
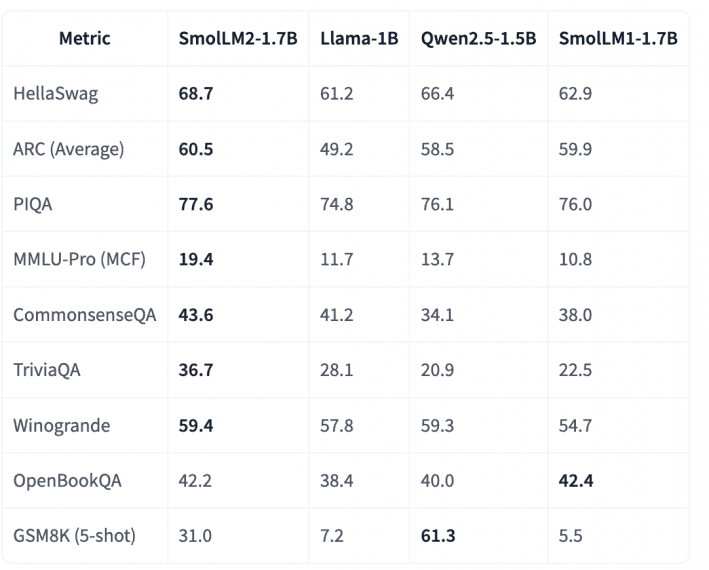
Компания Hugging Face представила SmolLM2 — новое семейство компактных языковых моделей, которое преводсходит существующие state-of-the-art модели. Так версия с 1.7B параметров опережает Llama-1B и Qwen2.5-1.5B на нескольких ключевых бенчмарках: 68.7% в тесте HellaSwag (против 61.2% у Llama-1B), 60.5% в ARC Average (против 49.2% у Llama-1B) и 77.6% в PIQA (против 74.8% у Llama-1B).
Ключевые характеристики
- 3 размера модели: 135M, 360M и 1.7B параметров
- Стабильно превосходит модели аналогичного размера по ключевым метрикам
- Архитектура: декодер Transformer
Детали обучения
- 11 триллионов токенов для обучения
- Точность bfloat16
- 256 GPU H100
- Фреймворк обучения: nanotron
Результаты и сравнения
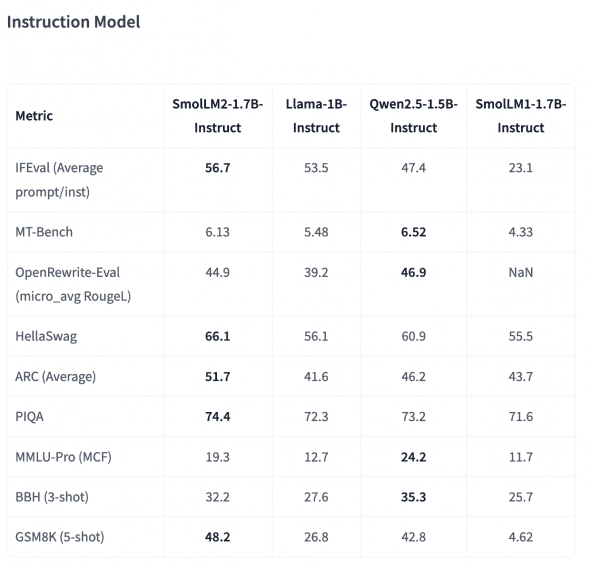
Результаты бенчмарков наглядно демонстрируют возможности SmolLM2-1.7B в сравнении с конкурентами:
- HellaSwag: 68.7% (против 61.2% у Llama-1B и 66.4% у Qwen2.5-1.5B)
- ARC Average: 60.5% (против 49.2% у Llama-1B и 58.5% у Qwen2.5-1.5B)
- PIQA: 77.6% (против 74.8% у Llama-1B и 76.1% у Qwen2.5-1.5B)
Особенности реализации
Модель обладает способностью следовать инструкциям благодаря supervised fine-tuning (SFT) на основе как публичных, так и специально подготовленных датасетов. Затем производительность была дополнительно улучшена с помощью Direct Preference Optimization (DPO) с использованием UltraFeedback. Более того, модель поддерживает такие задачи, как переписывание текста, суммаризация и вызов функций, благодаря датасету Argilla’s Synth-APIGen-v0.1.
Следует отметить, что SmolLM2 работает преимущественно с английским языком, поэтому результаты её работы требуют проверки на фактическую точность и согласованность.
В итоге, SmolLM2 представляет собой перспективное решение для разработчиков, которые стремятся внедрить возможности искусственного интеллекта на конечных устройствах, обеспечивая баланс между производительностью и вычислительной эффективностью под лицензией Apache 2.0.








