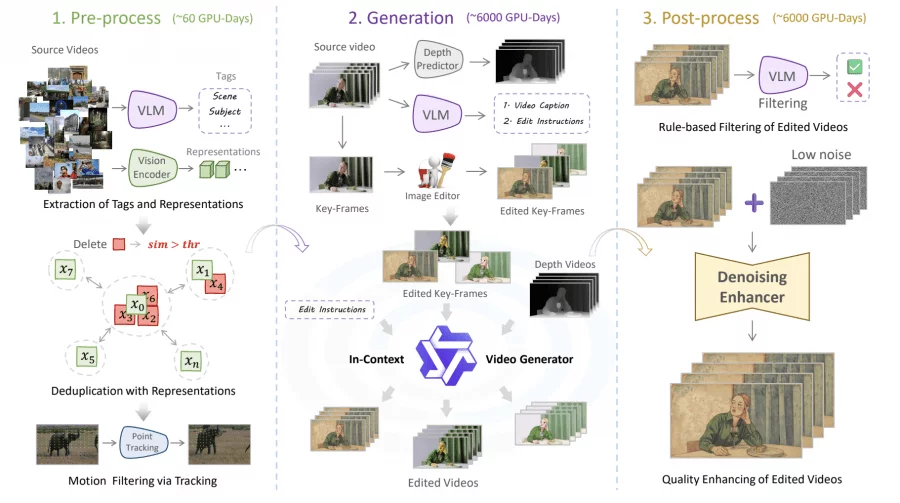
Создание Ditto-1M потребовало более 12,000 GPU-дней и включало три этапа. На препроцессинге (60 GPU-дней) из более 200,000 видео платформы Pexels, содержащей профессиональный контент, автоматически отбираются подходящие: visual encoder DINOv2 удаляет дубликаты через вычисление попарного сходства векторов признаков, а CoTracker3 отслеживает точки на сетке и вычисляет среднее кумулятивное смещение для оценки качества движения — статичные видео с низкой оценкой отфильтровывались.
На этапе генерации (6,000 GPU-дней) VLM-агент создаёт описания и инструкции редактирования, модель редактирования изображений генерирует отредактированный ключевой кадр, извлекается глубина видео. In-context генератор синтезирует отредактированное видео, используя дистиллированную модель для снижения затрат до 20%. На постпроцессинге (6,000 GPU-дней) VLM-фильтр оценивает качество по четырём критериям, а denoiser выполняет пошаговое улучшение текстур.
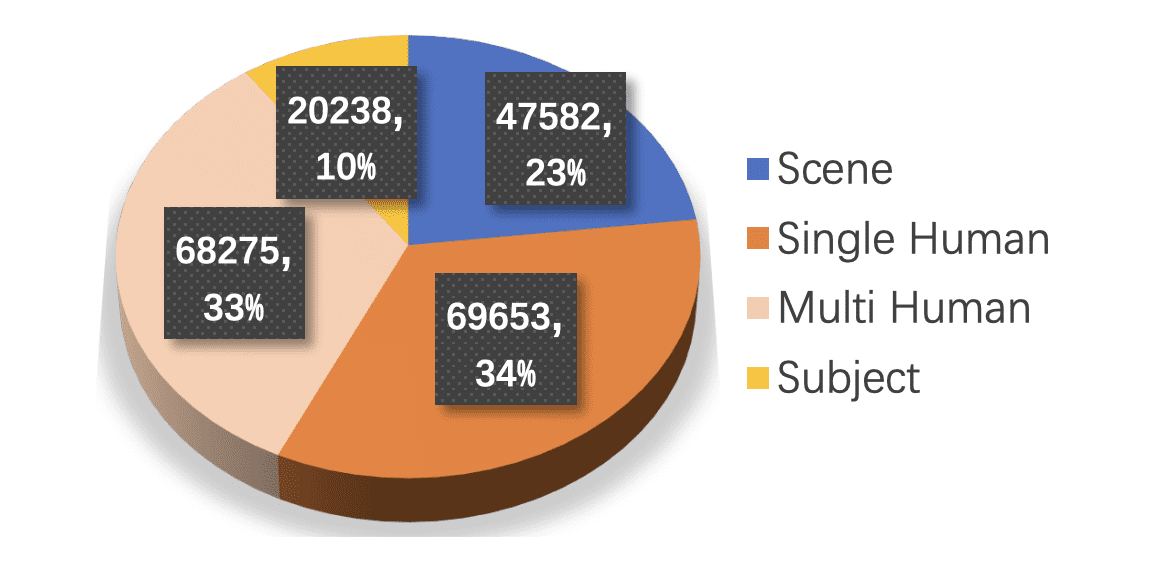
Финальный датасет содержит более 1 миллиона видео 1,280×720 с 101 кадром при 20 FPS: 700,000 примеров глобального редактирования и 300,000 локального. Распределение: 23% сцен, 34% активностей одного человека, 33% групповых активностей, 10% объектов.
Результаты производительности
Editto достигает state-of-the-art результатов по всем метрикам оценки. CLIP-T 25.54 против 23.56 у InsViE, что указывает на более точное следование инструкциям. CLIP-F достигает 99.03 (против 98.78), демонстрируя превосходную темпоральную согласованность. Холистическая VLM оценка 8.10 против 7.35 подтверждает комплексное улучшение качества.

Человеческая оценка с 1000 рейтингами показывает существенное предпочтение Editto: Edit-Acc 3.85 против 2.28 у InsViE за следование инструкциям, Temp-Con 3.76 (против 2.30) за плавность и согласованность кадров, и Overall 3.86 против 2.36 за общее качество. Пользователи последовательно оценивали результаты Editto как более точно следующие инструкциям при сохранении лучшей согласованности кадров.
Качественные сравнения демонстрируют преимущества Editto. Для сложных стилизаций, таких как пиксель-арт или LEGO-трансформации, модель генерирует чистые, согласованные результаты по всем кадрам, в то время как конкуренты производят размытые или темпорально нестабильные результаты. Для локальных редактирований, таких как изменение цвета одежды, Editto точно модифицирует целевые объекты, сохраняя идентичность субъекта и точность фона. Baseline методы либо не выполняют редактирование, либо вносят нежелательные изменения в другие элементы сцены.
Абляционные исследования подтверждают, что производительность масштабируется с размером датасета, с видимыми улучшениями от 60K до 500K примеров. Modality curriculum learning оказывается критичным — без него модель испытывает трудности с интерпретацией абстрактных текстовых описаний и производит редактирования, лишь частично соответствующие инструкциям. Обученная модель также демонстрирует способность synthetic-to-real, успешно возвращая стилизованные видео к фотореалистичным оригиналам, что указывает на устойчивое понимание как стилистических трансформаций, так и характеристик естественного видео.
Ditto включает практическое редактирование видео по инструкциям через масштабируемый синтез данных, производящий высококачественные, разнообразные обучающие примеры. Комбинация автоматизированной генерации инструкций, мультимодального визуального руководства и интеллектуального контроля качества создает датасет, поддерживающий обучение моделей, способных выполнять сложные операции редактирования из простых текстовых описаний при сохранении темпоральной когерентности на протяженных видео последовательностях.