Исследователи разработали интерфейс мозг-компьютер для синтеза речи
9 марта 2023
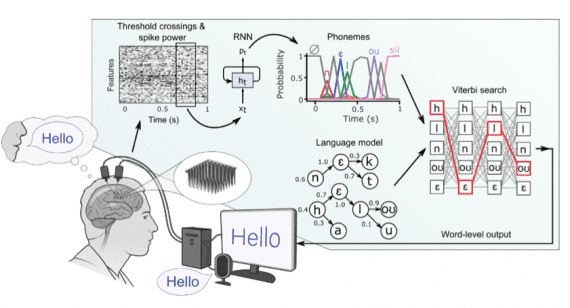
Исследователи разработали интерфейс мозг-компьютер для синтеза речи
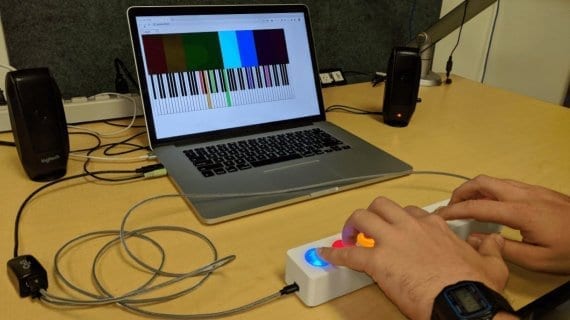
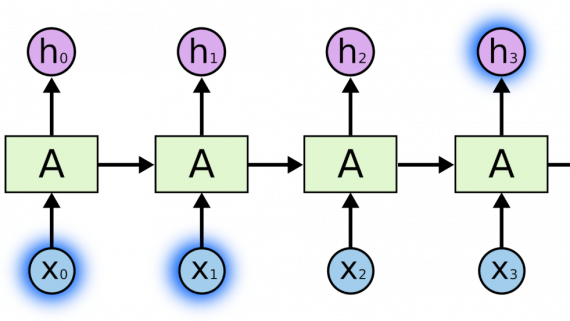
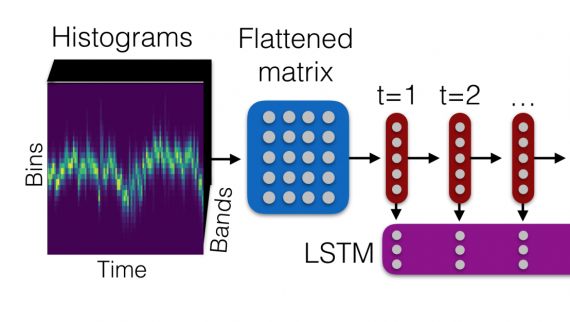
Исследователи разработали интерфейс мозг-компьютер для синтеза речи из сигналов, захваченных в мозге пациента и обработанных рекуррентной нейросетью. Прототип системы может декодировать речь со скоростью 62 слова в минуту, что в…