
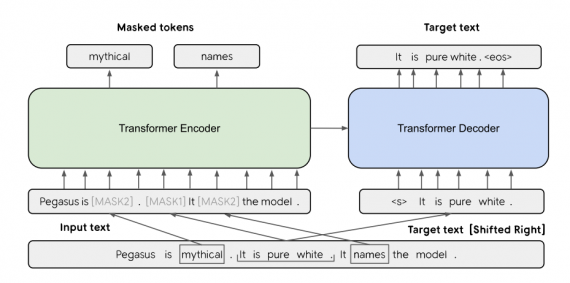
PEGASUS — это метод предобучения для задачи абстрактивной суммаризации. Базовая архитектура PEGASUS состоит из Transformer-модели с энкодером и декодером. Во время обучения модель оптимизирует два функционала ошибки: GSG и MLM. При GSG одно случайное предложение маскируется токеном [MASK1]. Цель — предсказать замаскированное предложение. Остальные предложения во входном тексте остаются, однако случайные токены маскируется токеном [MASK2] (MLM). В PEGASUS модель выучивается одновременно предсказывать замаскированные случайные токены и предложение. По результатам экспериментов, использование PEGASUS модели позволило обойти state-of-the-art подходы на 12 из 12 задач суммаризации. Домейны задач включали новости, науку, истории, инструкции, имейлы, патенты и законопроекты.
Описание проблемы
Предобучение Transformer-моделей на self-supervised целевых функциях с использованием больших текстовых корпусов позволяет получить хорошие результаты на целевых задачах, включая суммаризацию текста. Однако целевые функции предобучения, которые были бы специально адаптированы для задачи суммаризации, ранее не использовали. Исследователи предобучили Transformer с новой целевой функцией, чтобы протестировать, как это подействует на качество суммаризации. В PEGASUS важные предложения маскируются во входном документе и генерируются на выходе модели.
Оценка работы модели
Исследователи сравнили PEGASUS с state-of-the-art методами предобучения на 12 задачах суммаризации. В качестве метрики использовали ROUGE. Предложенный подход обошёл прошлые модели на всех задачах. Кроме того, модель хорошо работала на задачах малоресурсной суммаризации. PEGASUS обошёл state-of-the-art модели на 6 датасетах, используя при этом только 1000 примеров для обучения.
