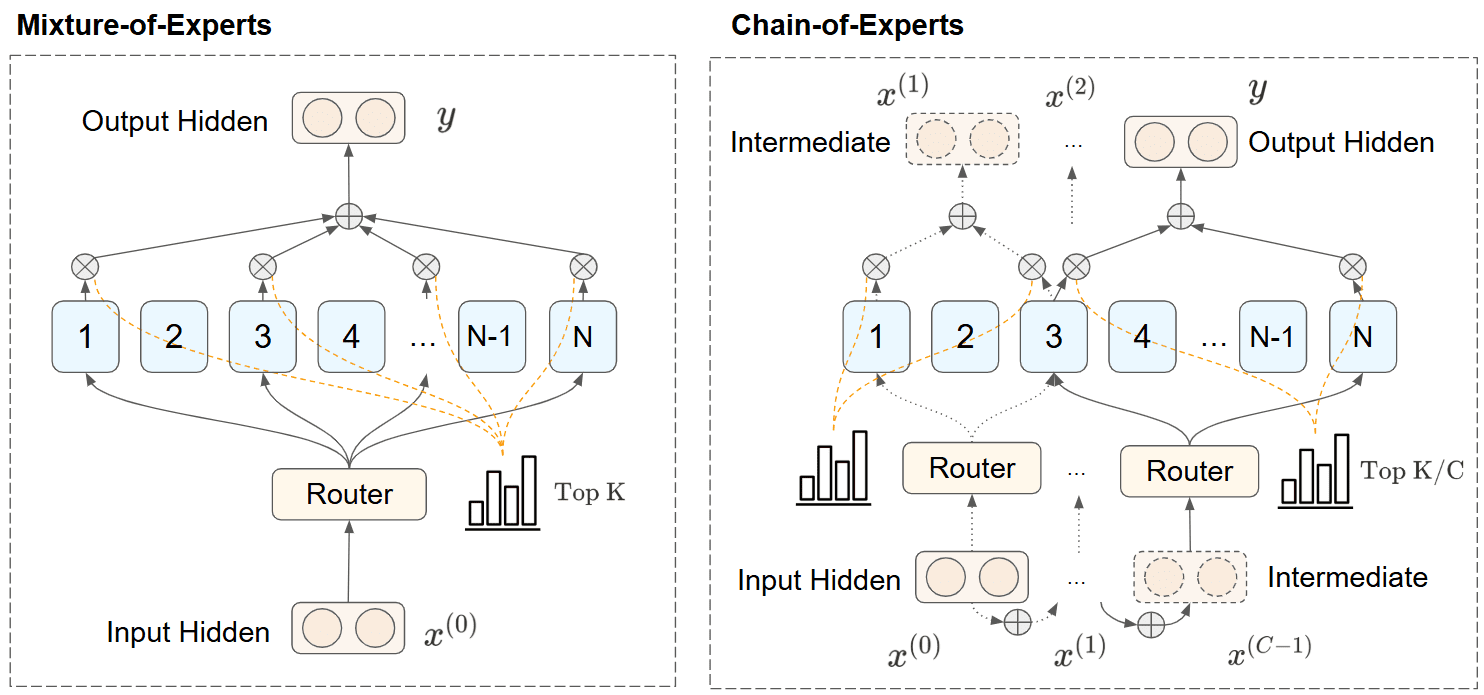
Chain-of-Experts (CoE) — новый подход, фундаментально изменяющий обработку информации в разреженных языковых моделях (sparse language models), увеличивающий производительность модели при значительно меньшем потреблении памяти. Метод решает ключевые ограничения Mixture-of-Experts моделей, раскрывая возможности для эффективного масштабирования. Применение метода CoE к архитектуре DeepSeekV2-Lite позволило снизить потребление памяти на 17-42%, а на других текстах улучшить производительность модели при том же объеме параметров. Метод был опубликован бывшим разработчиком DeepSeek Zihan Wang, код доступен в открытом доступе на Github.
Традиционные модели MoE сталкиваются с двумя важными ограничениями — эксперты обрабатывают информацию независимо с минимальной коммуникацией, а разреженные схемы активации требуют существенных GPU-ресурсов. CoE представляет решение, которое устраняет обе проблемы путем последовательной обработки информации экспертами.
Как работает цепочка экспертов
В CoE реализован итеративный механизм, когда эксперты обрабатывают токены на основе данных, полученных от других экспертов:
- Вместо параллельной обработки эксперты работают последовательно, формируя зависимости между экспертами;
- Выбор экспертов на каждой итерации определяется выходными данными предыдущей итерации;
- Информация накапливается в процессе итераций, обеспечивая явную коммуникацию между экспертами.
Формальное представление можно описать как:
x(0)=xx^{(0)} = x x(t)=∑i=1Ngt,i⋅Ei(x(t−1))+Ir⋅x(t−1),t=1,2,...,Cx^{(t)} = sum_{i=1}^{N} g_{t,i} cdot text{E}_i(x^{(t-1)}) + mathbb{I}_r cdot x^{(t-1)}, quad t = 1, 2, ..., C y=x(C)y = x^{(C)}
Эксперименты показали, что независимые гейты (independent gating mechanisms) и внутренние остаточные соединения (inner residual connections) имеют критическое значение для успеха CoE. Независимый гейтинг позволяет экспертам обрабатывать различные типы информации на разных этапах, в то время как внутренние остаточные соединения эффективно увеличивают глубину модели.
Тестирование метода
Метод Chain-of-Experts был протестирован на архитектуре DeepSeekV2-Lite с общим количеством параметров 544MB (исключая эмбеддинги), сконфигурированной с 4 скрытыми слоями, размерностью скрытого состояния 1024 и 8 головами внимания.
Эксперименты использовали датасет MetaMathQA, который является расширенной версией датасетов GSM8K и MATH.
Результаты Chain-of-Experts
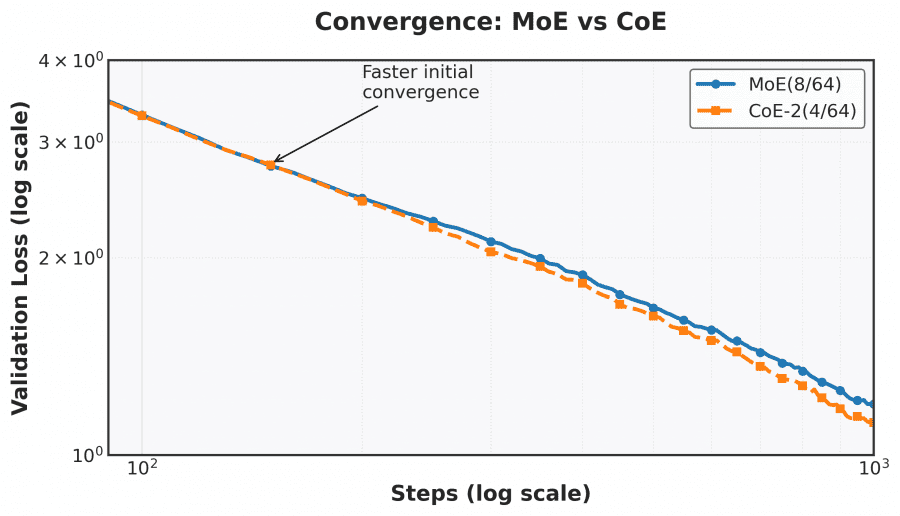
Эксперименты проводились на серверах с одиночными GPU H100 (приблизительно 30 минут на запуск) или GPU 4090 (приблизительно 2 часа на запуск).
- CoE с 2 итерационными циклами снизил потерю на математических задачах с 1.20 до 1.12 по сравнению с традиционными моделями MoE;
- Требования к памяти уменьшились на 17.6-42% при сохранении эквивалентной производительности;
- CoE с 4 слоями показывает одинаковую производительность с традиционной MoE с 8 слоями;
- Тесты подтвердили, что механизм независимых гейтов и внутренние остаточные соединения были необходимым ингридиентом эффективности CoE.
Исследователи описывают эффект «бесплатного завтрака» (free lunch), когда реструктуризация информационного потока дает лучшие результаты без дополнительных вычислительных затрат. Этот эффект проистекает из:
- Резко увеличенной свободы в выборе экспертов;
- Унификации последовательной обработки и коммуникации экспертов;
- Улучшенной специализации экспертов.
CoE представляет собой значительный прогресс в масштабировании моделей искусственного интеллекта, потенциально делая продвинутые языковые модели более эффективными.







