Компания Arcee AI выложила в открытый доступ Trinity-Large-Thinking — модель с рассуждениями для сложных многоходовых агентных задач. На PinchBench — главном бенчмарке для агентных задач — она занимает второе место среди всех существующих моделей, уступая только Claude Opus-4.6, при этом стоит в 28 раз дешевле. Проект полностью открытый: модель и веса доступны на Hugging Face под лицензией Apache 2.0. Это означает, что любой разработчик или компания может скачать, дообучить, квантизировать и развернуть модель на своей инфраструктуре без каких-либо ограничений. Попробовать модель можно прямо сейчас через OpenRouter или в режиме чат-бота.
Откуда взялась модель
Arcee AI — небольшая американская лаборатория из Сан-Франциско, которая девять месяцев назад приняла нетривиальное решение: самостоятельно обучать базовые (foundation) модели с нуля, вместо того чтобы дообучать чужие. Компания привлекла $24 млн Series A в 2024 году, а суммарное финансирование составило около $50 млн. На этом фоне решение потратить $20 млн — почти половину всего привлечённого капитала — на один 33-дневный тренировочный прогон выглядит как очень рискованная ставка.
Прогон прошёл на кластере из 2048 видеокарт NVIDIA B300 Blackwell, которые примерно вдвое быстрее предыдущего поколения Hopper. Партнёром по вычислительной инфраструктуре выступила компания Prime Intellect, а данными для обучения занималась DatologyAI.
Результат этой ставки — семейство Trinity: сначала вышли компактные варианты Nano (6B параметров) и Mini (26B), затем в конце января 2026 года — Trinity-Large-Preview с лёгким post-training. Теперь выходит финальная reasoning-версия — Trinity-Large-Thinking.
Архитектура: разреженная MoE с 400 млрд параметров
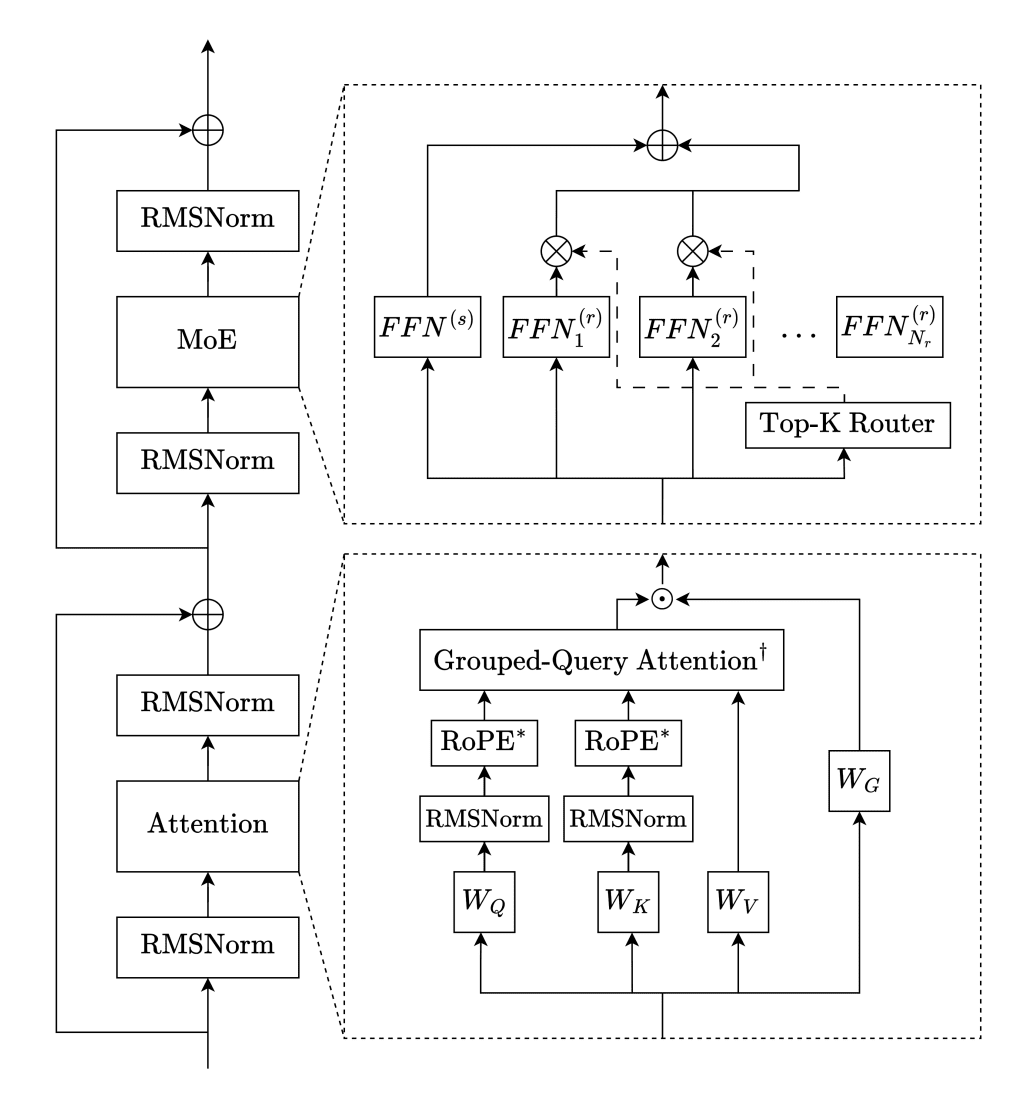
Trinity-Large-Thinking построена на архитектуре Sparse Mixture-of-Experts (разреженная смесь экспертов, или MoE). Идея MoE в том, что модель содержит много специализированных «экспертных» подсетей, но при обработке каждого токена активирует только несколько из них. Это позволяет иметь огромную ёмкость модели при относительно небольших вычислительных затратах на инференс.
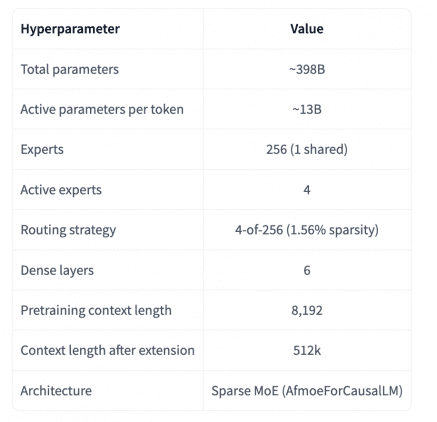
Коэффициент разреженности 1.56% — один из самых высоких среди публично известных MoE-моделей. Для сравнения: DeepSeek-V3 и MiniMax-M2 используют схему 8-из-256 (3.13% активаций), Qwen3-235B — 8-of-128 (6.25%). Llama 4 Maverick чуть разреженнее Trinity (0.78%), но остальные конкуренты активируют пропорционально больше параметров.
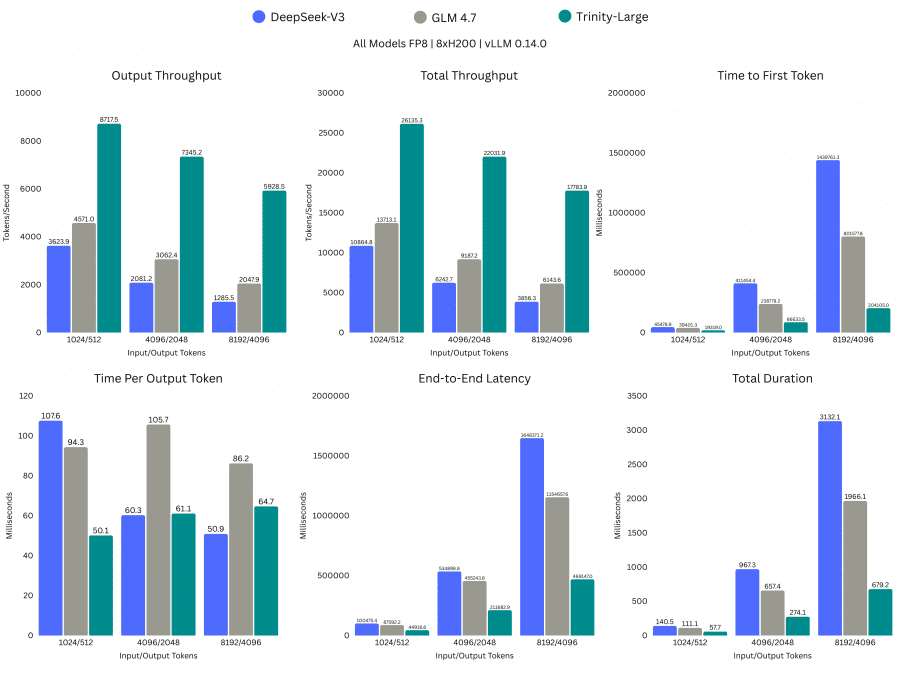
Высокая разреженность — это не просто архитектурное решение, а прямое следствие экономических ограничений команды. Чем меньше параметров активируется при каждом прогоне, тем быстрее работает инференс и тем быстрее идут прогоны при обучении с подкреплением. По данным Arcee, Trinity-Large работает примерно в 2–3 раза быстрее моделей сопоставимого размера на том же железе.
Механизм внимания
Ещё один источник скорости — нестандартная схема внимания. Вместо того чтобы каждый слой смотрел на весь контекст целиком, Trinity чередует локальные и глобальные слои в соотношении 3:1: три локальных слоя со sliding window attention (скользящим окном) и один глобальный слой без позиционных эмбеддингов. Локальные слои используют RoPE и обрабатывают только ближайший контекст в пределах окна, глобальные — видят всю последовательность целиком. Такое разделение позволяет модели эффективно работать с длинными контекстами без квадратичного роста вычислений. Кроме того, во всех слоях используется gated attention — элементарное умножение выхода внимания на сигмоид-гейт, что по данным технического отчёта снижает появление «attention sinks» (токенов, которые непропорционально притягивают всё внимание) и дополнительно стабилизирует обучение.
Интересная деталь из технического отчёта: модель обучалась на контексте 256k токенов, но на тесте MK-NIAH при длине 512k всё равно набрала 0.976 из 1.0. Это значит, что на реальных задачах она уверенно работает с контекстом вдвое длиннее того, на котором обучалась.
Оптимизатор и стабилизация обучения
Для скрытых слоёв вместо стандартного AdamW команда использовала оптимизатор Muon. Его главное преимущество — более высокий критический batch size и лучшая эффективность на единицу данных. Проще говоря, при том же количестве токенов Muon позволяет извлечь больше пользы из каждого шага обучения.
Чтобы при такой разреженности маршрутизация (routing) оставалась стабильной и эксперты не перегружались неравномерно, команда разработала несколько технических решений. Алгоритм SMEBU (Soft-clamped Momentum Expert Bias Updates) — новый метод балансировки нагрузки между экспертами: смещение каждого эксперта корректируется с учётом того, насколько он перегружен или недогружен, а функция tanh ограничивает величину коррекции. Кроме балансировки на уровне батча, используется отдельный loss-компонент на уровне отдельных последовательностей. Также применяется z-loss — регуляризатор, который не даёт logit’ам (сырым выходам последнего слоя до softmax) расти без ограничений во время обучения.
Отдельно команда разработала новый метод формирования батчей — RSDB (Random Sequential Document Buffer). Стандартный подход к упаковке последовательностей приводит к тому, что длинные документы попадают в несколько соседних батчей подряд, создавая дисбаланс доменов на уровне минибатча. RSDB решает это случайным перемешиванием токенов из разных документов при формировании каждой последовательности. По данным технического отчёта, включение RSDB снизило нестабильность градиентов в 12.8 раза — эксцесс (kurtosis) нормы градиента упал с 187 до 14.6.
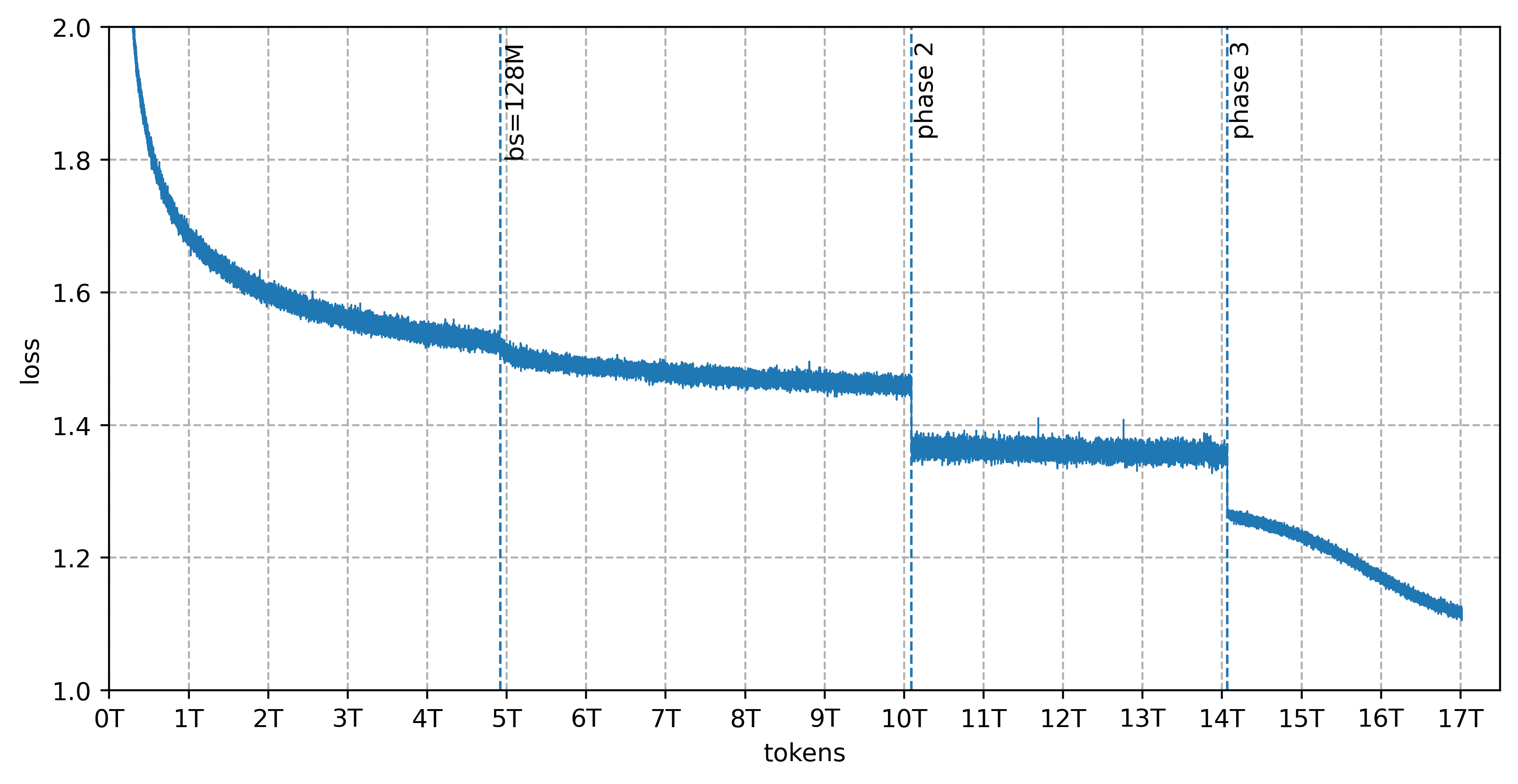
Данные для обучения
Предобучение прошло на 17 трлн токенов, подготовленных DatologyAI в три фазы: 13T → 4T → 3T токенов (всего датасет составлял 20T, Trinity Large обучалась на 17T из него пропорционально). Датасет охватывает 14 языков помимо английского: арабский, китайский, японский, испанский, немецкий, французский, итальянский, португальский, индонезийский, русский, вьетнамский, хинди, корейский и бенгальский — с упором на программирование, математику, естественные науки, задачи на рассуждение и перевод текста. Из 17 трлн токенов больше 8 трлн — синтетические данные: 6.5T синтетического веба, около 1T многоязычных текстов и около 800B токенов кода, сгенерированных с помощью различных методов перефразирования.
Post-training: от Preview к Thinking
Trinity-Large-Preview, вышедшая в январе 2026 года, была лёгкой instruct-моделью без рассуждения: она умела следовать инструкциям, писать, генерировать код, работать в агентных фреймворках. За два месяца на OpenRouter модель обслужила 3.37 трлн токенов и стала моделью №1 по использованию среди открытых моделей в США.
Trinity-Large-Thinking — это принципиально другой вариант обучения. Главное отличие: модель теперь использует расширенную цепочку рассуждений перед ответом, всё, что она «думает», оборачивается в теги <think>...</think>. Помимо этого, модель прошла обучение с подкреплением на агентных задачах: вызов инструментов, многоходовое планирование, следование инструкциям на длинных агентных циклах.
Важный технический момент: токены из блока <think> обязательно нужно сохранять в истории контекста при длинных диалогах. Если вырезать их из истории, чтобы сэкономить контекстное окно, модель теряет нить рассуждений и деградирует по качеству. Это ключевое требование при построении агентных систем на основе данной модели.
Бенчмарки
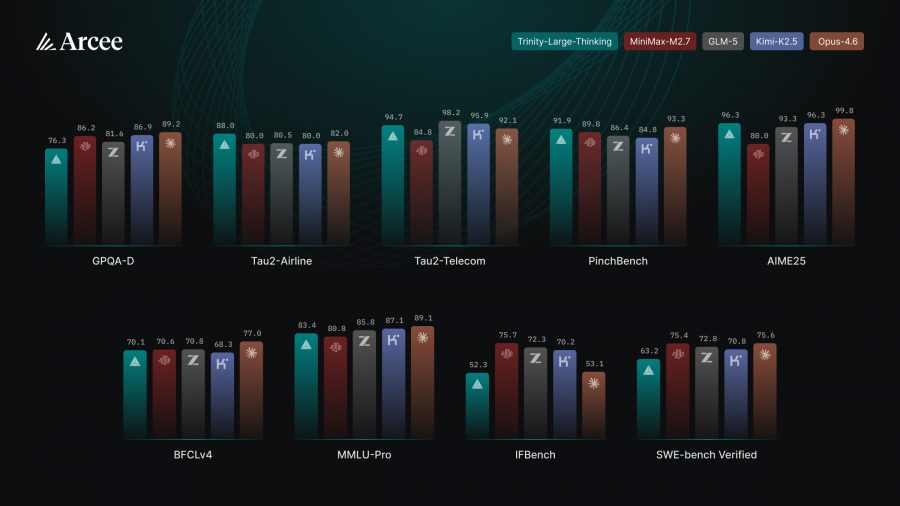
| Бенчмарк | Trinity-Large-Thinking | Opus-4.6 | GLM-5 | MiniMax-M2.7 | Kimi-K2.5 |
|---|---|---|---|---|---|
| IFBench | 52.3 | 53.1 | 72.3 | 75.7 | 70.2 |
| GPQA-Diamond | 76.3 | 89.2 | 81.6 | 86.2 | 86.9 |
| τ²-bench Airline | 88.0 | 82.0 | 80.5 | 80.0 | 80.0 |
| τ²-bench Telecom | 94.7 | 92.1 | 98.2 | 84.8 | 95.9 |
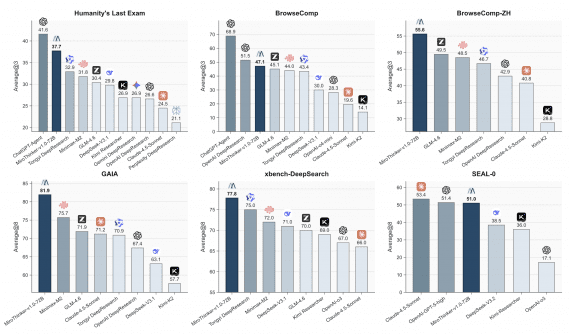
| PinchBench | 91.9 | 93.3 | 86.4 | 89.8 | 84.8 |
| AIME 2025 | 96.3 | 99.8 | 93.3 | 80.0 | 96.3 |
| BCFLv4 | 70.1 | 77.0 | 70.8 | 70.6 | 68.3 |
| MMLU-Pro | 83.4 | 89.1 | 85.8 | 80.8 | 87.1 |
| SWE-bench Verified* | 63.2 | 75.6 | 72.8 | 75.4 | 70.8 |
*Все модели тестировались в mini-swe-agent-v2
Что эти бенчмарки означают на практике: PinchBench от Kilo — это оценка поведения модели в реальных агентных рабочих нагрузках, максимально приближенных к тому, как используют AI-агентов разработчики через Cline и OpenClaw. τ²-bench (tau-squared bench) — бенчмарк для диалоговых агентов с двумя доменами: авиабилеты и телеком, где и агент, и пользователь могут вызывать инструменты и менять состояние общей среды. GPQA-Diamond — вопросы экспертного уровня по физике, химии и биологии. AIME 2025 — задачи американской математической олимпиады. SWE-bench Verified — задачи по автоматическому исправлению реальных GitHub issues в open-source проектах.
Trinity-Large-Thinking занимает второе место по PinchBench (91.9 против 93.3 у Opus-4.6) и лидирует среди всех протестированных моделей на τ²-bench в домене Airline (88.0). Это нетривиальный результат для полностью открытой модели, которая при этом стоит $0.90 за миллион выходных токенов — примерно в 28 раз дешевле Opus-4.6.
Слабое место Trinity — бенчмарки на следование инструкциям (IFBench, 52.3) и научные рассуждения (GPQA-Diamond, 76.3), где модель заметно отстаёт от конкурентов. SWE-bench (63.2) также ниже большинства конкурентов — что сам Arcee признаёт: задача стать лучшей в мире кодовой моделью не ставилась как приоритет.
Цена и доступность
Цена инференса через API Arcee — $0.90 за миллион выходных токенов. Для сравнения: ближайший конкурент по агентным задачам, Claude Opus-4.6, стоит $25 за миллион выходных токенов — то есть Trinity обходится примерно в 28 раз дешевле при сопоставимом уровне качества на агентных бенчмарках. Для задач, где модель генерирует длинные рассуждения и вызывает инструменты по многу раз за сессию, это принципиальная разница: агентный цикл из 100 000 выходных токенов будет стоить $0.09 на Trinity против $2.50 на Opus.
Trinity-Large-Thinking доступна через несколько платформ: API Arcee, OpenRouter и DigitalOcean Agentic Inference Cloud. Веса в формате BF16 опубликованы на Hugging Face, также доступны квантизированные варианты FP8 и W4A16 (INT4 веса с 16-битными активациями). Для развёртывания поддерживается vLLM начиная с версии 0.11.1, а также трансформерная библиотека Hugging Face с параметром trust_remote_code=True.
Заключение
На сегодняшний день Trinity-Large-Thinking — вероятно, самая мощная полностью открытая reasoning-модель, созданная за пределами Китая. Китайские лаборатории, которые раньше задавали темп в гонке открытых весов, начали смещаться в сторону закрытых продуктов: только за последнюю неделю марта 2026 года Alibaba выпустила три закрытые модели подряд — без весов, только как API. Флагманская Qwen3.5-Omni теперь доступна исключительно как облачный сервис, хотя именно открытость предыдущих версий Qwen привлекла более 290 000 разработчиков и породила свыше 113 000 производных моделей. На этом фоне ставка Arcee на полностью открытые веса выглядит осознанным и своевременным решением: пока главные поставщики открытых моделей начинают закрываться, Trinity заполняет образующуюся пустоту — и делает это с моделью, которая по агентным задачам вплотную приближается к лучшим закрытым аналогам.