Google Brain ведет разработку ИИ, который предсказывает изменения в коде исходя из прошлых изменений. Команда Google Brain выбрала неявную модель, которая по результатам тестов обеспечивает наилучшую общую производительность и масштабируемость из всех протестированных на данный момент моделей.
Модель может быть адаптирована для улучшения систем автодополнения, которые игнорируют истории редактирования, и для прогнозирования поисковых запросов разработчика (например, для stackoverflow.com), учитывая последние изменения в коде.
Принцип работы алгоритма
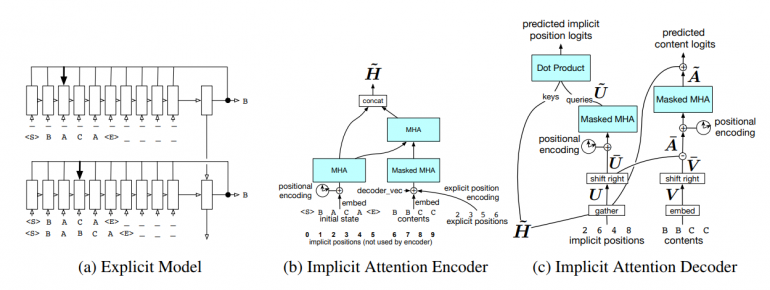
Сначала было разработано два представления данных с правками кода: явное и неявное. Явное представление содержит двумерную сетку токенов, а неявное — содержит последовательность правок:

Далее для каждого из двух представлений разработали свою модель, которая должна предсказывать следующую правку. Для явного представления используется двухслойная LSTM-сеть, а для скрытого представления модель разбита на encoder и decoder. Encoder представляет собой слой LSTM, а декодер — нестандартную модель, которая на выходе генерирует пары: содержимое и положение в коде. Подробное описание архитектуры модели — в оригинальной статье.
Результаты
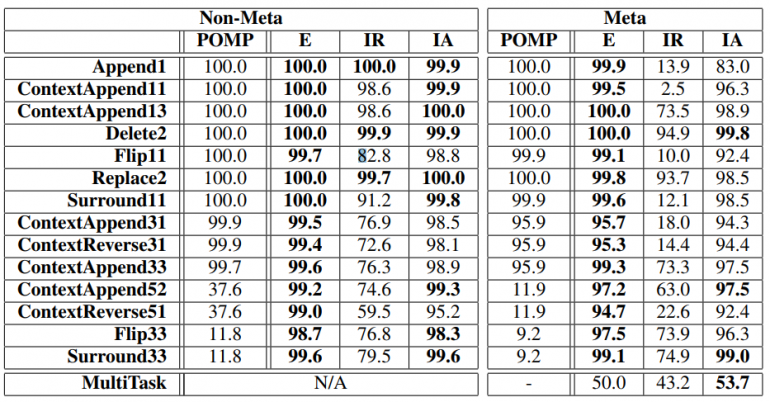
Для оценки моделей, исследователи разработали набор упрощенных синтетических датасетов, которые включают в себя те виды правок, которые встречаются и в обычном коде, чтобы обеспечить более четкую интерпретацию результатов. Кроме того, они собрали датасет последовательностей правок из снимков базы кода Google, содержащих восемь миллионов правок от 5700 разработчиков.
Эксперименты на синтетических данных проводились по разным задачам редактирования: вставка, удаление, перемещение и т.д.
Точность рассчитывалась для следующих моделей: E — модель с явным представлением, IR — модель с неявным представлением, IA — улучшенная модель с неявным представлением, POMP — можно интерпретировать как некий показатель сложности обобщения задачи (чем ниже значение — тем труднее обобщается задача):
На реальных данных, собранных с внутренней среды разработки Google Clients in the Cloud, accuracy на тесте модели E составил 51%, на IR — 55,5%, а на IA- 61,1%.
Модель IA обеспечивает хороший компромисс: достигает лучшей точности и имеет меньше проблем с ограничениями памяти, чем явная модель. Исследования этой задачи будут продолжены с упором на эту модель.