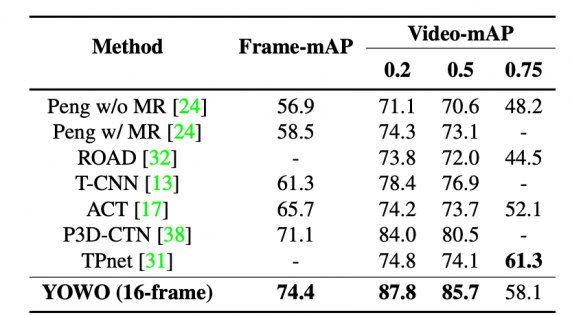
YOWO — это сверточная нейросетевая архитектура для распознавания действия на видео в реальном времени. Предыдущие походы использовали для решения этой задачи несколько моделей, предсказания с которых объединялись с помощью еще одной модели. YOWO является единой end-to-end нейросетью. Модель обрабатывает 34 кадра в секунду для видеозаписей с 16 кадрами и 62 кадра в секунду — для видеозаписей с 8 кадрами. YOWO обходит state-of-the-art на 3.3% и 12.2% по frame-mAP метрике.
Локализация действия в пространстве и времени требует внедрения двух источников информации в архитектуру модели:
- Временной контекст из предыдущих кадров;
- Пространственная информация с текущего кадра
Текущие state-of-the-art подходы обычно получают эту информацию с помощью отдельных нейросетей и затем отдельной моделью объединяют информацию и предсказывают действие на текущем кадре.
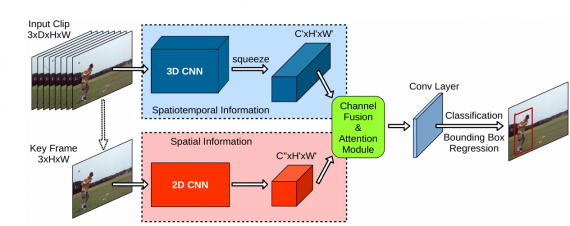
Архитектура нейросети
YOWO состоит из 4 основных компонентов:
- 3D-CNN распознает действия. В основе этой модели лежит 3D-ResNext-101 на основе множества предыдущих кадров;
- 2D-CNN извлекает из текущего кадра информацию о пространстве;
- CFAM (Channel Fusion and Attention Mechanism) объединяет предсказания с двух предыдущих шагов;
- Блок для предсказания границ объекта
3D-CNN была предварительно предобучена на Kinetics датасете. А 2D-CNN, в свою очередь, предобучили на PASCAL VOC.
Тестирование модели
Исследователи протестировали работу моделей на UCF101-24 и J-HMDB-21 датасетах. Ниже видно, что YOWO обходит state-of-the-art подходы по покадровому mean average precision (mAP).