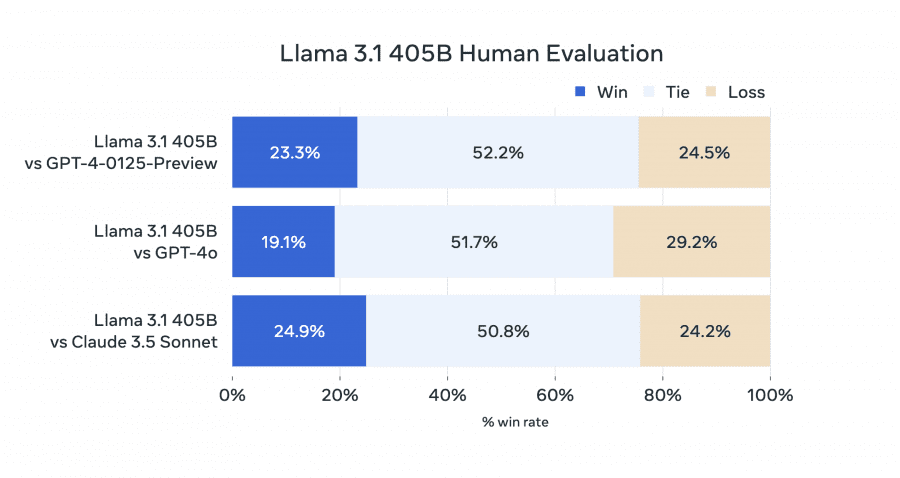
Модели LLaMA 3.1 официально выпущены, включая самую большую открытую модель с 405 миллиардами параметрами, модели 70B и 8B и мультимодальную модель. Контекст расширен до 128K токенов, поддерживается восемь языков, а результаты тестов сопоставимы оценками проприетарных state-of-the-art моделей.
LLaMA 3.1 включает несколько важных обновлений:
- Расширенная длина контекста: Длина контекста увеличена до 128 000 токенов, что позволяет обрабатывать более объемные и сложные входные данные, сохраняя связность на протяжении длинных диалогов.
- Поддержка языков: Модель теперь поддерживает восемь языков, что расширяет ее возможности для многоязычных приложений.
- Модель уровня фронтира: Флагманская модель, LLaMA 3.1 405B, имеет 405 миллиардов параметров, что делает ее самой крупной и наиболее мощной открытой моделью.
Модели LLaMA 3.1 и их возможности
- LLaMA 3.1 Base: Предназначена для общих задач на понимание и генерации текста.
- LLaMA 3.1 Fine-Tuned: Адаптирована для специализированных задач в таких областях, как юридическая, медицинская или техническая сферы, значительно улучшая производительность базовой модели в этих областях.
- LLaMA 3.1 Zero-Shot: Оптимизирована для обучения без примеров, чтобы справляться с задачами, на которых не была явно обучена.
- LLaMA 3.1 Multi-Modal: Интегрирует возможности обработки текста и изображений, расширяя функциональность до анализа мультимодальных данных.
Сравнение с LLaMA 3
LLaMA 3.1 представляет собой значительное обновление по сравнению с LLaMA 3. Длина контекста увеличена до 128 000 токенов по сравнению с 12 000 токенами в LLaMA 3, что улучшает способность модели обрабатывать более длинные и сложные входные данные. Исследования показывают, что увеличение длины контекста может улучшить производительность в задачах, требующих управления долгосрочными зависимостями (source).
Оценка моделей
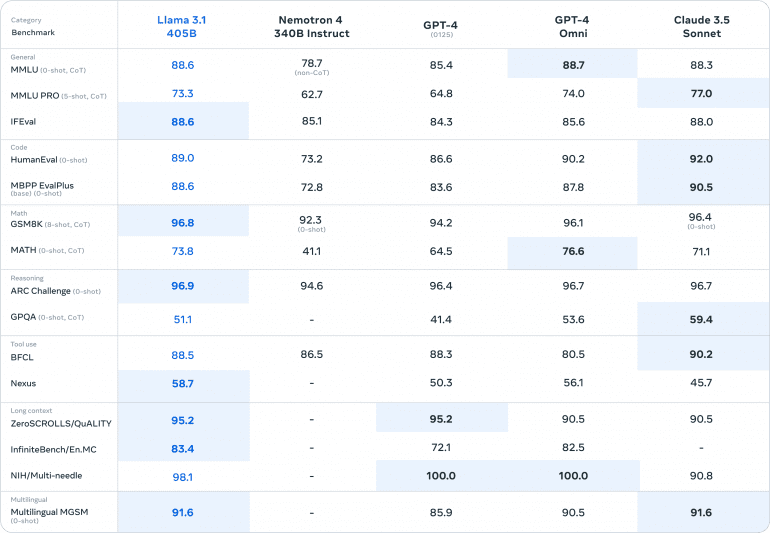
LLaMA 3.1 405B демонстрирует выдающуюся производительность, превосходя другие современные модели на тестах.
Общие метрики
- MMLU (0-shot, CoT): LLaMA 3.1 набирает 88.6, опережая Nemotron 4 (78.7), GPT-4 (85.4), GPT-4 Omni (88.7) и Claude 3.5 Sonnet (88.3).
- MMLU PRO (5-shot, CoT): LLaMA 3.1 набирает 73.3, значительно выше, чем Nemotron 4 (62.7), GPT-4 (64.8) и GPT-4 Omni (74.0), но немного ниже, чем Claude 3.5 Sonnet (77.0).
- IFEval: LLaMA 3.1 достигает 88.6, превосходя Nemotron 4 (85.1), GPT-4 (84.3) и GPT-4 Omni (85.6), и близка к Claude 3.5 Sonnet (88.0).
Код
- HumanEval (0-shot): LLaMA 3.1 набирает 89.0, превосходя Nemotron 4 (73.2), GPT-4 (86.6), GPT-4 Omni (90.2) и Claude 3.5 Sonnet (92.0).
- MBPP EvalPlus (base) (0-shot): LLaMA 3.1 достигает 88.6, опережая Nemotron 4 (72.8), GPT-4 (83.6), GPT-4 Omni (87.8) и немного отставая от Claude 3.5 Sonnet (90.5).
Обучение модели
Обучение LLaMA 3.1 405B на более чем 15 триллионах токенов включало:
- Оптимизированный тренировочный стек: Использовано более 16 000 GPU H100 для эффективного обучения.
- Квантование: Модели были квантированы с 16-битных до 8-битных чисел, что снизило требования к вычислениям и обеспечило работу на одном узле.
- Итеративное дообучение: Сочетание supervision дообучения и оптимизации для повышения производительности.
Цены
Цены LLAMA 3.1 лучше, чем у конкурентов (пока). Сравнение цен на запросы к API:
- LLaMA 3.1: Цена около 0,01 $ за 1 000 токенов для стандартного использования.
- Gemini (Google DeepMind): Примерно 0,015 $ за 1 000 токенов.
- Sonnet (Claude): Стоимость около 0,012 $ за 1 000 токенов.
- GPT-4 (OpenAI): Около 0,03 $ за 1 000 токенов для стандартного доступа.
Разработка с использованием LLaMA 3.1 405B
Для обычного разработчика использование модели масштаба 405B представляет собой непростую задачу из-за значительных требований к вычислениям. Экосистема LLaMA поддерживает различные продвинутые пайплайны, включая генерацию синтетических данных, дистилляцию модели и генерацию с поддержкой поиска, с решениями от партнеров AWS, NVIDIA и Databricks.





