Mini-Omni — первая open source языковая модель, позволяющая вести диалог голосом с минимальной задержкой ответа и без использования внешних text-to-speech моделей. Метод Any Model Can Talk позволяет интегрировать речевые возможности в любые языковые модели, улучшая их производительность в задачах, связанных с речью. Проект доступен на GitHub и Hugging Face.
Основные особенности
- Диалог в риал-тайм: Mini-Omni ведет диалог без задержки, обрабатывая как входные, так и выходные аудиоданные.
- Одновременная генерация текста и аудио: Модель может «говорить, думая», генерируя текст и аудио одновременно, обеспечивая плавный ход разговора.
- Потоковый вывод аудио: Mini-Omni поддерживает потоковый вывод аудио в реальном времени, что делает его идеальным для интерактивных приложений.
- Пакетный инференс: Модель включает методы пакетного (batch) инференса «аудио-текст» и «аудио-аудио» для дальнейшего повышения производительности.
Архитектура модели
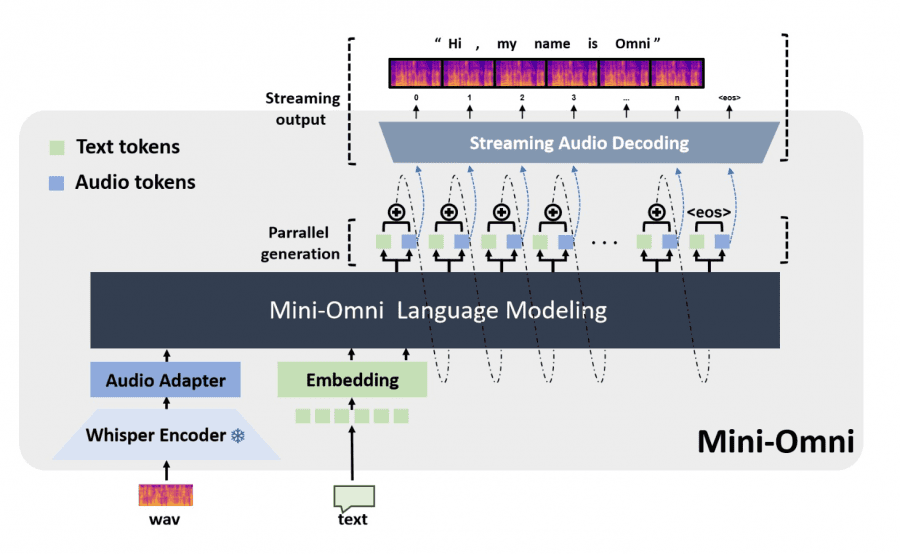
Модель Mini-Omni построена на основе Qwen2-0.5B, трансформерной архитектуры с 24 блоками и внутренней размерностью 896. Базовая модель была улучшена с помощью Whisper-small encoder для обработки речевых данных. Такое сочетание позволяет Mini-Omni интегрировать аудио-рассуждения в реальном времени в способности обработки языка.
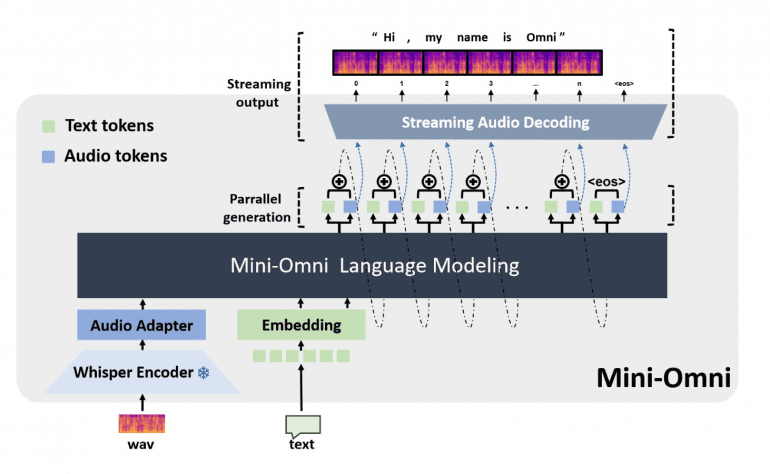
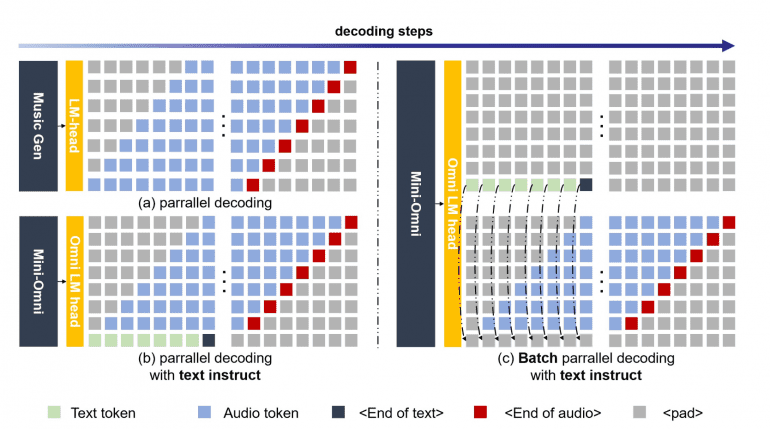
Параллельная генерация текста и аудио: Mini-Omni использует метод параллельной генерации текста и аудио, применяя пакетно-параллельное декодирование для одновременной генерации речи и текста. Это позволило сохраненить способностей модели к рассуждению в разных модальностях без снижения производительности.
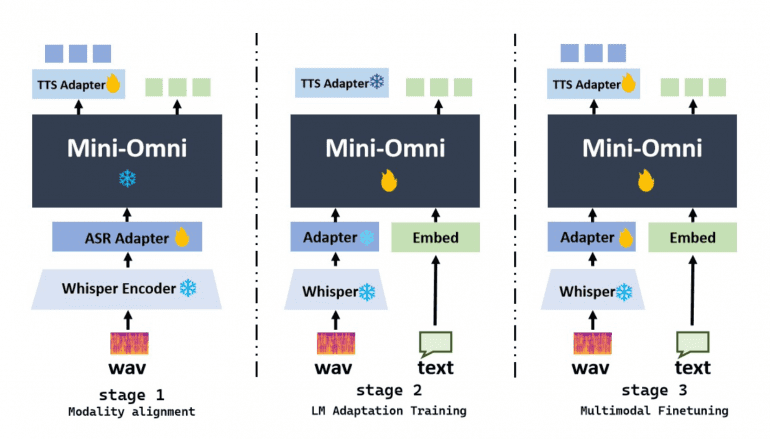
Фреймворк «Any Model Can Talk»
Этот фреймворк позволяет существующим языковым моделям, таким как LLaMA, Vicuna, и Baichuan, адаптировать речевые возможности с минимальной дополнительной тренировкой. Процесс включает три фазы: согласование модальностей, адаптацию и мультимодальный файнтюнинг, расширяя возможности этих моделей по взаимодействию с речью.
Датасеты и обучение
Mini-Omni был обучен на 8,000 часах речевых данных и 2 миллионах текстовых данных из датасета Open-Orca. Исследователи представили датасет VoiceAssistant-400K, специально разработанных для тонкой настройки речевых ассистентов.
Оценка производительности
Модель продемонстрировала высокую производительность как в задачах автоматического распознавания речи (ASR), так и в задачах преобразования текста в речь. Например, она достигла коэффициента ошибок по словам (WER) в 4.5% на датасете LibriSpeech test-clean, немного уступая моделям, таким как Whisper-small, с результатом 3.4%.