Команда исследователей из Пекинского авиационного института, Шанхайского транспортного университета, Университета Манчестера и компании IQuest Research опубликовала InCoder-32B-Thinking — языковую модель с расширенной цепочкой рассуждений (chain-of-thought reasoning) для задач разработки кода для чипов, GPU, встраиваемых систем и микроконтроллеров.
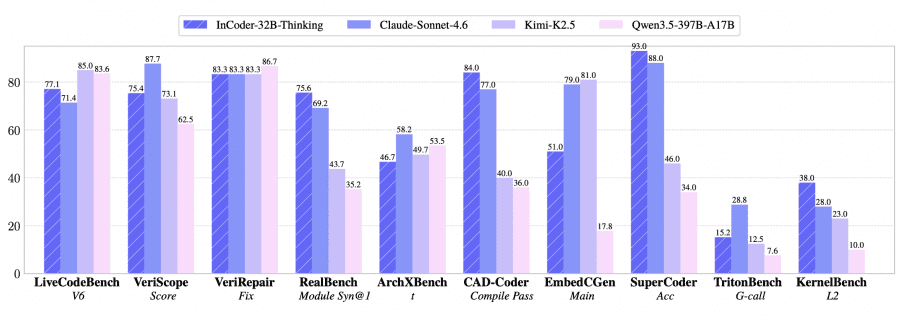
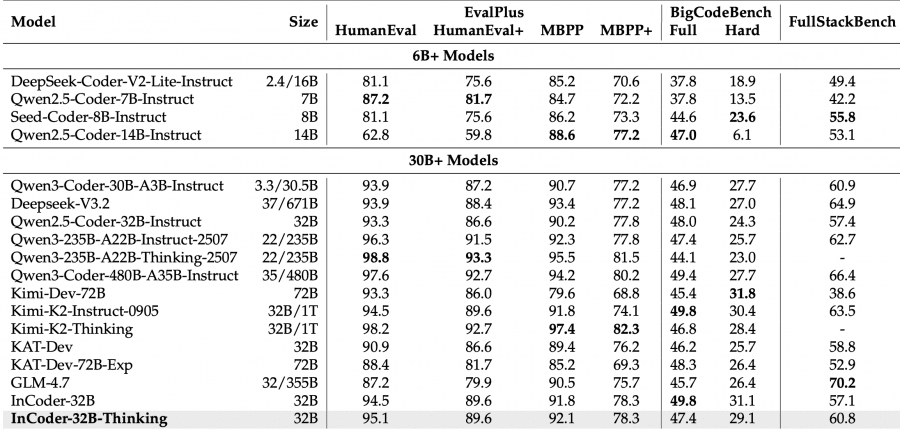
На 14 общих и 9 промышленных бенчмарках модель показала лучшие результаты среди открытых моделей сопоставимого размера: 81.3% на LiveCodeBench V5 и 84.0% по проценту успешной компиляции на CAD-Coder. Проект полностью открытый: веса модели доступны на HuggingFace, код — на GitHub.
В чём проблема с промышленным кодом
Большинство современных LLM хорошо справляются с задачами с LeetCode или написанием веб-сервисов, но в реальном производстве всё сложнее. Код для проектирования чипов на языке Verilog/RTL, CUDA-ядра для GPU или прошивки для микроконтроллеров требуют понимания аппаратных ограничений, семантики таймингов и специфики компиляторных цепочек (toolchains). Из открытых обучающих данных в интернете почти не видно, как опытный инженер рассуждает при отладке такого кода: какие шаги предпринимает, какие ошибки исправляет и почему. Именно это «рассуждение на ошибках» исследователи и попытались синтезировать автоматически.
Два ключевых компонента: ECoT и ICWM
InCoder-32B-Thinking строится на двух взаимодополняющих механизмах.
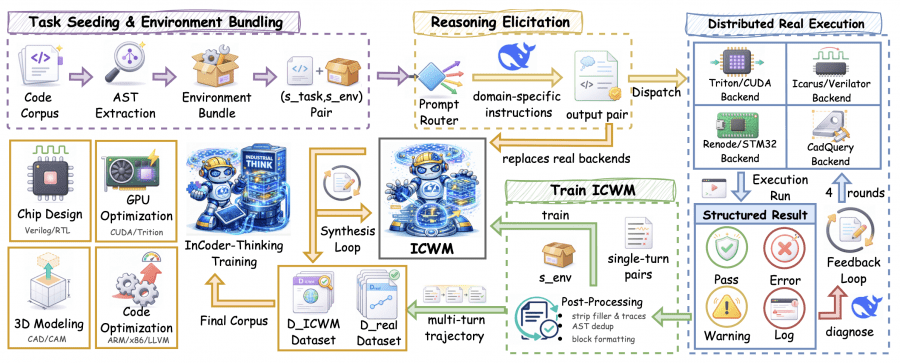
Первый — ECoT (Error-driven Chain-of-Thought, цепочка рассуждений через исправление ошибок). Это фреймворк для синтеза обучающих последовательностей рассуждений. Вместо того чтобы учить модель на просто правильном коде, ECoT генерирует многоходовые диалоги: модель пишет код → код запускается на реальном бэкенде → бэкенд возвращает ошибку → модель анализирует ошибку и исправляет код → и так до 4 итераций. Из такой многоходовой траектории получается связная последовательность рассуждений, где вся история ошибок и исправлений явно зафиксирована.
Второй — ICWM (Industrial Code World Model, модель мира для промышленного программирования). Запускать реальный компилятор Verilog или CUDA-бэкенд на каждую итерацию дорого. ICWM — это языковая модель, обученная предсказывать, что вернёт реальный бэкенд в ответ на данный код в данной среде выполнения. Говоря формально: ICWM(s_env, c^(k)) → ô^(k), где s_env — описание окружения (тестбенч, скрипты компилятора, конфигурация памяти), c^(k) — код на итерации k, ô^(k) — предсказанный результат выполнения. После обучения ICWM берёт на себя роль компилятора — модели больше не нужно каждый раз запускать реальный Verilog или CUDA-бэкенд, чтобы получить обратную связь.
Как устроен пайплайн сбора данных
Для каждой задачи собирается пакет с окружением: Verilog-код идёт вместе с тестами и скриптами компилятора, прошивка для STM32 — с разметкой памяти и нужными хедерами. Перед генерацией лёгкий маршрутизатор промптов (prompt router) выбирает доменно-специфичные инструкции: для GPU-задач модель должна рассуждать о расходе общей памяти (shared memory) и дивергенции warp-ов, для RTL-задач — о глубине комбинационных путей и пересечении тактовых доменов. Генератор (DeepSeek-V3.2) выдаёт пару (рассуждение-код), код идёт на реальный бэкенд, структурированный результат с меткой (PASS / COMPILATION_ERROR / MEMORY_FAULT) и диагностическим логом возвращается обратно. Успешные и неуспешные ходы сохраняются — обе категории нужны для обучения.
Насколько точна ICWM
Ключевой вопрос: можно ли доверять предсказаниям мировой модели настолько, чтобы заменить ею реальный компилятор? Исследователи проверили это на 2000 шагах выполнения по каждому домену.
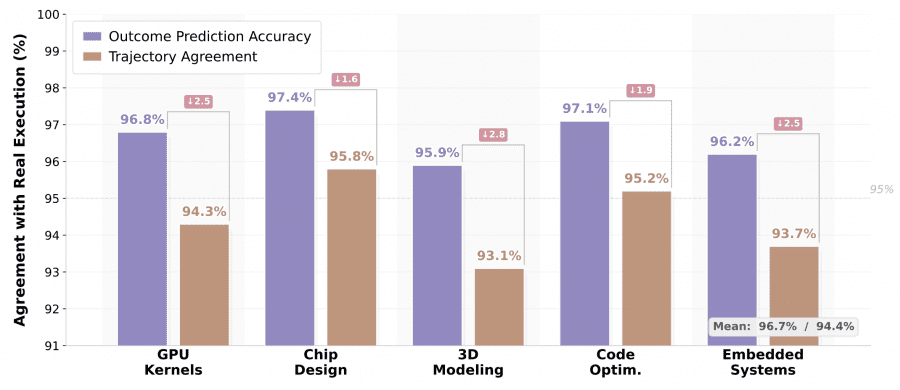
Средняя точность предсказания исхода (outcome prediction accuracy) составила 96.7%, согласованность траекторий (trajectory agreement) — 94.4%. Лучший результат у проектирования чипов: 97.4% / 95.8%, потому что бэкенды Yosys и Icarus возвращают структурированные и предсказуемые диагностические сообщения. Наихудший — у 3D-моделирования: 95.9% / 93.1%, поскольку проверки геометрии в CadQuery зависят от значений с плавающей точкой и неявных булевых операций, предсказать которые по тексту кода сложнее.
Адаптивная глубина рассуждения
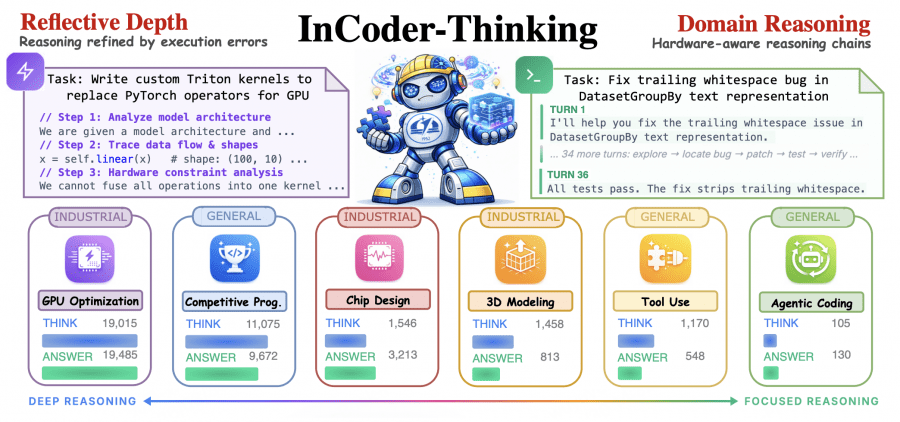
Один из интересных эффектов, который возникает сам по себе без специального программирования, это то, что модель учится тратить ровно столько «токенов размышления», сколько нужно для конкретной задачи.
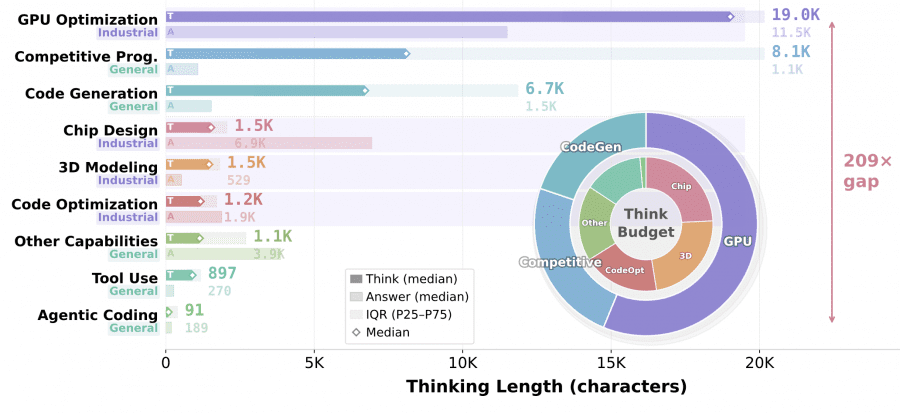
Медианная длина блока <think> варьируется до 209 раз: от 91 символа для агентного программирования до 19 015 символов для GPU-оптимизации. Для агентных задач рассуждение распределено по десяткам шагов диалога, каждый шаг — просто выбор следующего действия. Для GPU-ядер каждый раунд исправления требует диагностики конфигурации grid/block, раскладки разделяемой памяти (shared memory layout) и планирования на уровне warp-ов. Интересный паттерн у проектирования чипов: короткий блок <think> (1.5K символов) и длинный RTL-ответ (6.9K), потому что бэкенд Yosys/Icarus возвращает структурированные диагностики, зато сам код на Verilog объёмный.
Результаты на бенчмарках
На общих бенчмарках генерации кода модель набирает 77.1% на LiveCodeBench V6 и 81.3% на V5 — лучший результат среди открытых dense-моделей сопоставимого размера. Модели с MoE-архитектурой вроде Kimi-K2-Thinking набирают чуть больше — 83.1% на V5, но за счёт на порядок большего числа параметров (1T против 32B).
На промышленных бенчмарках картина убедительнее. На CAD-Coder (3D-моделирование) — 84.0% по проценту успешной компиляции, что лучше Claude Sonnet 4.6 (77.0%). На KernelBench L2 (оптимизация GPU-ядер) — 38.0% против 10.0% у Qwen3.5-397B-A17B, у которого в 12 раз больше параметров. На RealBench (проектирование чипов, модульный уровень) — 75.6% Syn@1, тогда как у ближайшего открытого конкурента Kimi-K2-Instruct — 50.1%.
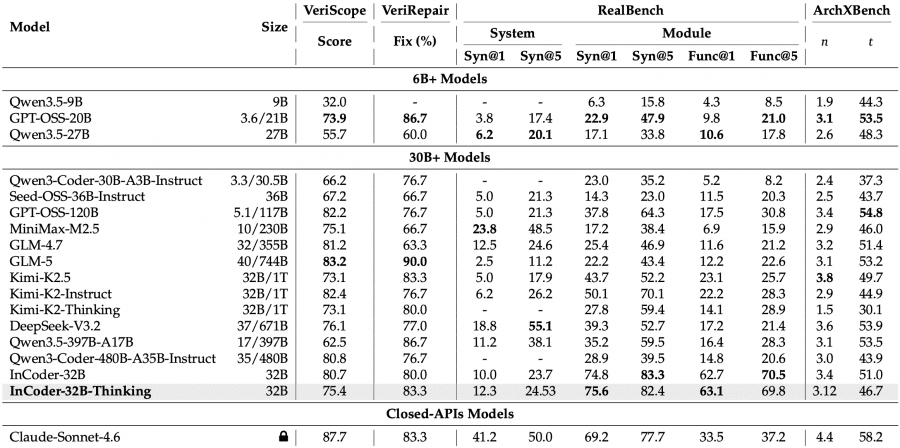
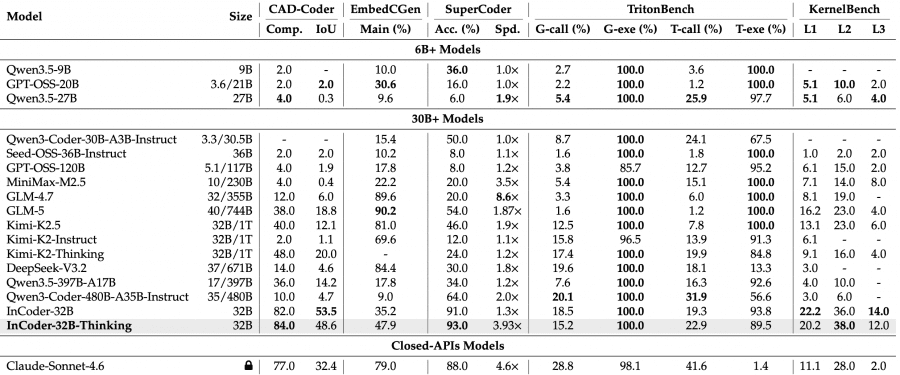
Есть и слабые места: на EmbedCGen (встраиваемые системы) модель набирает 47.9% против 79.0% у Claude Sonnet 4.6. Задачи на встраиваемый C требуют точного знания HAL-функций и поведения периферии — здесь проприетарные модели с большим объёмом обучающих данных пока впереди.
Как влияет объём обучающих данных
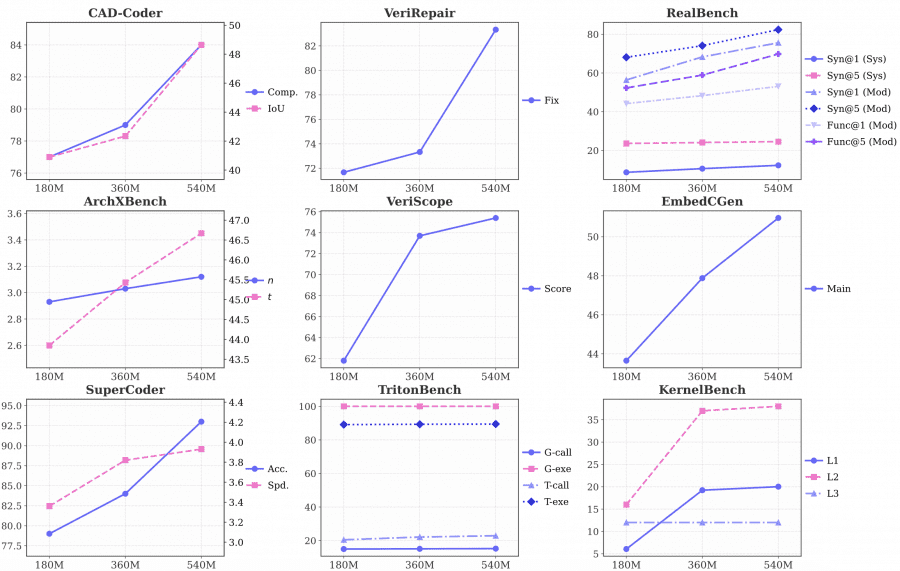
Исследователи обучили три контрольные точки на 180M, 360M и 540M токенах данных с пошаговыми рассуждениями. Большинство метрик монотонно растут: VeriScope Score поднимается с 61.8 до 75.4, KernelBench L2 — с 16.0 до 38.0. Некоторые метрики остаются стабильными — например, точность выполнения на TritonBench держится на 100% на всех трёх контрольных точках, что говорит о том, что базовые задачи модель осваивает быстро. KernelBench L3 при всех объёмах данных застревает на 12.0 — самые сложные задачи оптимизации требуют других подходов, не просто больше данных.
Как обучали базовую модель InCoder-32B
InCoder-32B-Thinking — это надстройка над базовой InCoder-32B, которая обучалась по трёхэтапному пайплайну Code-Flow. Понимать этот фундамент важно, потому что именно он объясняет, почему Thinking-вариант работает: нельзя научить модель рассуждать об аппаратных ограничениях, если она изначально не понимает специфику промышленного кода.
На первом этапе (pre-training + annealing) модель обучалась на промышленном коде из открытых репозиториев, технической документации и доменно-специфичных веб-данных. Исследователи провели многоуровневую дедупликацию: по точному хешу, по близости токенов, по принадлежности к форкам одного репозитория — чтобы модель не переобучалась на дублях одного проекта. Обучение шло на 4096 GPU с авторегрессионным языковым моделированием плюс fill-in-the-middle (FIM) — стандартная техника, позволяющая модели дописывать код в середину уже написанного.
На втором этапе (mid-training) контекстное окно последовательно расширялось: сначала с 8K до 32K токенов для задач уровня файла, например завершения RTL-модуля, потом до 128K для длинных отладочных сессий. Параллельно добавлялись синтетические QA-пары по промышленным сценариям: спецификация задачи → генерация кода → верификация → пара вопрос-ответ.
На третьем этапе (post-training) модель дообучалась на 2.5 миллионах примеров реальных промышленных задач, верифицированных через реальное выполнение. Ключевой элемент — траектории исправления по обратной связи: ошибки компилятора, логи времени выполнения, расхождения временных диаграмм, узкие места по профилировщику GPU. Именно эта база и стала исходным материалом для ECoT/ICWM, описанных выше.
Чем это отличается от обычного дообучения
Важно понять принципиальное отличие от стандартного supervised fine-tuning (SFT). При обычном дообучении модель учится на парах (задача, правильный ответ). Здесь же модель видит многоходовые траектории, где зафиксирован весь процесс: первая (неверная) попытка, конкретное сообщение об ошибке от компилятора, исправление, снова ошибка, снова исправление. Это напоминает то, как инженер на самом деле работает с кодом в реальной среде.
Второе отличие — роль ICWM как «быстрой» среды исполнения. Без неё синтез достаточного количества обучающих траекторий был бы слишком дорогим: каждый раз нужно запускать реальный компилятор Verilog или CUDA-симулятор. ICWM снижает этот барьер, заменяя большинство реальных запросов быстрым инференсом (inference) языковой модели, при этом сохраняя высокую точность (>93% согласованности траекторий по всем доменам).
Что пока не работает
Самое слабое место — 3D-моделирование. ICWM ошибается чаще всего именно там: когда скрипт CadQuery геометрически некорректен (например, цилиндр касается грани прямоугольного тела, создавая вырожденное ребро с нулевой длиной), ICWM может классифицировать такой ход как PASS, тогда как реальный CadQuery вернёт GEOMETRY_ERROR. Причина — геометрические проверки зависят от значений с плавающей точкой, которые сложно предсказать из текста кода. Исследователи решают эту проблему периодическими аудитами: часть траекторий всё равно прогоняется через реальные бэкенды, и исправленные метки используются для дообучения ICWM.
Ещё один паттерн из сравнения на бенчмарках: модели с цепочкой рассуждений в целом хуже справляются с задачами, которые требуют коротких и лаконичных ответов — например, Text2SQL и Mercury (эффективность кода). Это закономерно: длинные пошаговые рассуждения полезны там, где задача сложная и многошаговая, но лишние токены не помогают, когда нужен просто короткий SQL-запрос.
Главный вывод: цепочка рассуждений, опирающаяся на реальную обратную связь от среды исполнения, а не на абстрактные шаблоны промптов — рабочий рецепт для промышленного кода. Обучающие данные с пошаговыми рассуждениями масштабируются: больше токенов — лучше результат на сложных задачах. А ICWM делает этот синтез практически осуществимым без неограниченного доступа к реальным компиляторным бэкендам.








