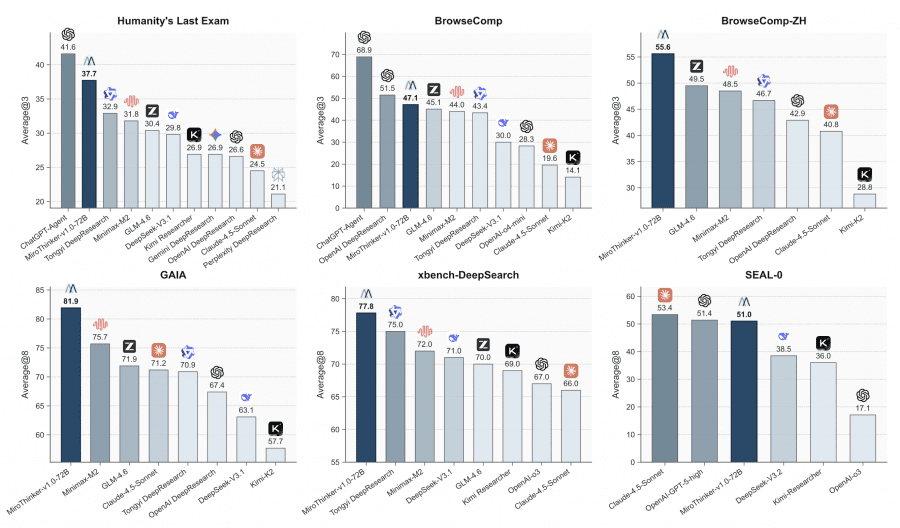
Команда MiroMind представила MiroThinker v1.0 — ИИ-агент для исследований, выполняющий до 600 вызовов инструментов на одну задачу при контекстном окне размером 256К токенов. На четырёх ключевых бенчмарках — GAIA, HLE, BrowseComp и BrowseComp-ZH — версия на 72B параметров достигает 81.9%, 37.7%, 47.1% и 55.6% точности соответственно, превосходя другие открытые агенты и приближаясь к коммерческим системам вроде GPT-5-high. Проект полностью открыт: код доступен на Github, веса моделей — на HuggingFace, а потестировать модель можно на онлайн-демо.
Что такое интерактивное масштабирование
Обычно производительность больших языковых моделей улучшают двумя способами: увеличивают размер модели или расширяют контекстное окно. MiroThinker добавляет третий способ — интерактивное масштабирование. Это означает, что модель учат делать больше и более глубоких взаимодействий с внешними инструментами в процессе решения задачи.
В отличие от обычного test-time scaling (когда модель просто дольше «думает» в изоляции), интерактивное масштабирование работает иначе: модель активно использует обратную связь от окружения и получает новую информацию извне. Это помогает исправлять ошибки и корректировать траекторию решения. Через обучение с подкреплением модель научилась эффективно масштабировать взаимодействия: с контекстным окном на 256К токенов она может выполнить до 600 вызовов инструментов на одну задачу, что позволяет поддерживать долгие цепочки рассуждений и справляться со сложными исследовательскими задачами из реального мира.
Как устроена архитектура агента
MiroThinker работает по парадигме ReAct — это циклический процесс «подумать–действовать–наблюдать». На каждом шаге модель анализирует текущую ситуацию и формулирует мысль, затем вызывает нужный инструмент, получает результат и обновляет своё понимание задачи. Этот цикл повторяется, пока задача не будет решена.
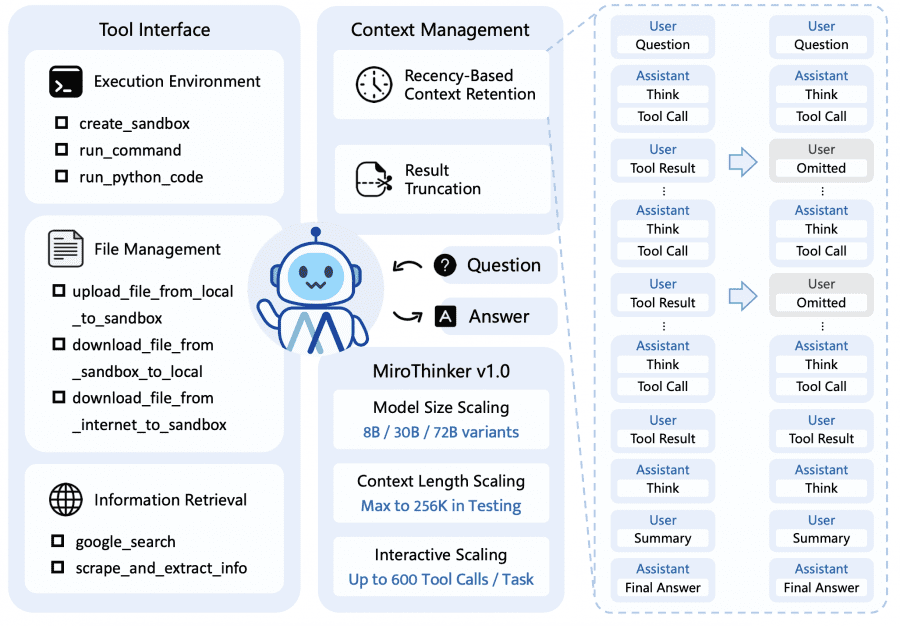
Агент имеет доступ к трём категориям инструментов.
- Среда выполнения: изолированная Linux-песочница для запуска команд и Python-кода.
- Управление файлами: загрузка и скачивание файлов между локальной системой, песочницей и интернетом.
- Поиск информации: веб-поиск через Google и умный парсинг веб-страниц. Особенность последнего в том, что инструмент использует лёгкую языковую модель (например, Qwen3-14B) для извлечения только релевантной информации из длинных веб-страниц по запросу агента — это эффективная форма управления контекстом.
Чтобы уместить до 600 взаимодействий в контекстное окно на 256К токенов, применяются две стратегии. Первая — удержание только недавних результатов: в контексте сохраняются все мысли и действия агента, но результаты работы инструментов оставляют только с последних K шагов (обычно K=5). Это работает, потому что следующие действия модели зависят в основном от недавних наблюдений, а не от далёких. Вторая стратегия — обрезка длинных выводов: если инструмент возвращает слишком много данных, ответ обрезается с пометкой «[Result truncated]».
Процесс обучения модели
Обучение MiroThinker проходит в три этапа, каждый из которых развивает разные навыки агента. Модели основаны на открытых весах Qwen2.5 и Qwen3, доступны в трёх размерах: 8B, 30B и 72B параметров.
На первом этапе — контролируемая тонкая настройка (SFT) — модель учится имитировать экспертные траектории решения задач. Для этого создали большой синтетический датасет с траекториями, где каждая содержит последовательность «мысль–действие–наблюдение». Исследователи обнаружили, что даже траектории, сгенерированные лучшими моделями, содержат много шума: повторы внутри ответов, дубликаты между ответами, неправильные вызовы инструментов. Поэтому применили строгую фильтрацию и восстановление данных перед обучением.
Второй этап — прямая оптимизация предпочтений (DPO). Модель учится выбирать лучшие траектории решения. Для этого собрали датасет с парами траекторий: предпочитаемая (которая привела к правильному ответу) и непредпочитаемая (которая привела к неправильному). Важно, что предпочтения определяются только по корректности финального ответа, без жёстких ограничений на структуру решения — не задают фиксированную длину планирования, количество шагов или формат рассуждения. Такой подход избегает систематических искажений и улучшает масштабируемость на разных типах задач.

Третий этап — обучение с подкреплением (RL) через алгоритм GRPO. Здесь модель учится находить творческие решения через прямое взаимодействие с окружением. Построили масштабируемую среду, способную поддерживать тысячи параллельных запусков агентов с реальным поиском, парсингом веб-страниц, выполнением Python-кода и работой с Linux VM. Функция награды учитывает корректность решения и штрафует за нарушение форматирования. Применили строгую фильтрацию траекторий: удаляют успешные траектории с патологическим поведением (серии ошибок API, избыточные повторы действий) и неуспешные траектории с тривиальными причинами провала (проблемы форматирования, зацикливание на одном действии).
Результаты на бенчмарках
MiroThinker-v1.0-72B установил новый стандарт среди открытых исследовательских агентов. На бенчмарке GAIA (проверяет способность к многошаговому рассуждению и использованию инструментов) модель достигла 81.9% точности, опередив предыдущего лидера MiniMax-M2 на 6.2 процентных пункта. На экстремально сложном Humanity’s Last Exam результат составил 37.7%, что на 2.5 пункта выше проприетарной GPT-5-high при использовании тех же инструментов.
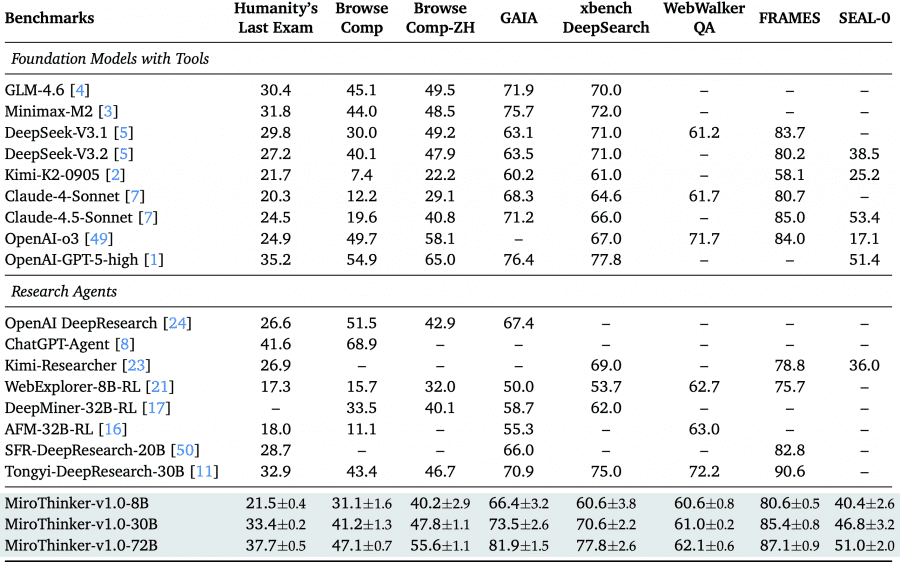
На бенчмарках для веб-навигации BrowseComp и BrowseComp-ZH (китайская версия) модель показала 47.1% и 55.6% соответственно. Это ставит её на один уровень с продвинутыми коммерческими системами вроде OpenAI DeepResearch, OpenAI o3 и Anthropic Claude 4.5. На китайском бенчмарке xBench-DeepSearch достигнут результат 77.8%, что подтверждает мультиязычные способности модели. Версии на 8B и 30B параметров также показывают лучшие результаты в своих размерных классах, давая сообществу доступ к мощным исследовательским агентам разного масштаба.
Анализ показал, что обучение с подкреплением существенно меняет паттерны взаимодействия агента с окружением. RL-версия MiroThinker-v1.0-30B демонстрирует значительно более длинные и глубокие траектории взаимодействий по сравнению с SFT-версией на всех бенчмарках. Под руководством проверяемых наград модель исследует более исчерпывающие пути решения, систематически проверяя несколько стратегий и валидируя промежуточные результаты. Это напрямую коррелирует с улучшением точности — прирост составляет 8-10 процентных пунктов в среднем. Эту устойчивую связь между глубиной взаимодействия и производительностью исследователи называют интерактивным масштабированием.
Известные ограничения
Команда выявила несколько ограничений текущей версии, которые планируют устранить в будущих обновлениях.
Качество использования инструментов при интерактивном масштабировании: хотя RL-версия вызывает инструменты чаще, часть этих вызовов даёт незначительный или избыточный вклад в решение. Это показывает, что масштабирование улучшает производительность, но нужна дополнительная оптимизация эффективности и качества действий.
Избыточно длинные цепочки рассуждений: обучение с подкреплением стимулирует модель генерировать более длинные ответы для повышения точности, что приводит к чрезмерно длинным, повторяющимся и менее читаемым цепочкам размышлений.
Смешение языков: ответы модели могут содержать многоязычные элементы — например, на запрос на китайском внутренние рассуждения могут включать английские и китайские фрагменты.
Ограниченные возможности песочницы: модель ещё не полностью освоила инструменты для выполнения кода и управления файлами. Иногда генерирует код, приводящий к таймаутам, или пытается использовать инструмент выполнения кода для чтения веб-страниц вместо специализированного парсера.





