Новое исследование EPFL проливает свет на внутренние механизмы обработки многоязычных данных в LLM, что критично для понимания принципов работы современных языковых моделей и их оптимизации. Исследователи применили метод Logit lens для анализа скрытых состояний в слоях моделей семейства Llama-2, чтобы понять, как происходит обработка инференса на разных языках.
Основные выводы:
- Процесс обработки языка в LLM проходит через три distinct states;
- На средних слоях наблюдается доминирование английского языка;
- Модель оперирует не прямым переводом, а абстрактными концептами.
Обучение и тестирование моделей
Модели Llama-2 7B, 13B и 70B обучались на датасете, где почти 90% данных составляли англоязычные тексты, при этом даже малая доля в 0.13% токенов на китайском включала 2.6 миллиарда образцов. На всех моделях наблюдался схожий паттерн обработки многоязычных данных.
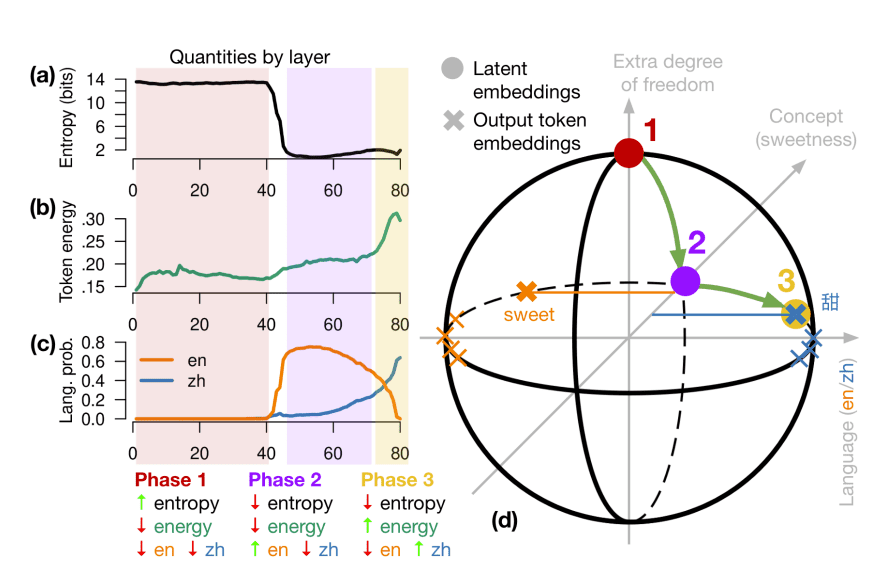
Используя метрики энергии и энтропии, исследователи EPFL детально проанализировали процесс обработки многоязычных данных в недрах трансформера. Выявлены три четких фазы обработки информации:
Фаза 1 — Начальное представление (Initial representation):
- Характеризуется высокой энтропией около 14 бит
- Низкая энергия токенов указывает на то, что модель еще не пытается предсказывать следующий токен
- Отсутствует доминирование какого-либо языка
- На этом этапе модель формирует базовые представления входных токенов, сохраняя максимальную гибкость для дальнейшей обработки
Фаза 2 — Концептуальная обработка (Conceptual processing):
- Энтропия резко падает до 1-2 бит
- Энергия остается низкой, что говорит о продолжающемся процессе обработки
- Начинает доминировать английский язык, но это связано с преобладанием английского в тренировочных данных
- В этой фазе формируются абстрактные концепции и смысловые связи
Фаза 3 — Генерация на целевом языке (Target language generation):
- Энергия токенов возрастает до 20-30%, что указывает на активную подготовку к генерации ответа
- Энтропия остается низкой, показывая высокую определенность в выборе следующего токена
- Доминирует целевой язык
- Происходит проецирование абстрактных концепций в конкретные языковые конструкции выходного языка
Эти наблюдения подтверждают, что процесс не является простым последовательным переводом, а представляет собой сложную трансформацию информации через промежуточное концептуальное представление.
Результаты исследования
Исследование EPFL опровергает распространенную гипотезу о последовательном переводе в LLM. Ранее считалось, что модели сначала преобразуют входные данные в английский язык, обрабатывают их, а затем переводят обратно. Однако анализ внутренних состояний Llama-2 с помощью метода Logit lens показал более сложный процесс.
Вместо прямого перевода модель формирует промежуточный уровень абстрактных концепций — своеобразный «язык мышления». В средних слоях трансформера действительно наблюдается преобладание английского языка, но это скорее следствие доминирования английского в обучающих данных, чем необходимый этап обработки информации. На этом уровне модель оперирует абстрактными смысловыми конструкциями, которые затем проецируются в целевой языковой домен.
Это открытие имеет важные практические следствия для развития мультиязычных моделей. Во-первых, оно объясняет удивительную эффективность LLM при работе с языками, слабо представленными в обучающих данных — модель может использовать универсальные концептуальные представления, сформированные на основе более богатых языковых данных. Во-вторых, понимание этого механизма может помочь в разработке более эффективных архитектур для zero-shot и few-shot learning, особенно для низкоресурсных языков. Наконец, это исследование открывает новые перспективы для изучения «мышления» языковых моделей и их способности к абстрактным рассуждениям.








