Команда исследователей из Пекинского университета и ByteDance опубликовала Helios — авторегрессионную диффузионную трансформер-модель на 14 миллиардов параметров, которая генерирует видео со скоростью 19,5 кадров в секунду на одной видеокарте NVIDIA H100. Это в 128 раз быстрее базовой модели Wan-2.1 и сравним по скорости с рядом дистиллированных 1,3B-моделей. При этом модель поддерживает генерацию видео длиной в несколько минут без деградации качества — то, с чем не справляются большинство существующих решений.
Проект полностью открытый: авторы опубликовали, код на GitHub, а также демо и веса всех трёх версий на HuggingFace:
- Helios-Base (14B) — базовая версия с максимальным качеством и 50 шагами сэмплирования;
- Helios-Mid (14B) — с агрессивным сжатием токенов для ускорения в ~2 раза при небольшой потере качества;
- Helios-Distilled (14B) — дистиллированная версия всего с 3 шагами сэмплирования и скоростью 19,5 FPS в реальном времени.
В тот же день вышла нативная поддержка в Diffusers, vLLM и SGLang. Также выпущен бенчмарк HeliosBench с 240 промптами, охватывающий четыре диапазона длительности — от 81 до 1440 кадров — для оценки моделей генерации длинных видео.
Зачем нужна генерация видео в реальном времени?
Большинство современных моделей — от Wan 2.1 до HunyuanVideo — работают медленно. Wan 2.1 14B тратит около 50 минут на одну 5-секундную видеозапись на видеокарте A100. Это катастрофически медленно для интерактивных приложений — игровых движков, интерактивных миров, инструментов для творчества в реальном времени.
Для реального применения нужны модели, которые генерируют видео быстрее, чем оно воспроизводится.
Существующие попытки решить эту задачу — Self-Forcing, Rolling Forcing, Krea-RealTime — либо построены на маленьких моделях (1,3B параметров), которым не хватает качества, либо не справляются с накоплением ошибок при длинных видео.

Три главные проблемы, которые решает Helios
Проблема 1: накопление ошибок (drifting) в длинных видео. Когда авторегрессионная модель генерирует видео по кускам — каждый новый фрагмент на основе предыдущего — со временем накапливаются ошибки. Цвета начинают «плыть», объекты меняют форму, появляются артефакты размытия. Авторы выделили три вида такой деградации: сдвиг позиции (position shift), сдвиг цвета (color shift) и сдвиг восстановления (restoration shift).

Проблема 2: скорость. Генерировать 14-миллиардную модель быстро — казалось бы, невозможно без KV-cache, квантования или sparse attention. Helios обходится без этих техник.
Проблема 3: память при обучении. Стандартное обучение 14B-модели требует сложной инфраструктуры параллелизма (CP, TP, FSDP, DeepSpeed). Helios спроектирован так, что полный forward и backward pass умещается на одном GPU без parallelism и sharding — это достигается за счёт агрессивного сжатия токенов, при котором 14B-модель по потреблению памяти становится сравнима с моделями генерации изображений. Реальное обучение всех трёх стадий при этом проводилось на 64–128 NVIDIA H100.
Как устроена архитектура Helios
В основе Helios лежит Unified History Injection — способ превратить двунаправленную предобученную модель (Wan-2.1) в авторегрессионный генератор без потери качества. Идея простая: модель всегда получает два куска видео одновременно — уже сгенерированные чистые кадры (исторический контекст) и зашумлённый фрагмент, который нужно сгенерировать следующим. Задача модели — убрать шум из второго куска, опираясь на первый.
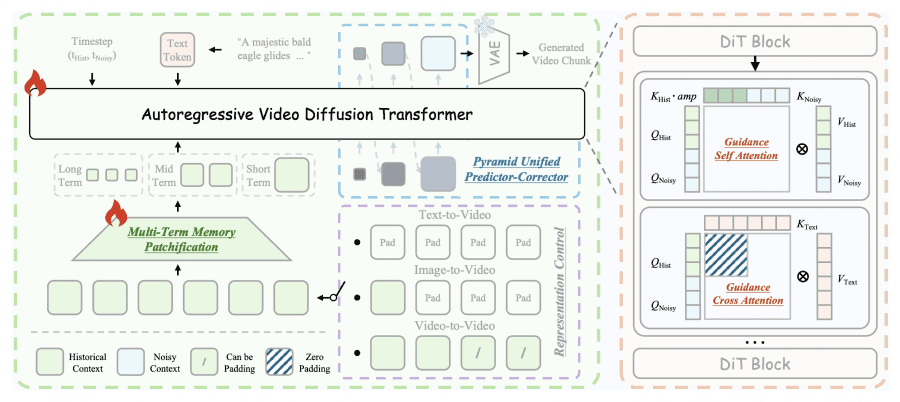
Чтобы история действительно помогала генерации, а не мешала, авторы придумали Guidance Attention. В механизме self-attention ключи исторического контекста умножаются на обучаемые коэффициенты усиления — отдельные для каждой головы внимания. Это позволяет модели самой решать, какие части истории важны, а какие стоит проигнорировать. Cross-attention с текстовым промптом применяется только к зашумлённому фрагменту — исторический контекст уже учёл текст на предыдущих шагах, повторно вливать его туда нет смысла.
Отдельный приём — Representation Control. Он позволяет одной архитектуре поддерживать три разных режима работы: если история полностью нулевая, модель работает как text-to-video; если заполнен только последний кадр — как image-to-video; если передано реальное видео — как video-to-video.
Как Helios борется с накоплением ошибок
Авторы предлагают три простых приёма под общим названием Easy Anti-Drifting — без дорогостоящих стратегий вроде self-forcing или error-banks.
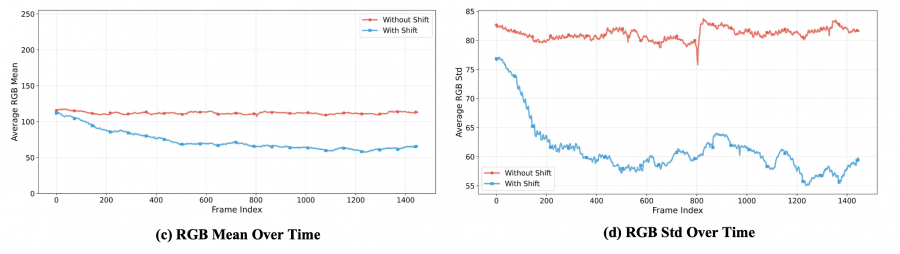
Relative RoPE переосмысляет позиционное кодирование. Обычно при генерации 1440-кадрового видео модель видит абсолютные временные индексы 0–1399, хотя обучалась только на коротких клипах — и просто не знает, как вести себя на таких позициях. Helios решает это просто: исторический контекст всегда получает индексы от 0 до фиксированной границы, а новый генерируемый фрагмент — следующие несколько позиций после неё. Длина видео не важна — окно всегда одно и то же. Это заодно устраняет эффект «зацикливания», когда модель периодически возвращается к одним и тем же движениям из-за математической периодичности RoPE.
First-Frame Anchor — первый кадр всегда остаётся в историческом контексте до конца генерации как глобальный визуальный якорь. Авторы заметили, что деградация цвета почти никогда не начинается с первых кадров — а значит, первый кадр надёжно «помнит», как должна выглядеть сцена.
Frame-Aware Corrupt — во время обучения модель намеренно получает испорченную историю: с разными вероятностями к кадрам добавляется шум, меняется экспозиция или применяется даунсэмплинг. Это учит модель не доверять слепо своим же предыдущим выходам и опираться на более глубокие паттерны, а не на поверхностное сходство с историей.

Как Helios стал быстрым: Deep Compression Flow
Скорость достигается за счёт агрессивного сжатия токенов на двух уровнях.
Multi-Term Memory Patchification делит исторический контекст на три части — краткосрочную, среднесрочную и долгосрочную — и сжимает их с разными коэффициентами. Недавние кадры сохраняют высокое разрешение, давние — сильно сжимаются. Это примерно аналог того, как человек помнит последние события в деталях, а давние — только в общих чертах. В итоге количество токенов истории сокращается примерно в 8 раз, а общий бюджет токенов остаётся постоянным вне зависимости от длины видео — модель может держать сколько угодно длинную историю, не увеличивая вычислительные затраты.
Рисунок 7 (стр. 8 пейпера): Multi-Term Memory Patchification. Левый график — количество токенов; средний — память GPU; правый — время inference. Наивный подход (синий) быстро уходит за OOM; Helios (красный) остаётся стабильным.
Pyramid Unified Predictor Corrector меняет сам процесс диффузионного сэмплирования. Вместо того чтобы сразу работать с полным разрешением, модель начинает с низкого — там определяется грубая структура сцены — и постепенно переходит к высокому, где уточняются детали. Это как сначала набросать эскиз, а потом прорисовать детали. Такой подход сокращает количество токенов для генерируемого фрагмента примерно в 2,3 раза.

Наконец, Adversarial Hierarchical Distillation сокращает число шагов сэмплирования с 50 до 3. Вместо стандартного подхода Distribution Matching Distillation авторы используют в качестве учителя уже готовый авторегрессионный Helios-Base, а не двунаправленную модель. Это позволяет обучить дистиллированную версию без дорогостоящих длинных роллаутов — генерировать во время обучения нужно только один фрагмент за шаг, а не десятки секунд видео подряд.
Результаты
На бенчмарке коротких видео (81 кадр) Helios-Distilled набирает суммарный балл 6,00, превосходя все дистиллированные модели и сравниваясь с базовыми моделями аналогичного размера. При этом скорость — 19,53 FPS на одной H100 — недостижима для конкурентов того же масштаба: FastVideo Wan2.1 и TurboDiffusion работают в 2–3 раза медленнее, а Wan 2.1 14B — в 52 раза медленнее.
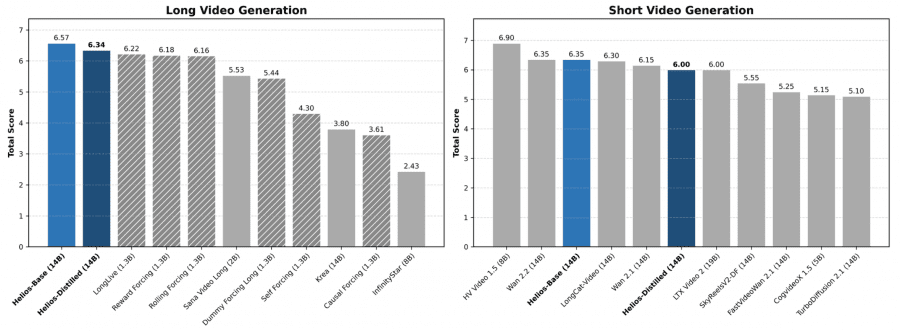
На длинных видео (до 1440 кадров, около 48 секунд) Helios-Distilled набирает 6,94 суммарных балла, опережая лучший аналог Reward Forcing (6,88). Особенно важно, что накопление ошибок у Helios значительно ниже по всем измеренным метрикам — модель сохраняет идентичность сцены и цветовую согласованность на протяжении сотен и тысяч кадров.
Пользовательское тестирование (200 оценщиков, 40 попарных сравнений каждый) подтверждает результаты: Helios побеждает в 70–92,5% случаев против конкурентов по длинным видео и в 56–99,2% — по коротким.
Что было проверено в абляции
Авторы последовательно отключали каждый компонент и фиксировали деградацию. Без First-Frame Anchor суммарный балл падает с 6,47 до 5,51, а без Frame-Aware Corrupt — до 4,70, причём деградация появляется уже на 240-м кадре. Добавление каузальной маски в Guidance Attention полностью дестабилизирует обучение. Замена авторегрессионного учителя на двунаправленный (Wan-2.1) снижает качество дистиллированной модели с 6,34 до 4,75.
Flash Normalization и Flash RoPE — кастомные Triton-ядра для LayerNorm и позиционного кодирования — вместе ускоряют инференс на 14,4% и обучение на 14,5% по сравнению с базовым Wan-2.1.
Ограничения
Авторы честно признают несколько проблем. Все эксперименты ограничены разрешением 384×640 из-за вычислительных ресурсов. На стыках сгенерированных фрагментов иногда появляются мерцающие артефакты — это общая проблема авторегрессионных моделей. Наконец, стандартные метрики вроде Aesthetic и Smoothness слабо коррелируют с человеческим восприятием, что усложняет объективное сравнение. Авторы считают разработку перцептуально выровненных метрик важным направлением для будущих работ.