
Распознавание диких животных в естественной среде обитания должно помощь экологам собирать наиболее точную и актуальную информация о поведении и количестве животных в дикой природе. Экологи, биологи и зоологи прилагают усилия, чтобы спасти дикую природу, пытаются повысить осведомленность о местоположении и поведении животных в естественных условиях.

Проекты камер-ловушек — один из методов, используемых экологами и биологами для получения информации о дикой природе. Размещение большого количества камер в равноудаленных местах в дикой природе позволило изучить размеры и распределение популяции животных. Тем не менее, из-за необходимых человеческих усилий для анализа изображений, полученных с помощью этих проектов, эксперты извлекают только небольшую часть ценной информации из огромного количества фотографий диких животных, которые сохранены на серверах. Совместные усилия исследователей из Университета Вайоминга, Обернского университета, Гарвардского университета, Оксфордского университета, университета Миннесоты и Uber AI привели к созданию точного метода распознавания диких животных по фотографиям с камер-ловушек.
Исследователи используют методы глубокого обучения и большие размеченные наборы данных для выявления, подсчета и описания поведения видов животных. Проблема может быть оформлена как многозадачная проблема обучения с использованием изображений из проектов камер-ловушек.
Датасет
Исследователи используют размеченный датасет, взятый из Snapshot Serengeti Project — крупнейшего в мире проекта камер-ловушек. В проекте задействовано 225 камер-ловушек, непрерывно работающих в национальном парке Серенгети, Танзания, датасет содержит 3,2 миллиона изображений, соответствующих 1,2 миллионам событий захвата (примечание: событие захвата представляет собой момент, когда камера идентифицировала движение и было сделано несколько снимков). В этом проекте исследователи фокусируются на событиях захвата, которые содержат только один вид, и удалили события, содержащие более одного вида.
После человеческой разметки оказалось, что 75% фотографий из датасета не содержат животных, так как камера-ловушка срабатывает на любое движение. Затем добровольцы разметили все события на каждой фотографии.
Однако применение такого подхода может быть потенциально опасным для процесса обучения, поскольку передаваемые метки от событий к отдельным изображениям часто могут не соответствовать друг другу. В статье утверждается, что добавление такого рода “шума” может быть преодолено нейронной сетью.
Тестовый набор
Для оценки моделей авторы создают два набора тестов: набор тестов с меткой эксперта, содержащий 3800 событий захвата, и набор тестов с меткой добровольца, состоящий из 17400 событий захвата.
Метод
Исследователи решают следующие задачи при использованием двухэтапного подхода:
- (I) обнаружение присутствия животного (решение задачи — пусто vs животное)
- (II) определение того, какие виды присутствуют,
- (III) подсчет количества животных
- (IV) описание действий на фотографии (поведение и наличие молодняка).
Ученые исследовали различные архитектуры глубоких нейронных сетей, чтобы найти наиболее подходящую для автоматизированной идентификации животных.
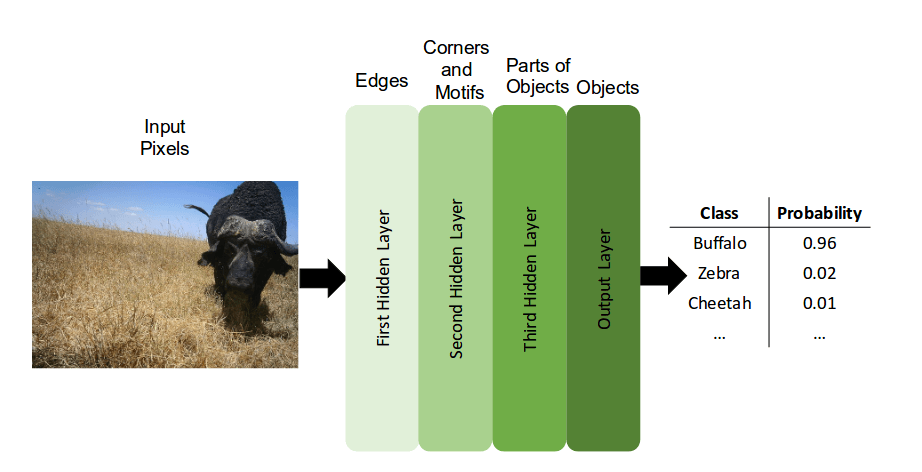
Постепенное преобразование необработанных данных в абстрактные понятия

Задача I: обнаружение изображений, содержащих животных
Первая задача самая простая из всех. Это двоичная классификация, и единственная проблема, возникающая в этом контексте — заметный дисбаланс классов. Чтобы решить эту проблему, исследователи взяли 25% непустых изображений и случайным образом выбрали тот же объем данных из остальных 75% пустых изображений. Таким образом, они получили 1,5 миллиона изображений, из которых 1,4 миллиона для обучения и 100 000 для тестирования. Как сообщают исследователи, все классификаторы достигают точности 95.8% в этой задаче, самая точная — VGG с точностью в 96.8%.
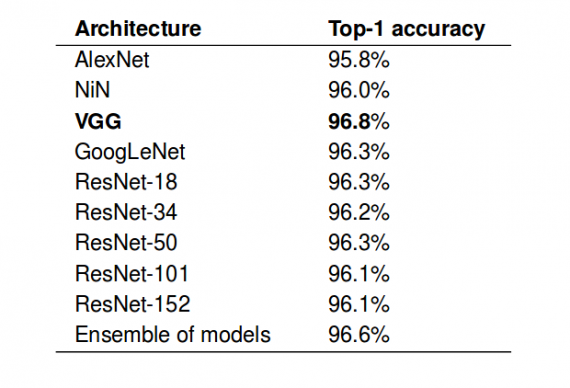
Задача II: определение видов (распознавание диких животных)
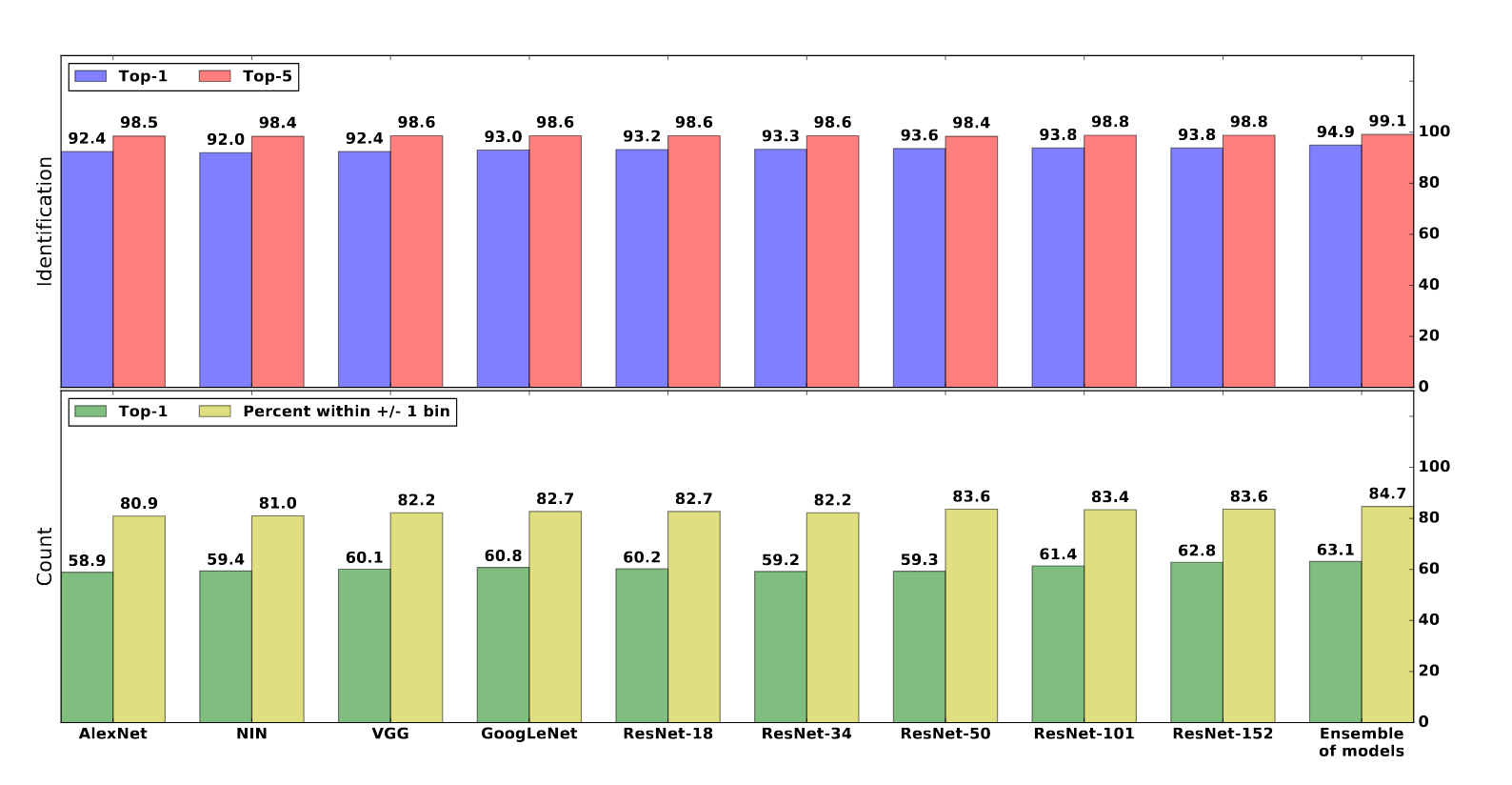
Для выполнения этой задачи авторы рассматривают методы “Top-1” и “Top-5” многокомпонентной классификации с 48 классами, соответствующих 48 видам, присутствующим в обучающем наборе данных. Окончательная модель достигает 99,1% с методом “Top-5”. Подход, который они используют для конкретной задачи идентификации видов — это совокупное обучение, где прогноз получается путем усреднения всех прогнозов из нескольких моделей. Оценки на размеченных экспертами данных: точность 94.9% с методом “Top-1” и 99,1% с методом “Top-5”(лучшая модель — ResNet-152 достигает 93.8% на “Top-1” и 98,8% на “Top-5”) .
Задача III: подсчет животных
Для решения этой задачи исследователи поделили пространство возможных ответов на 12 кластеров, соответствующих 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11–50 и 51+ животных на одном фото соответственно. В этой задачи они достигли (при использовании совокупности моделей на тестовом наборе, размеченном экспертами) точности 63,1% при “Top-1”, при этом 84,7% предсказаний находится в пределах +/-1 кластера.
Задача IV: поведение животных и дополнительные атрибуты
Набор данных Serengeti содержит 6 не взаимоисключающих меток, определяющих поведение животных на изображении: стоит, отдыхает, двигается, питается, взаимодействет, и наличие молодняка.
Двоичная классификация рассматривает возможность иметь несколько меток. Объединенная по всем атрибутам совокупность моделей достигает 76,2% точности (86,1% precision и 81,1% recall).
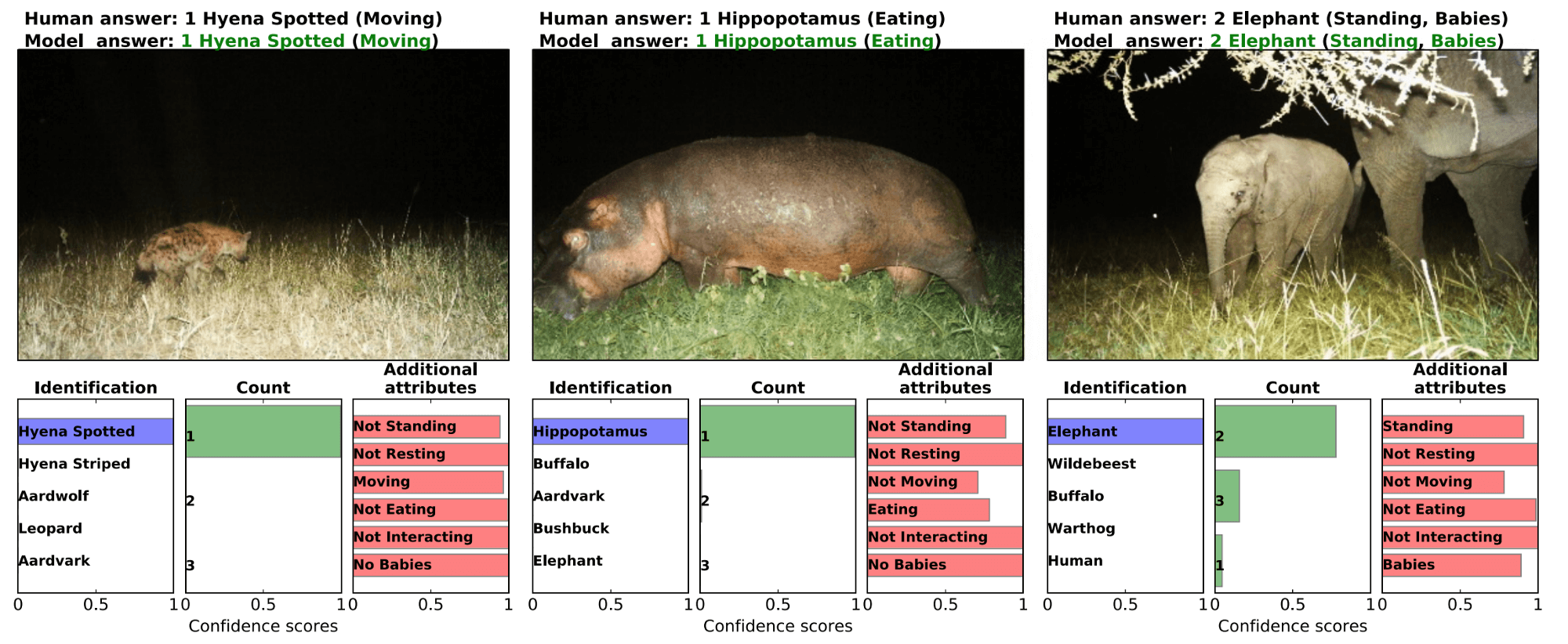
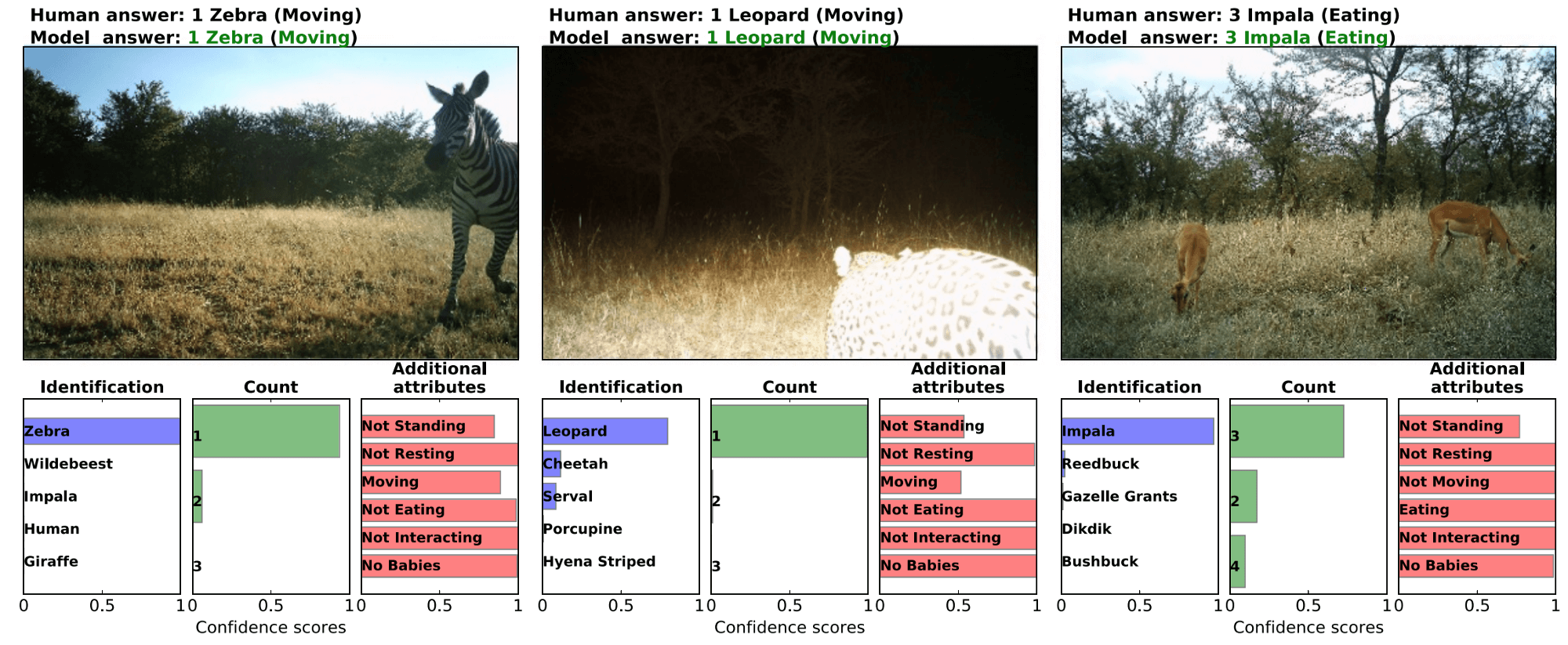
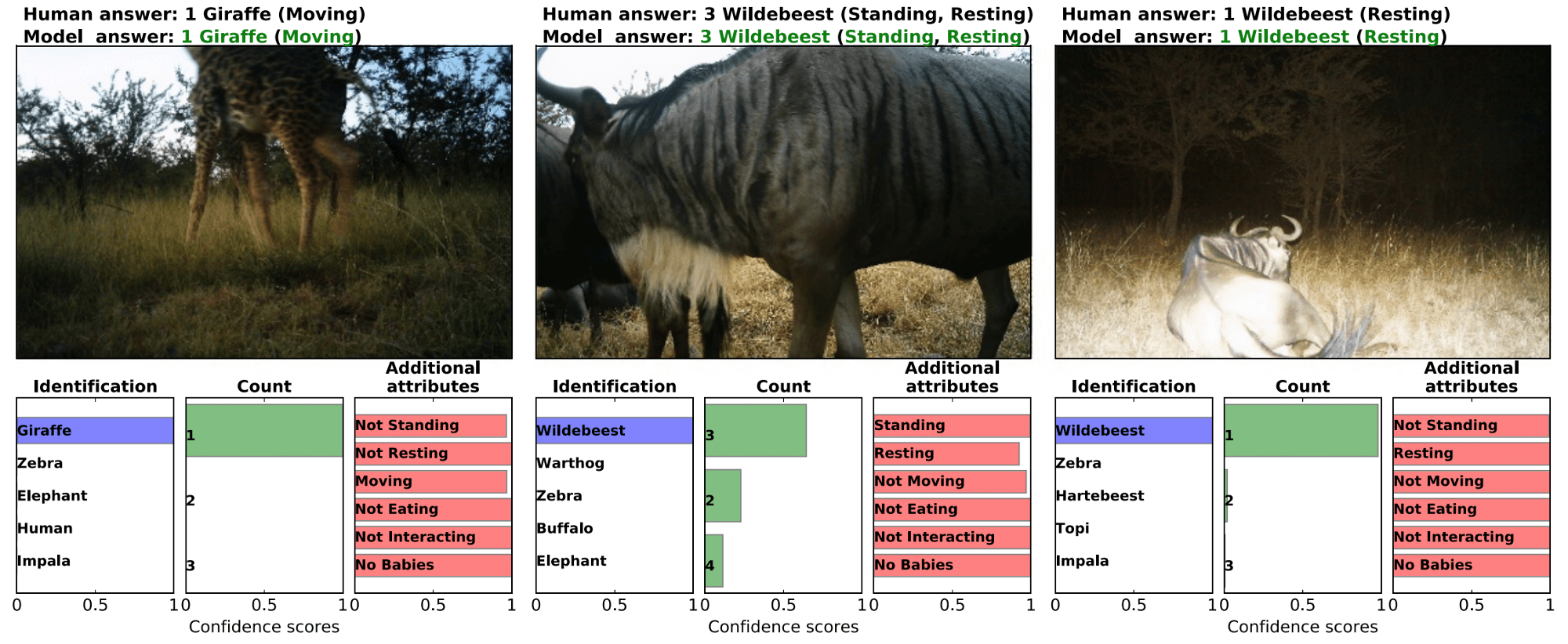
Работа показала, что глубокое обучение может быть полезно таким экспертам, как биологи и экологи, в их работе по изучению и сохранению дикой природы.



