
Исследователи из Stepfun AI представили Step-Video-T2V, text-to-video модель с 30 миллиардами параметров, способную генерировать видео длиной до 204 кадров, с разрешением 544×992. Модель принимает промпты на китайском и английском языках. Модель выложена в открытый доступ на Hugging Face и ModelScope. Open-source релиз включает основную модель и Turbo версию, оптимизированную для более быстрого инференса, и полный код для тренироваки и инференса модели.
Step-Video-T2V включает продвинутое сжатие видео, архитектуру трансформера и Direct Preference Optimization (DPO) для улучшения качества и эффективности генерации видео. Исследователи представили новый метод сжатия VideoVAE, превосходящий стандартные видеокодеки в 4 раза:
- 16×16 пространственное сжатие (по сравнению с 2x-4x в индустриальном стандарте H.264)
- 8x временное сжатие (по сравнению с типичным 2x-4x)
- 860 секунд для обработки видео высокого разрешения

Архитектура модели
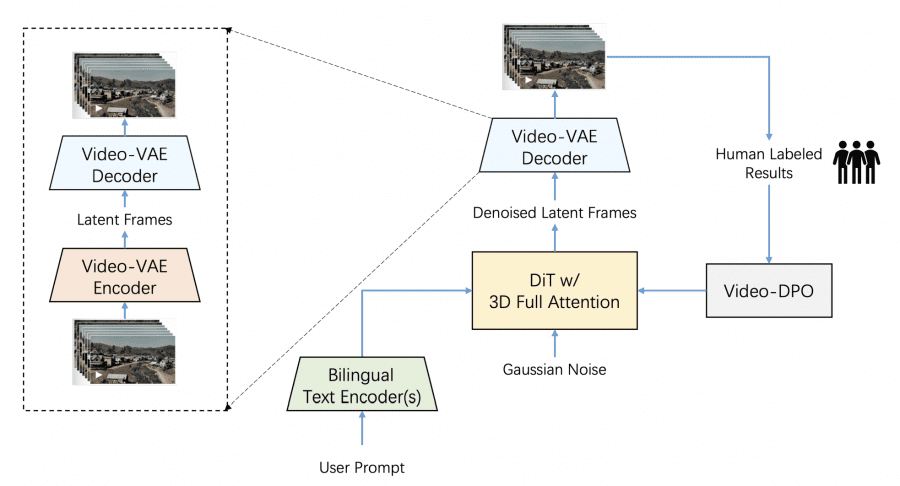
Система интегрирует три компонента:
- VideoVAE для глубокого сжатия с сохранением качества видео;
- DiT (Diffusion Transformer) с 48 слоями для обработки сжатых данных;
- Двойные text encoders для обработки английского и китайского языков.
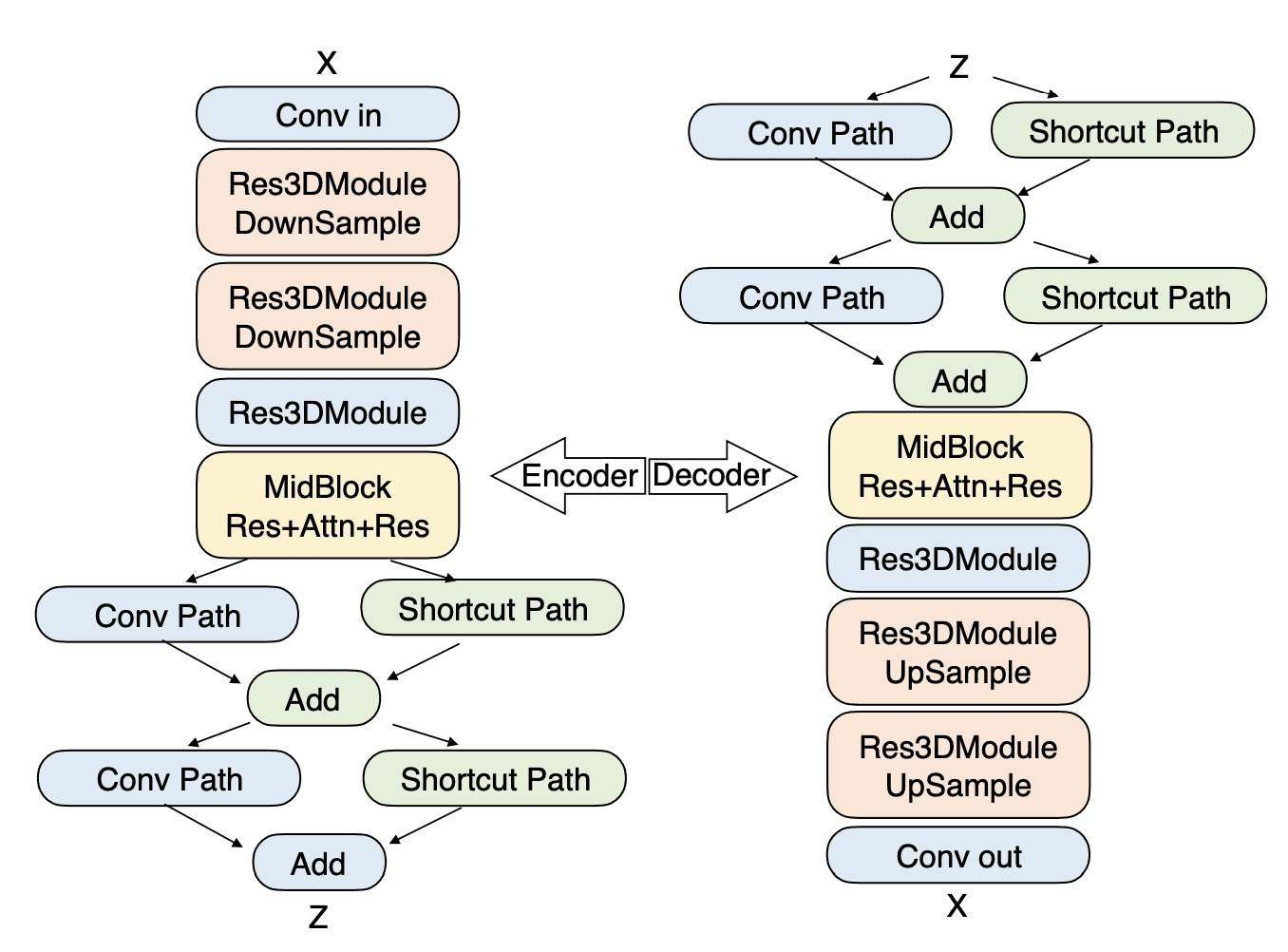
Архитектура транфсормера состоит из 48 слоев с 48 attention heads на слой, работающих в 128-мерном пространстве.
Системные требования Step-Video-T2V
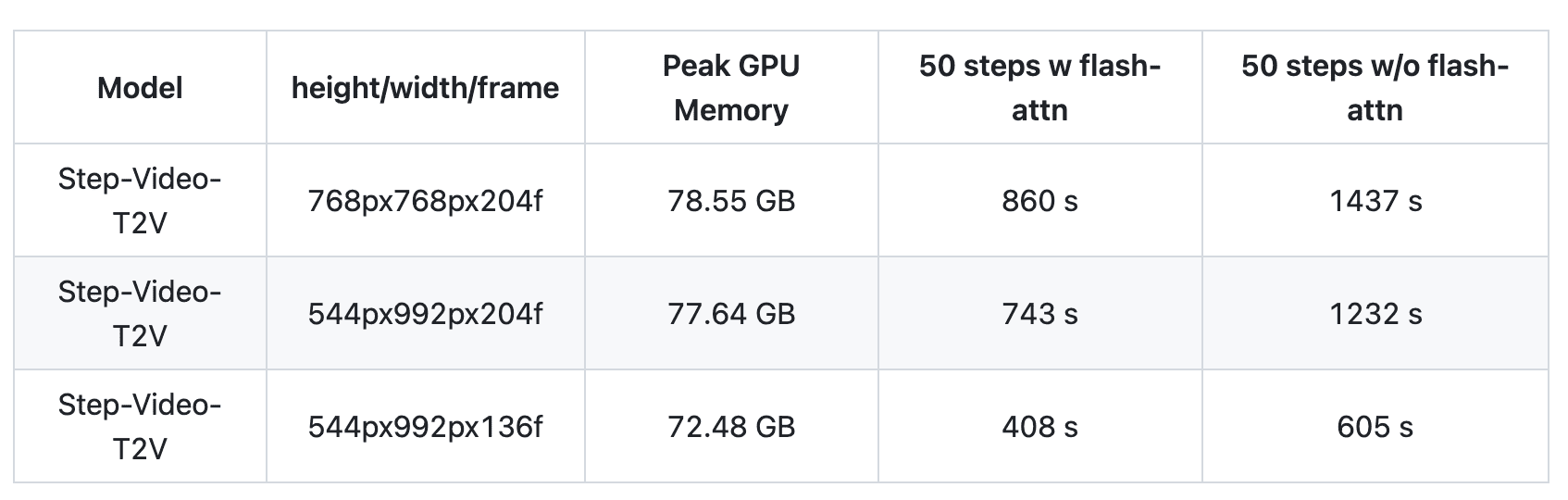
Step-Video-T2V требует 80GB GPU памяти, с пиковым использованием 78.55 GB для видео 768×768 пикселей. Время на одну генерацию варьируется от 860 до 1437 секунд в зависимости от оптимизации. Программные требования: Python 3.10.0+, PyTorch 2.3-cu121, CUDA Toolkit, FFmpeg и операционная система Linux.
Бенчмарк Step-Video-T2V-Eval
Бенчмарк Step-Video-T2V-Eval тестирует систему, используя 128 реальных китайских промптов в 11 различных категориях. Эти категории охватывают визуальное искусство (3D анимация, кинематография, художественные стили), реальные объекты (спорт, еда, пейзажи, животные, праздники) и концептуальный контент (сюрреалистические темы, комбинированные концепции, люди).
Результаты модели:
Варианты развертывания
Система поддерживает как multi-GPU (параллельная обработка на 4 или 8 GPU), так и single-GPU конфигурации с опциями квантизации. Требуются выделенные ресурсы для text encoding и VAE decoding.
Рекомендуется иметь 4 GPU с 80GB памяти для запуска. Квантизированная турбо модель работает на GPU 24GB памяти.
Открытый код позволяет исследователям и разработчикам адаптировать систему для специализированных случаев использования. Модульная архитектура проекта позволяет независимую оптимизацию компонентов, таких как VAE, DiT или text encoders. Хотя текущие приложения ограничены требованиями к ресурсам, будущие оптимизации могут расширить доступность. Сообщество уже работает над снижением требований к памяти и улучшением скорости inference.
Step-Video-T2V представляет собой измеримый прогресс в AI-генерации видео, с конкретными улучшениями в сжатии, эффективности обработки и качестве выходных данных. Требования к ресурсам в настоящее время ограничивают его применение корпоративными и исследовательскими приложениями. Усилия по разработке сосредоточены на снижении вычислительных требований и расширении доступности в различных вычислительных средах.






