Wav2Lip — это нейросеть, которая адаптирует видео с говорящим лицо под аудиозапись речи. Предложенная нейросеть обходит state-of-the-art подходы на задаче синхронизации губ человека на видеозаписи с аудидорожкой.
Ограничения прошлых подходов
Текущие подходы способны генерировать точные движения губ для статичных изображений или видео отдельных людей, которых модель видела во время обучения. Однако такие модели не справляются с модификацией видеозаписей людей, которых не было в обучающей выборке. Это приводит к тому, что на части видеозаписи движения губ не синхронизированы с аудиодорожкой. Разработчики Wav2Lip обходят это ограничение. Модель способна адаптировать форму губ человека на любой входной видеозаписи в соответствии с входной аудиозаписью.
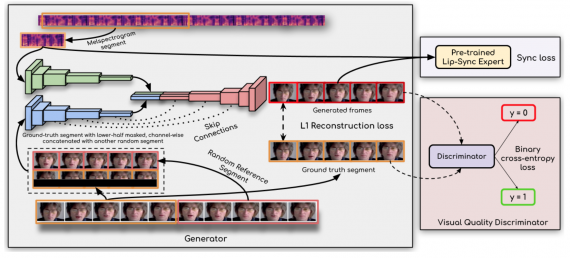
Архитектура модели
Предложенный подход синхронизирует входное видео и входную аудиозапись с помощью обучения совместно с предобученной lip-sync моделью. Прошлые подходы использовали для обучения только reconstruction loss или обучали дискриминатор в GAN. Wav2Lip использует предобученный дискриминатор, который уже точно распознает ошибки в видео с синхронизацией губ. Дискриминатор затем дообучается на шумных сгенерированных видео. Дообучение дискриминатора положительно влияет на его возможность измерять неточности в сгенерированных видео, что позволяет повысить общее качество сгенерированных форм губ на видео. Кроме того, в Wav2Lip используется дискриминатор качества картинки, чтобы повышать качество картинки на сгенерированных видео.