
Предположим, вы посмотрели 10-минутное видео, но вас заинтересовала только маленькая часть. Если вы захотите сделать 5-секундную GIF из этого видео, то обработка окажется непростой задачей. Можно ли создать алгоритм для автоматического создания GIF из видео с учетом пользовательских предпочтений? Мы расскажем о новом подходе к этой проблеме.
 Модели обучаются находить “подсказки”, которые делают визуальный контент привлекательным или интересным для большинства людей. Однако интерес к сегменту видео субъективен. В результате такие модели выдают результат “для всех”, который не подходит конкретному пользователю. Другой подход предполагает обучать модель отдельно для каждого пользователя, но он неэффективен, так как требует большого объема личной информации, которая обычно недоступна.
Модели обучаются находить “подсказки”, которые делают визуальный контент привлекательным или интересным для большинства людей. Однако интерес к сегменту видео субъективен. В результате такие модели выдают результат “для всех”, который не подходит конкретному пользователю. Другой подход предполагает обучать модель отдельно для каждого пользователя, но он неэффективен, так как требует большого объема личной информации, которая обычно недоступна.
Что предлагается?
Анна Гарсия дел Молино и Михаел Гугли, работая на gifs.com, предложили новую глобальную модель ранжирования, которая учитывает интересы конкретного пользователя. Вместо того, чтобы обучать модель для каждого пользователя, их модель персонализируется согласно входным данным, адаптируя предсказания с учетом нескольких примеров конкретного пользователя. Она построена на успехе глубоких моделей ранжирования, но делает результат персонализированным.
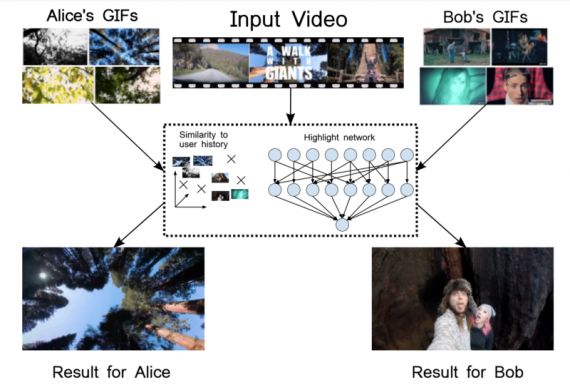
Другими словами, исследователи используют информации о GIFках, которые были созданы пользователем ранее. Они представляют его интересы и, следовательно, служат сильным индикатором для персонализации. Например, информации, что пользователь интересуется баскетболом, недостаточно. Один пользователь обрабатывает баскетбольные видео, чтобы выделить слэмы, а другого интересует только командные действия. А третий предпочитает моменты с поцелуями на камеру.



Для получения данных о GIFках, заранее созданных пользователем, исследователи направились на gifs.com и собрали широкомасштабную базу данных пользователей и GIFок, которые эти пользователи создали. Кроме того, они сделали эту базу доступной публично. Она состоит из 13,822 пользователей с 222,015 аннотациями к 119,938 видео.
Архитектура модели
Модель предсказывает оценку сегмента, основываясь и на самом сегменте и на выборке пользователя. При этом используется ранжирующий подход, в котором модель обучается оценивать позитивные сегменты видео выше, чем негативные. Предсказания строятся не столько на самом сегменте, сколько на истории раннее выбранных объектов.
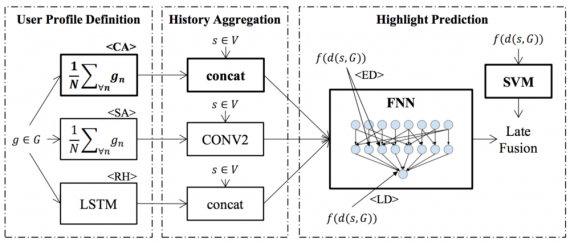
Исследователи предложили две модели, которые скомбинированы с последующим слиянием. Одна принимает на вход представление сегмента и суммарную историю (PHD-CA), а другая использует расстояния между сегментами и историей (SVM-D). Для модели с суммарной историей исследователи предложили использование нейронной сети прямого распространения (FNN). Это нейронная сеть с 2 скрытыми слоями с 512 и 64 нейронами. Что касается модели основанной на расстоянии, они создали вектор признаков, который содержит косинус расстояния до числа наиболее похожих элементов в истории. Далее эти две модели соединяются. Хотя модели различаются в диапазоне своих предсказаний и производительности, были использованы совместные веса для обеих моделей.
Прозводительность предложенных моделей сравнивалась с несколькими сильными базовыми подходами:
1) Video2GIF. Передовой подход в задачах автоматического выделений моментов для GIFок. Было проведено сравнение двух изначально натренированных моделей и модели с некоторыми изменениями, обученной на базе gifs.com, которая называется Video2GIF (авторская).
2) Highlight SVM. Модель ранжирующего метода опорных векторов (SVM), обученная на правильное ранжирование позитивных и негативных сегментов, с учетом только описания сегманта, игнорируя историю пользователя.
3) Video-MMR. В данной модели выше оцениваются схожие между собой сегменты. В частности, среднее значение косинусов сходства с элементами истории использовалось как оценка актуальности сегмента.
4) Residual Model. Исследователи переняли идею другой работы, где универсальная регрессионная модель использовалась вместе с моделью, которая настраивала прогнозы путем установки остаточной ошибки общей модели. Чтобы адаптировать эту идею к ранжированию, они обучали ранжирующий SVM, который получает предсказания от Video2GIF (авторского) в качестве входных данных, в совокупности с представлением сегмента.
5) Ranking SVM on the distances (SVM-D). Этот подход соответствует второй части предлагаемой модели (модели, основанной на расстоянии).
Показатели, использованные для количественного сравнения: mAP — усредненная средняя точность (mean average precision), nMSD — нормированный значимый результат продолжетельности (normalized Meaningful Summary Duration) и Recall@5 — отношение кадров от созданных пользователем GIFок(достоверных), которые включены в первые 5 наиболее оцененных GIFок.
Результаты
Таблица 1. Сравнение предложенного подхода (обозначается как Ours) с передовыми альтернативными методами сегментации видео на 5-секундные отрезки. Для mAP и R@5 чем выше результат, тем лучше метод. Для MSD чем меньше результат, тем лучше. Лучшие результаты в каждой категории выделены жирным шрифтом.
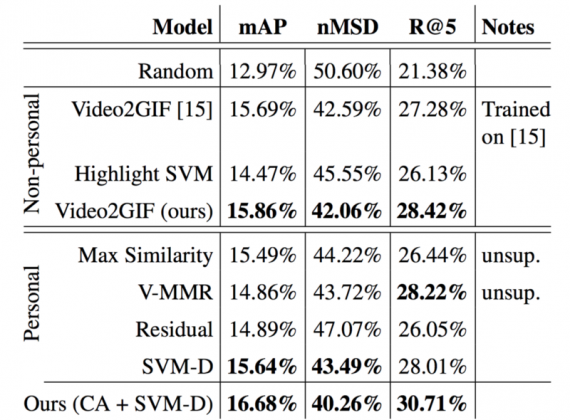
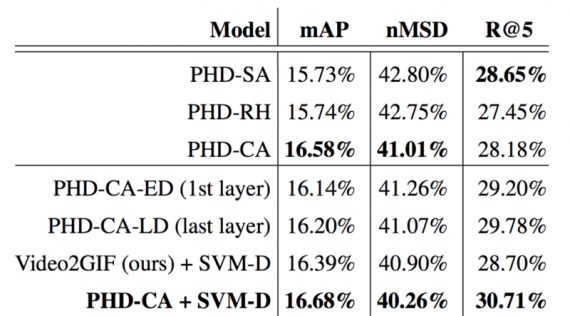
Как вы можете видеть, предложенный метод значительно превосходит все базовые. Добавление информации об истории пользователя в выделительные модели (Ours(CA + SVM-D)) приводит к 5.2%(+0.8%) mAP, 4.3%(-1.8%) mMSD и 8%(+2.3%) Recall@5 относительно универсальной выделительной модели (Video2GIF(авторской)).



Количественное сравнение с передовыми методами (Video2GIF). Правильные результаты в зеленых рамках. (c) представляет случай сбоя, когда история пользователя вводит в заблуждение модель.
Подведем итоги
Представлена новая модель для персонализированного выделения моментов из видео. Отличительная черта этой модели состоит в том, что предсказания основаны на предшествующем опыте пользователя. Эксперименты демонстрируют, что пользователи редко изменяют привычкам при выборе контента, что позволяет модели превосходить универсальные выделительные методы, например, на 8% в Recall@5. Это значительное улучшение для такой высокоуровневой задачи.
Кроме того, представлена новая широкомасштабная база данных с информацией о выборе пользователей в прошлом, что полезно для дальнейших исследований в этой области.
Виктор Новосад






